
Flink名词介绍
一、常用名词
1、Slot:处理槽,一般为服务器核数*4,平分服务器内存
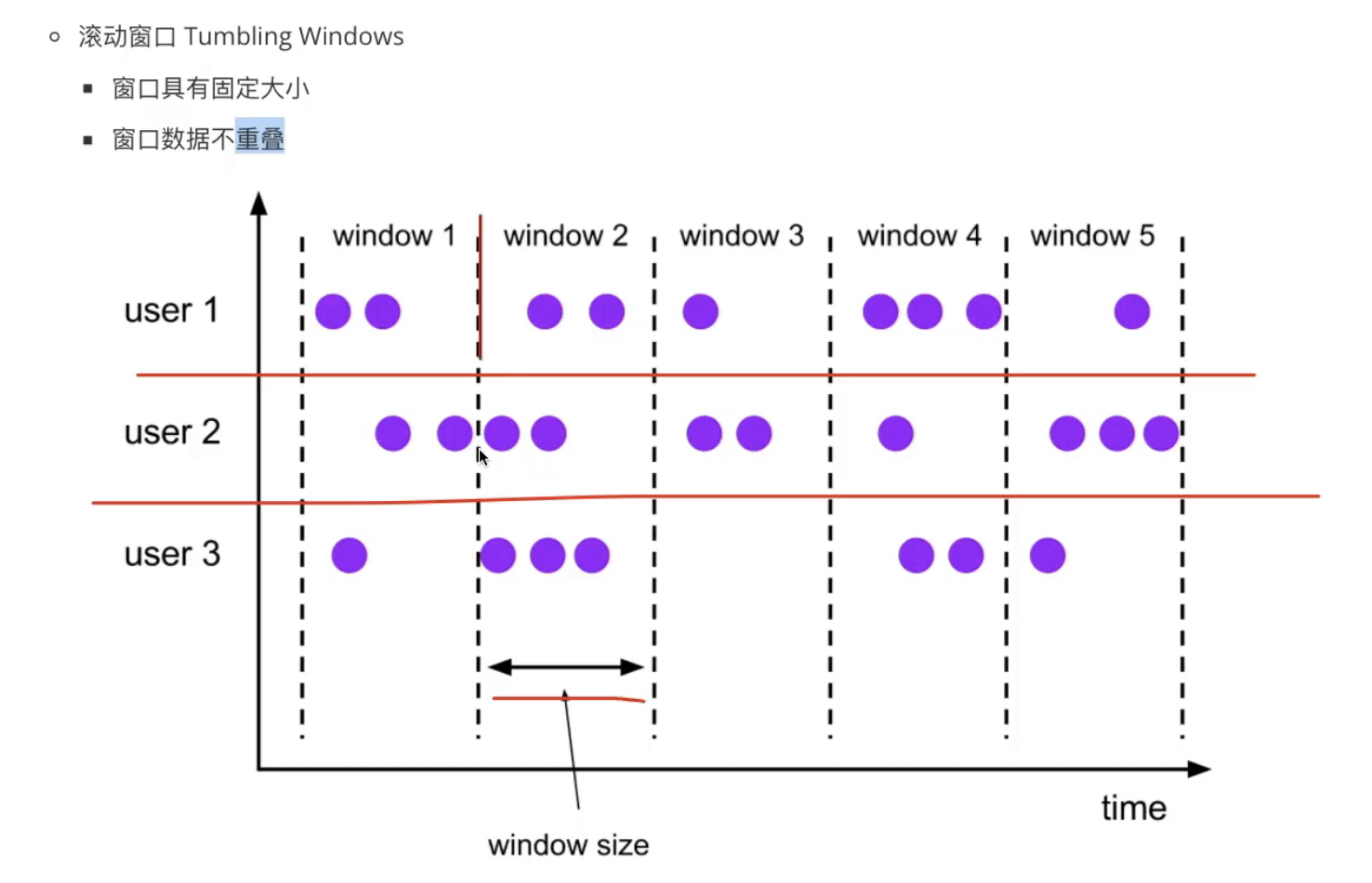
2、Window:时间窗口
滚动窗口(Tumbling Window)将事件拆分成固定长度,窗口之间不重叠,窗口长度固定
例:每10s统计过去10s订单数据
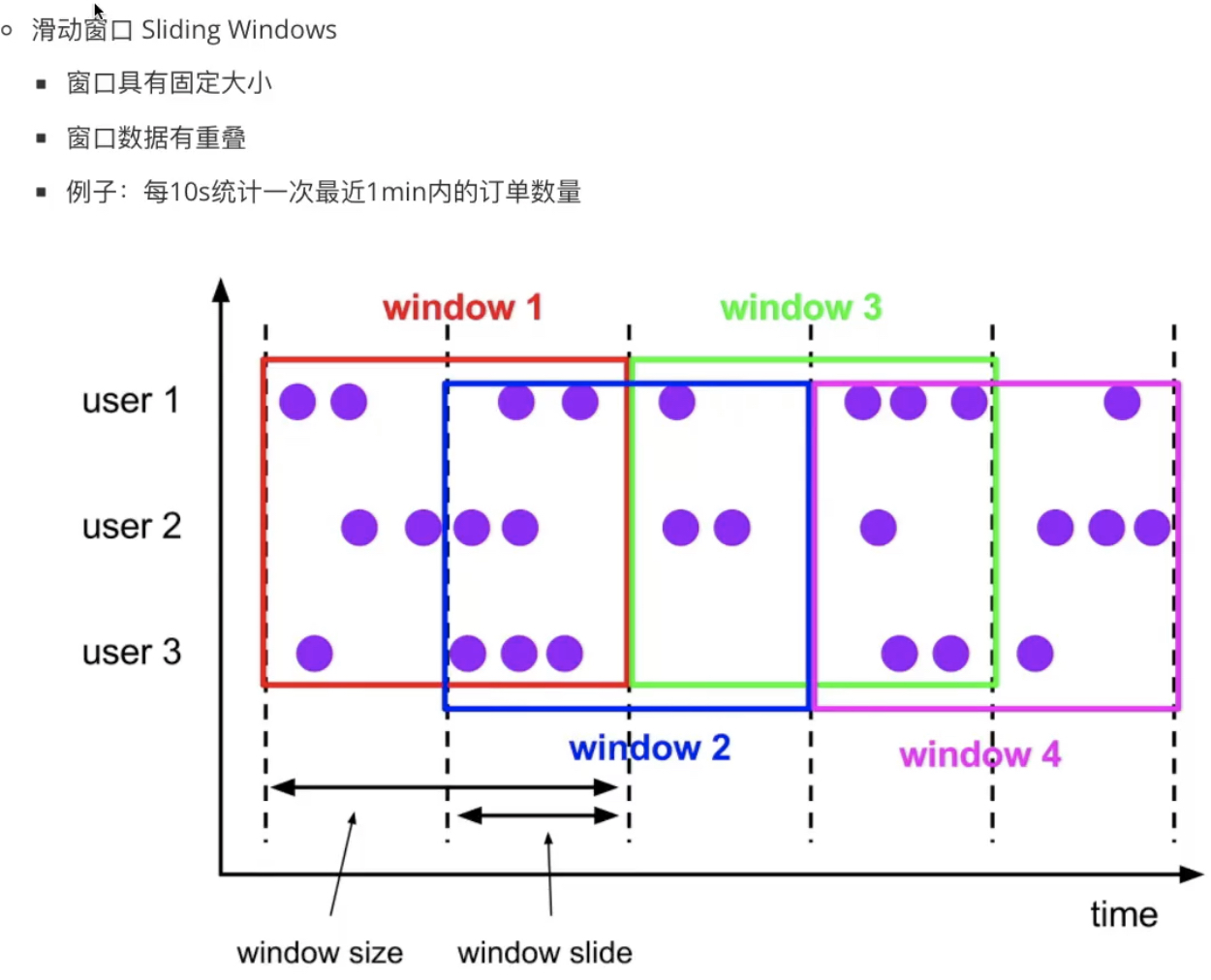
滑动窗口(Sliding Window)按照滑动步长拆分成固定长度,窗口长度固定。根据指定步长(Slide)向前滑动,步长小于窗口则窗口间重叠。
例:每10s统计过去10分钟 订单数据
会话窗口(Session Window)两个窗口之间有一个间隙(Session Gap),大于间隙没收到消息,则该窗口关闭,窗口不重叠
数量窗口(Count Windows)按照一定的数据量作为窗口统计
3、Watermark:水印。嵌入时间轴上,用于判断事件时间窗口内所有数据均已到达引擎的时间戳,既可以流处理引擎嵌入,也可以消息系统端嵌入
语义--小于水印标记时间的事件不再出现,为事件的推进器
水印分类:
完美水印(Perfect Watermark)表示早于水印标记事件时间戳的记录均已到达
启发式水印(Heuristic Watermark)尽可能确定事件戳的估计,用在分布式系统中,代价较低。事件迟到后不记录。可用迟到生存期解决
水印迟到:启发式水印记录9迟到后不记录,在完美水印时等待事件9到了后再处理
水印早到:启发式水印入果推进太快,记录9不能计入本窗口聚合结果中,引擎应提供事后更正机制
水印方式:
递增式水印生成器(Assigner with ascending timestamp):生成完美水印,用于顺序的无界数据集。
周期性水印生成器(Periodic Watermark):根据事件和处理时间周期性触发水印生成器,水印之间间隔不固定
间歇性水印生成器(Pubctuated Watermark):观察到事件后,会计算某个条件来决定是否发送水印。如遇到业务流程结束标识后发送水印
4、Trigger:触发器。决定在窗口的什么时间点启动应用程序定义的处理任务。水印迟到会拉长窗口生存期,水印早到会导致处理结果不准确,触发器就是解决水印早晚到而被引入
Flink提供几类内置触发器
(1)EventTimeTrigger:根据事件时间轴上的水印触发
(2)ProcessingTineTrigger:根据处理时间触发
(3)CountTrigger:根据窗口内的元素数据触发
(4)ContinuosEventTimeTrigger:将事件时间轴分成等间隔的窗格,在每个窗格内判断水印来决定是否触发
(5)ContinuosProcessingTimeTrigger:将处理时间轴分成等间隔的窗格,每个窗格内触发一次,根据条件判断是否调用窗口函数
(6)DeltaTrigger:根据某种特征是否超过指定阈值决定是否触发
(7)PurgingTrigger:将其它触发器转换成清除触发器,等于销毁窗口
触发器原型中包含4类触发机制,基于事件驱动
(1)onElement:窗口每收到一个元素调用一次该方法,返回结果决定是否触发算子函数
(2)onProcessingTime:根据注册的处理时间定时器触发,定时时间由参数time设定
(3)onEventTime:根据注册的事件时间定时器触发,定时时间由参数time设定
(4)onMerge:两个窗口合并时触发
(5)clear:资源清除接口
前三类触发机制的结果有四种情况,忽略、触发、清除、触发并清除
4(1)、清除器Evictor
Flink内置三种清除器
(1)CountEvictor:保持窗口内元素数据为预定值
(2)DeltaEvictor:根据元素之间的关系,清除超过指定法制的元素
(3)TimeEvictor:根据窗口内元素的时间戳,决定清除哪些元素
