
pyspider 爬虫教程(一):HTML 和 CSS 选择器
虽然以前写过 如何抓取WEB页面 和 如何从 WEB 页面中提取信息。但是感觉还是需要一篇 step by step 的教程,不然没有一个总体的认识。不过,没想到这个教程居然会变成一篇译文,在这个爬虫教程系列文章中,会以实际的例子,由浅入深讨论爬取(抓取和解析)的一些关键问题。
在 教程一 中,我们将要爬取的网站是豆瓣电影:http://movie.douban.com/
你可以在: http://demo.pyspider.org/debug/tutorial_douban_movie 获得完整的代码,和进行测试。
开始之前
由于教程是基于 pyspider 的,你可以安装一个 pyspider(Quickstart,也可以直接使用 pyspider 的 demo 环境: http://demo.pyspider.org/。
你还应该至少对万维网是什么有一个简单的认识:
所以,爬网页实际上就是:
- 找到包含我们需要的信息的网址(URL)列表
- 通过 HTTP 协议把页面下载回来
- 从页面的 HTML 中解析出需要的信息
- 找到更多这个的 URL,回到 2 继续
选取一个开始网址
既然我们要爬所有的电影,首先我们需要抓一个电影列表,一个好的列表应该:
- 包含足够多的电影的 URL
- 通过翻页,可以遍历到所有的电影
- 一个按照更新时间排序的列表,可以更快抓到最新更新的电影
我们在 http://movie.douban.com/ 扫了一遍,发现并没有一个列表能包含所有电影,只能退而求其次,通过抓取分类下的所有的标签列表页,来遍历所有的电影: http://movie.douban.com/tag/
创建一个项目
在 pyspider 的 dashboard 的右下角,点击 "Create" 按钮
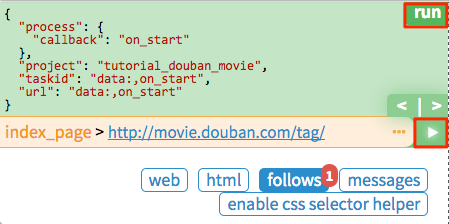
替换 on_start 函数的 self.crawl 的 URL:
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
self.crawl告诉 pyspider 抓取指定页面,然后使用callback函数对结果进行解析。@every修饰器,表示on_start每天会执行一次,这样就能抓到最新的电影了。
点击绿色的 run 执行,你会看到 follows 上面有一个红色的 1,切换到 follows 面板,点击绿色的播放按钮:
Tag 列表页
在 tag 列表页 中,我们需要提取出所有的 电影列表页 的 URL。你可能已经发现了,sample handler 已经提取了非常多大的 URL,所有,一种可行的提取列表页 URL 的方法就是用正则从中过滤出来:
import re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
- 由于 电影列表页和 tag列表页长的并不一样,在这里新建了一个
callback为self.list_page@config(age=10 * 24 * 60 * 60)在这表示我们认为 10 天内页面有效,不会再次进行更新抓取
由于 pyspider 是纯 Python 环境,你可以使用 Python 强大的内置库,或者你熟悉的第三方库对页面进行解析。不过更推荐使用 CSS选择器。
