
大数据资源调度Yarn解析
 今天来介绍下资源调度Yarn,Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
今天来介绍下资源调度Yarn,Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
今天来介绍下资源调度Yarn,Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
Yarn基本架构
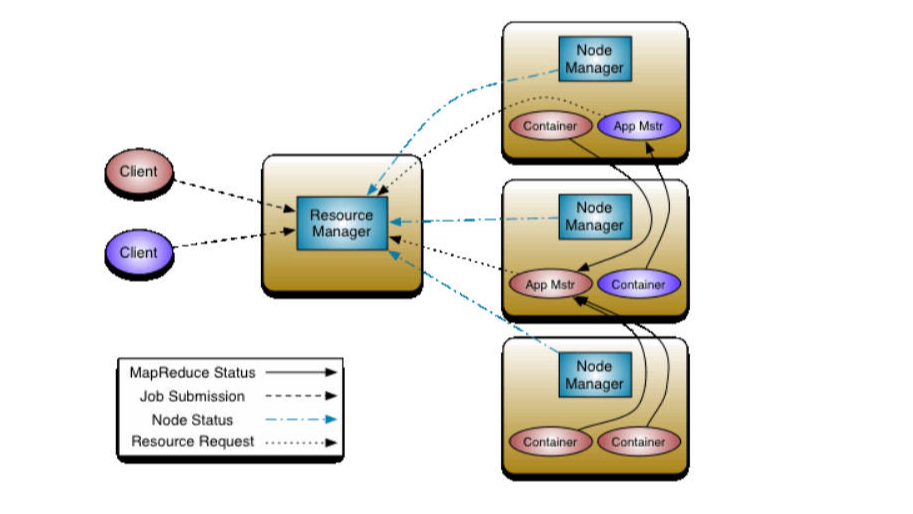
Yarn主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。

ResourceManager主要作用:
- 处理客户瑞请求。
- 监控NodeManager。
- 启动或监控ApplicationMaster。
- 资源的分配与调度。
NodeManager主要作用:
- 管理单个节点上的资源。
- 处理来自ResourceManagerE的命令。
- 处理来自ApplicationMaster的命令。
ApplicationMaster主要作用:
- 负责数据的切分。
- 为应用程序申请资源并分配给内部的任务。
- 任务的监控与容错。
Container:是YARN中的资源抽象,封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
Yarn工作机制
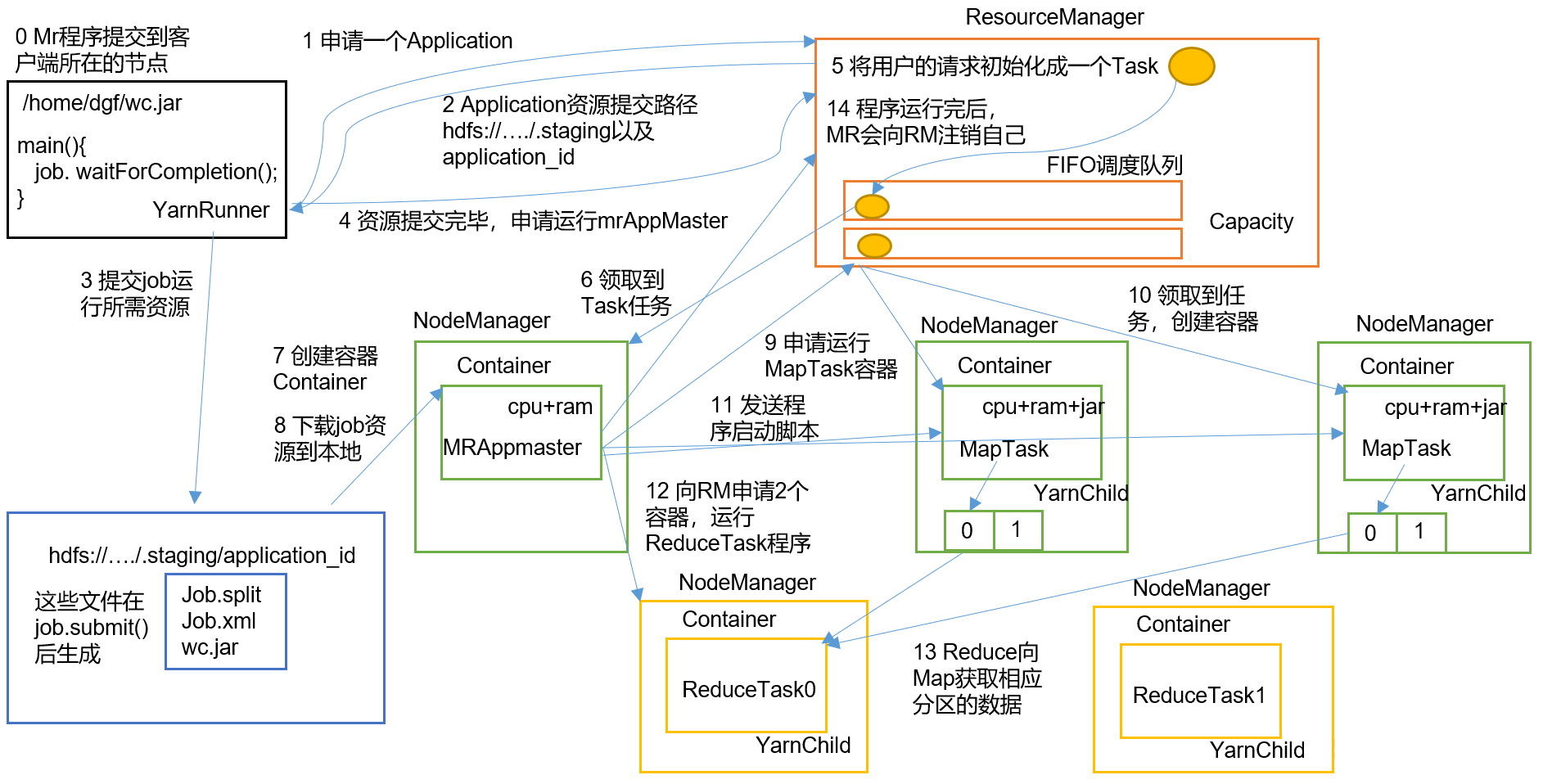
- MapReduce程序提交到客户端所在的节点。
- YarnRunner向ResourceManager申请一个Application。
- ResourceManager将该应用程序的资源路径返回给YarnRunner。
- 该程序将运行所需资源提交到HDFS上。
- 程序资源提交完毕后,申请运行mrAppMaster。
- ResourceManager将用户的请求初始化成一个Task。
- 其中一个NodeManager领取到Task任务。