在触发器出发后,窗口函数执行前或执行后清除窗口内元素,有以下两个方法
触发器之后,窗口函数之前
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
触发器之后,窗口函数之后
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
5、When:迟到生存期。完美水印事件不会迟到,所以只会发生于启发式水印。和水印一样,都是聚合计算的触发信号。默认值为0
dataStream.keyBy(0).window(TumplingProcessingTimeWindows.of(Time.seconds(5))).allowedLateness(Time.seconds(10))
注:生存期是事件时间,销毁窗口是处理时间
6、How:累加模式,有三个窗格,每个窗格累加值为7、7、8
discarding:丢弃 ,启发式水印在窗口内产生三个聚合结果,每个窗格计算结果和其它窗格无关,7、7、8
accumulating:累加,每个窗格累加相邻窗格的计算结果,7、14、22
retracting:撤回,在累加模式基础上加撤回。撤回-7代表上个窗格结果,14截止当前总的聚合结果7、-7和14、-14和22
7、exactly-once语义:一致性
at-most-once:尽可能正确,系统发生故障恢复后,聚合结果可能出错
at-least-once:系统发生故障恢复后,不会漏掉事件,但可能重复计算某些事件,用在实时性较高,准确性要求不高的场合
exactly-once:系统发生故障恢复后,聚合结果和没发生故障时一致,数据准确。加大高吞吐和低延迟难度,采用异步屏障快照技术实现
8、ABS(Asynchronous Barrier Snapshot):异步屏障快照,实现exactly-once语义的核心机制
Checkpoint:检查点,关系型数据库并不会把提交的事务写入磁盘,而是先写入缓存和日志。为了提高故障恢复速度,数据库仅需恢复某个检查点之后的未写入磁盘的事务
启动检查点需要具备以下条件
(1)支持时空穿梭的数据源,如Kafka、分布式文件系统
(2)可持久化的外部存储,如分布式文件系统
检查点默认关闭,启动需要配置以下参数
(1)一致性级别,即exactly-once或at-least-once
(2)检查点超时时间,即检查点在多长时间完成
(3)两个检查点之间最小时间间隔
(4)并发检查点数量。默认情况下,在一个检查点还在处理快照逻辑时,Flink不会触发另一个检查点,以确保低延迟
(5)持久化检查点到外部存储
(6)快照失败后任务是继续执行还是失败
参考代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//参数为生成checkpoint的时间,以及CheckpointingMode,默认为EXACTLY_ONCE,一般采用默认就可以,如果任务有超低延时需求,可以使用至少一次
env.enableCheckpointing(1000, CheckpointingMode.AT_LEAST_ONCE);
//设置检查点模式也可以使用下面方式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
//设置超时时间,超时时间是说,这个检查点设置了,但是过去500ms还没有完成就认为这个检查点超时了,然后把这个检查点终止,也就是不再使用这个检查点了
env.getCheckpointConfig().setCheckpointTimeout(500);
/**设置检查点尝试之间的最小间隔。此设置定义检查点协调器在可能触发另一个检查点(相对于最大并发检查点数)后多久可以触发另一个检查点
* 比如下面的设置,下一个检查点将在上一个检查点完成后,不超过5s内启动
