
OLTP与OLAP
OLTP(on-line transaction processing)翻译为联机事务处理, OLAP(On-Line Analytical Processing)翻译为联机分析处理,从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询。
再从应用上来看看OLTP与OLAP的区别。
OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP。
当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了。
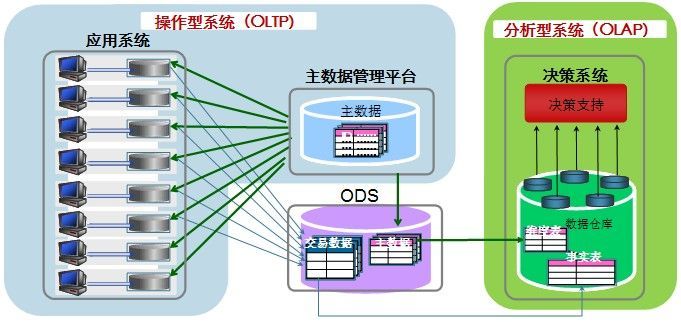
因为OLTP所产生的业务数据分散在不同的业务系统中,而OLAP往往需要将不同的业务数据集中到一起进行统一综合的分析,这时候就需要根据业务分析需求做对应的数据清洗后存储在数据仓库中,然后由数据仓库来统一提供OLAP分析。所以我们常说OLTP是数据库的应用,OLAP是数据仓库的应用,下面用一张图来简要对比。

所以OLAP和OLTP之间的关系可以认为OLAP是依赖于OLTP的,因为OLAP分析的数据都是由OLTP所产生的,也可以看作OLAP是OLTP的一种延展,一个让OLTP产生的数据发现价值的过程。
这里我们在多介绍一下OLAP
OLAP分析的分类:ROLAP与MOLAP
OLAP分析分为关系型联机分析处理(ROLAP)、多维联机分析处理(MOLAP)两种,他们的设计理念以及解决场景不一样,各有优劣。
以ROLAP为代表的有传统关系型数据库、MPP分布式数据库以及基于Hadoop的Spark/Impala,特点是能同时连接明细数据和汇总数据,实时根据用户提出的需求对数据进行计算后返回给用户,所以用户使用相对比较灵活,可以随意选择维度组合来进行实时计算。
正因为采用的实时计算技术,所以ROLAP的缺点也比较明显——当计算的数据量达到一定级别或并发数达到一定级别的时候,一定会出现性能问题(就好比如果领导一次性给你安排非常多的工作,你一个人是无法马上将所有事情做完答复领导的)。
以传统关系型数据库为代表的如Teradata、Oracle等,由于传统架构可扩展性较差,所以对硬件的要求非常高,当计算的数据量达到千万,亿级别时,数据库的计算就会出现延时,使得用户不能及时得到响应,更别提高并发了。
MPP分布式数据库(GreenPlum/GBase/Vertica)则解决了一部分可扩展性问题,对硬件设备的要求也稍稍下降了(还是有一定的硬件要求),在支持的数据体量(GB,TB级别)上有了很大的提升。当集群有几百、上千节点时,会出现性能瓶颈(增加再多节点,性能提升也不会很明显),扩容成本同样不菲。
基于Hadoop的Spark/Impala,则对部署硬件的要求很低(常见服务器即可,只是其主要依靠内存计算来缩短响应时间,所以对内存要求较高),在节点扩容上成本上相对较低,但当计算量达到一定级别或并发达到一定级别后,无法秒级响应,且容易出现内存溢出等问题。
以MOLAP分析为代表的有Cognos,SSAS,Kylin等,设计理念是预先将客户的需求计算好以结果的形式存下来(比如一张表分为10个维度,5个度量,那客户提出的需求会有2的10次方种可能,然后将这么多种可能提前计算好存储下来),当客户提出需求后,找到对应结果返回即可(好比你提前一天将领导明天会布置的任务先做好,明天领导布置对应任务后你直接告知他已做好),特点是当命中需求后返回非常快(所以MOLAP非常适合常见固定的分析场景),同等资源下支持的数据体量更大,支持的并发更多,不足则是当表的维度越多,越复杂,其所需的磁盘存储空间则越大,构建cube也需要一定的时间。
Cognos和SSAS是早期比较传统的产品,Cognos限制了Cube的大小(即限制了表的复杂度大小),而SSAS的cube则受限于单机的容量,即需要专用的服务器来进行存储。
Apache Kylin则是目前技术较为先进的一款成熟产品,也是第一个由中国人贡献给Apache社区的顶级开源项目,它基于hadoop框架,Cube以分片的形式存储在不同节点上,Cube大小不受服务器配置限制,所以具备很好的可扩展性和对服务器要求很低,在扩容成本上就非常低廉。另外为了控制整体Cube的大小,Kylin给客户提供了建模的能力,即用户可以根据自身需要,对模型种的维度以及维度组合进行预先的构建,把一些不需要的维度和组合筛选掉,从而达到降低维度的目的,减少磁盘空间的占用。
Kylin的企业版产品,即Kyligence的产品,除了在性能、功能上做了很多优化之外,稳定性上也做了很大提升,还提供了智能建模功能,在满足用户需求的前提下,很大程度上减小了磁盘空间的浪费。
综上而言,从可扩展性上看:Kylin=Impala/Spark>MPP数据库>传统数据库;从对硬件要求上看,传统数据库>MPP数据库>Impala/Spark>=Kylin;从响应效率上来看,不同的数据量、并发数,响应效率差别不一,但可以确定的是,要计算的数据量越大,并发的用户数越多,同等资源情况下预计算的响应效率会越发明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号