电影列表页
再次点击 run 让我们进入一个电影列表页(list_page)。在这个页面中我们需要提取:
- 电影的链接,例如,http://movie.douban.com/subject/1292052/
- 下一页的链接,用来翻页
CSS选择器
CSS选择器,顾名思义,是 CSS 用来定位需要设置样式的元素 所使用的表达式。既然前端程序员都使用 CSS选择器 为页面上的不同元素设置样式,我们也可以通过它定位需要的元素。你可以在 CSS 选择器参考手册 这里学习更多的 CSS选择器 语法。
在 pyspider 中,内置了 response.doc 的 PyQuery 对象,让你可以使用类似 jQuery 的语法操作 DOM 元素。你可以在 PyQuery 的页面上找到完整的文档。
CSS Selector Helper
在 pyspider 中,还内置了一个 CSS Selector Helper,当你点击页面上的元素的时候,可以帮你生成它的 CSS选择器 表达式。你可以点击 Enable CSS selector helper 按钮,然后切换到 web 页面:
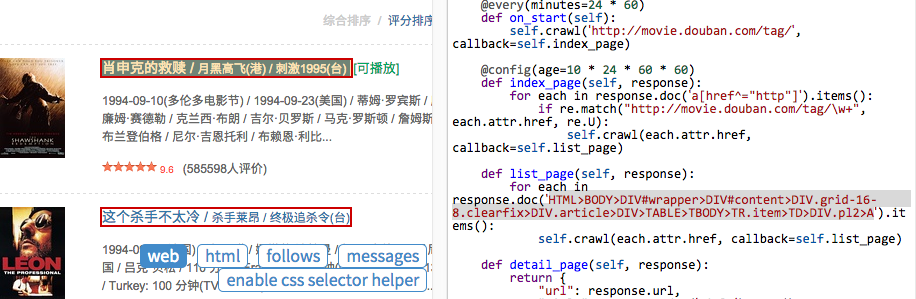
开启后,鼠标放在元素上,会被黄色高亮,点击后,所有拥有相同 CSS选择器 表达式的元素会被高亮。表达式会被插入到 python 代码当前光标位置。创建下面的代码,将光标停留在单引号中间:
def list_page(self, response):
for each in response.doc('').items():
点击一个电影的链接,CSS选择器 表达式将会插入到你的代码中,如此重复,插入翻页的链接:
def list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
- 翻页是一个到自己的
callback回调
电影详情页
再次点击 run,follow 到详情页。使用 css selector helper 分别添加电影标题,打分和导演:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
注意,你会发现 css selector helper 并不是总是能提取到合适的 CSS选择器 表达式。你可以在 Chrome Dev Tools 的帮助下,写一个合适的表达式:
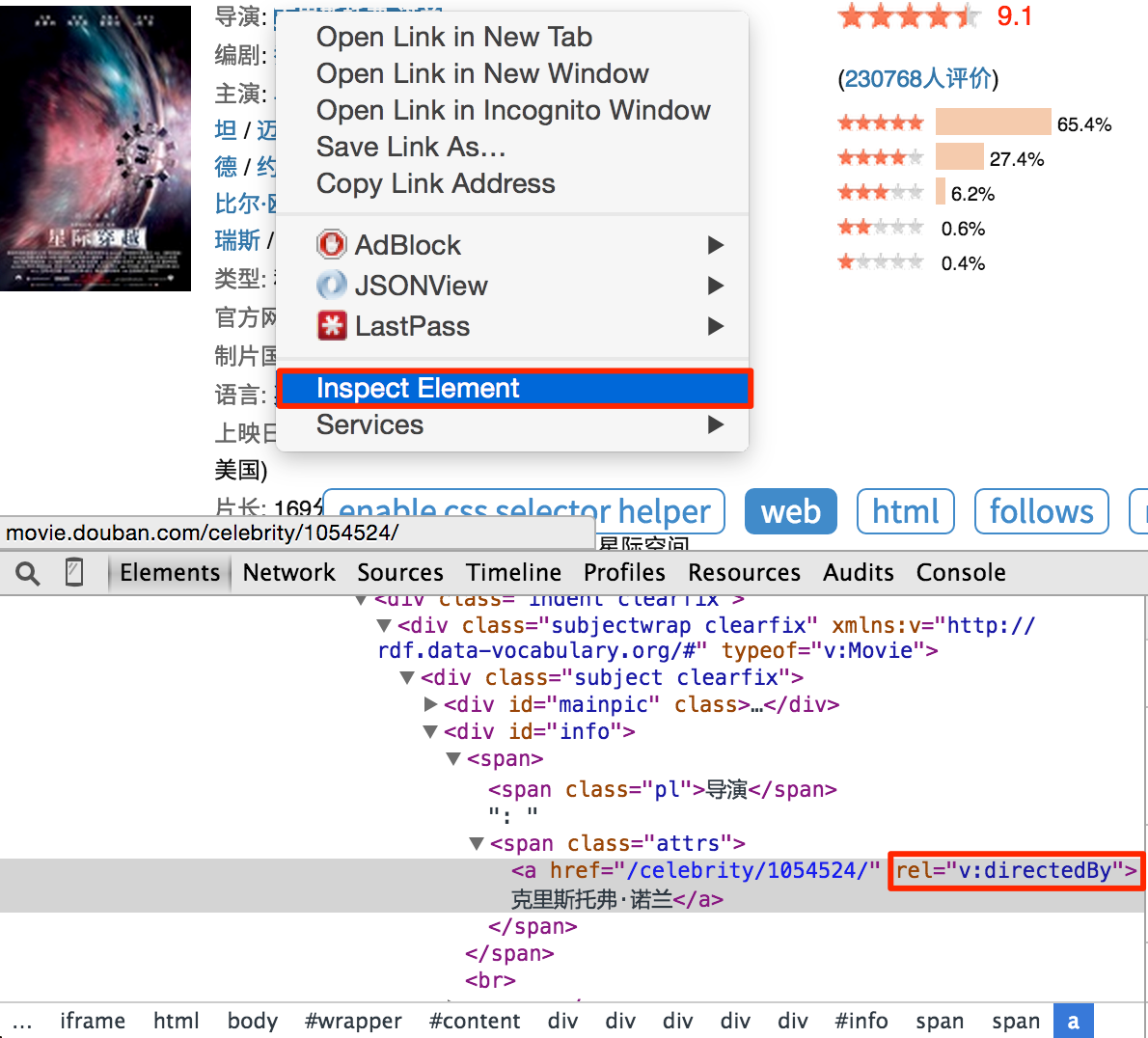
右键点击需要提取的元素,点击审查元素。你并不需要像自动生成的表达式那样写出所有的祖先节点,只要写出那些能区分你不需要的元素的关键节点的属性就可以了。不过这需要抓取和网页前端的经验。所以,学习抓取的最好方法就是学会这个页面/网站是怎么写的。
你也可以在 Chrome Dev Tools 的 Javascript Console 中,使用 $$(a[rel="v:directedBy"]) 测试 CSS Selector。
开始抓取
- 使用
run单步调试你的代码,对于用一个callback最好使用多个页面类型进行测试。然后保存。 - 回到 Dashboard,找到你的项目
- 将
status修改为DEBUG或RUNNING - 按
run按钮

 浙公网安备 33010602011771号
浙公网安备 33010602011771号