* 这个参数跟检查点生成的间隔时间是有点冲突的,这个参数不考虑上面提到的检查点持续时间和检查点间隔。或者说设置下面的参数以后,检查点自动就变成5s了,
* 如果觉得5s不够可以再将间隔设置的大一点,但是不能小于5s了
* 设置检查点的interval和设置检查点之间的间隔时间有啥不同呢?
* interval是物理时间的间隔,即时间只要过去1s了,就会生成一个检查点。但是设置检查点之间的间隔是说检查点完成1s了就会设置间隔,这个是跟检查点完成时间相关的
* 比如存储检查点的系统比较慢,完成一个检查点平均10s,然后下面检查点之间的间隔设置为5s,那么两个检查点生成的时间间隔就是15s
* 再简单点说,interval设置的是两个检查点生成时刻的间隔,而下面参数设置的是第一个检查点结束和第二个检查点创建(还没有结束)之间的间隔
**/
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000);
//设置检查点最大并发数.比如设置为1,表示只能有一个检查点,当这个检查点完成以后才有可能产生下一个检查点。这也是默认参数。如果定义了上面的设置,则不能再定义这条设置项
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//设置外部检查点。可以将检查点的元数据信息定期写入外部系统,这样当job失败时,检查点不会被清除。这样如果job失败,可以从检查点恢复job。这条很重要,下面一节会详细说明
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//检查点和保存点都可以用于容灾,这个配置是说如果有一个时间更近的保存点,我也不用,而更加愿意使用检查点进行容灾
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
//设置使用非对齐检查点。它可以极大减少背压情况下检查点的时间,但是只有在精确一次的检查点并且允许的最大检查点并发数量为1的情况下才能使用
env.getCheckpointConfig().enableUnalignedCheckpoints();Snapshot:快照,数据的一个拷贝,有两种实现方式,写时拷贝(COW)用作读密集型、写重定向(ROW)用作写密集型。
9、算子函数
(1)Map:做映射关系
Map:对整个DataStream做一对一映射,每一个元素产出一个元素
FlatMap:对整个DataStream做一对多映射,一个元素可以产出多个元素
(2)KeyBy:对输入DataStream分区,即相同的key分到同一个分区
stream.keyBy("key")
(3)Reduce:根据多个元素生成一个元素。算子内会保留上一次Reduce结果,新来元素则和上一次结果相加
stream.reduce( _ + _ )
(4)聚合函数
stream.sum("key") 返回值
stream.min("key")
stream.max("key")
stream.minBy("key") 返回元素
stream.maxBy("key")
(5)窗口函数:用于对每个key的元素开窗,windowAll对全体元素开窗
(5.1)滚动窗口
事件时间为5s滚动窗口:
dataStream.keyBy(0).window(TumplingEventTimeWindows.of(Time.seconds(5)))
处理时间为5s滚动窗口
dataStream.keyBy(0).window(TumplingProcessingTimeWindows.of(Time.seconds(5)))
带起点偏移量的事件时间长度为1h的滚动窗口
dataStream.keyBy(0).window(TumplingEventTimeWindows.of(Time.hours(1),Time.Minutes(15)))
全体元素开窗
dataStream.windowAll(TumplingEventTimeWindows.of(Time.seconds(5)))
(5.2)滑动窗口,按照滑动步长将时间拆分成固定长度的窗口,滑动步长小于窗口长度的话相邻窗口间会重叠
事件时间滑动窗口,窗口长度10s,滑动步长5s
dataStream.keyBy(0).window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
处理时间滑动窗口,窗口长度10s,滑动步长5s
dataStream.keyBy(0).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
带起点偏移量的处理时间滑动窗口,窗口长度12h,滑动步长1h,对齐偏移量8h
dataStream.keyBy(0).window(SlidingProcessingTimeWindows.of(Time.hours(10),Time.hours(1),Time.hours(8)))
(5.3)会话窗口,根据相邻元素之间间隔确定窗口边界,分固定时间间隔(Static Gap)和动态时间间隔(Dynamic Gap)
事件时间-固定时间间隔10s的会话窗口
dataStream.keyBy(0).window(EventTimeSessionWindows.withGap(Time.minutes(10)))
事件时间-动态时间间隔的会话窗口
dataStream.keyBy(0).window(EventTimeSessionWindows.withDynamicGap(
new SessionWindowTimeGapExtractor[Event]{
override def extract(element : Event):Long={
//根据事件特征确定会话窗口间隔
}
}
))
处理时间-固定时间间隔10s的会话窗口
dataStream.keyBy(0).window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
处理时间-动态时间间隔的会话窗口
dataStream.keyBy(0).window(DynamicProcessingTimeSessionWindows.withDynamicGap(
new SessionWindowTimeGapExtractor[Event]{
override def extract(element : Event):Long={
//根据事件特征确定会话窗口间隔
}
}
))
(5.4)全局窗口,将相同key的元素聚在一起,无起点和重点,必须使用自定义触发器
dataStream.keyBy(0).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
(6)连接
窗口连接join:两个数据源相同窗口区间内组合,可以是事件时间或处理时间。组合方式由apply定义
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream.join(greenStream)
.where(elem => /* select key */)
.equalTo(elem => /* select key */)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply { (e1, e2) => e1 + "," + e2 }
间隔连接:仅事件时间轴上,被连接数据源的每个元素为顶点画三角,连接数据源左偏移和右偏移
val orangeStream: DataStream[Integer] = ...
val greenStream: DataStream[Integer] = ...
orangeStream.keyBy(elem => /* select key */)
.intervalJoin(greenStream.keyBy(elem => /* select key */))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process(new ProcessJoinFunction[Integer, Integer, String] {
override def processElement(left: Integer, right: Integer, ctx:
ProcessJoinFunction[Integer, Integer, String]#Context, out: Collector[String]):
Unit = { out.collect(left + "," + right); }
});
});
10、数据分区,可有效降低网络传输
未使用分区时,Join节点每个实例都需要聚合来自所有Source节点的数据。分区后Source和Join节点时一一连接的
(1)自定义分区(Custom partition),根据指定key进行分区
dataStream.partitionCustom(partitioner,"key");
(2)均匀分布分区(Random Partition)数据均匀分布给下一节点
dataStream.shuffle()
(3)负载均衡分区(Rebalance Partition)根据轮训调度算法将数据均匀分布给下一级节点。某些物理拓扑下是最有效的分区方式
dataStream.rebalance()
(4)可伸缩分区(Rescale Partition)根据资源使用情况动态调节同一作业的数据分布,根据实例资源调节数据分布,让数据尽可能在同一Slot内流转
dataStream.rescale()
(5)广播分区(Broadcasting partiotion)每一个元素都被广播到下一级节点
dataStream.broadcast()
11、资源共享:将多个任务链接成一个任务,降低线程上下文切换,提高吞吐降低延迟
(1)创建链,后两个map会链接一起
dataStream.map(...).map(...).startNewChain().map(...)
(2)关闭作业链接优化,任意两个算子可不共享线程
dataStream.map(...).disableChaining()
(3)Slot共享组
同一组所有任务在同一个Slot运行,用来隔离非本组实例
dataStream.map(...).slotSharingGroup("name")
12、连接器(Connector):Source和Sink节点连接外部数据员的组件称为连接器。
注:Flink内置连接器实现代码集成在源码中,但并没有被编译近二进制程序包中
编号[1]exactly once [2]at most once [3]at least once
Source Source一致性保障
Apache Kafka 1
AWS Kinesis Streams 1
RebbitMQ 1(v1.0)
Twitter Streaming API 1
Collections 2
File 2
Sockets 1
============================================================
Sink Sink一致性保障
HDFS Rolling Sink 1
Elasticsearch 3
Kafka Producer 3
Cassandra Sink 1\3
AWS Kinesis Streams 3
File SInk 3
Socket Sink 3
Standard Output 3
Redis Sink 3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号