- 该NodeManager创建容器Container,并产生mrAppMaster。
- Container从HDFS上拷贝资源到本地。
- mrAppMaster向ResourceManager申请运行MapTask资源。
- ResourceManager将运行MapTask任务分配给另外两个NodeManager,这两个NodeManager分别领取任务并创建容器。
- mrAppMaster向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
- mrAppMaster等待所有MapTask运行完毕后,向ResourceManager申请容器,运行ReduceTask。
- ReduceTask向MapTask获取相应分区的数据。
- 程序运行完毕后,mrAppMaster会向ResourceManager申请注销自己。
资源调度器
Hadoop的调度器有三种,FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.x默认使用的资源调度器就是容量调度器Capacity Scheduler。
可在配置文件中指定使用哪个调度器。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
FIFO:
- 按照到达时间顺序,先到先服务。
容量调度器:
- 支持多队列,每个队列可配置一定资源,每个队列又采用FIFO调度策略。
- 为防止独占队列中资源,对同一用户提交的作业所占资源量进行了限定。
- 计算每个队列中正在运行的任务数与应该分得的计算资源之间的比值,选择该比值最小的队列(最闲的)。
- 按照作业优先级和提交时间顺序,同时考虑用户资源量限制和内存限制对队列内任务排序。
公平调度器:
- 同队列所有任务共享资源,在时间尺度上获得公平的资源。
- 支持多队列多作业,每个队列可以单独配置。
- 同一队列的作业按照其优先级分享整个队列的资源,并发执行。
- 每个作业可以设置最小资源值,调度器会保证作业获得其以上的资源。
总结
Yarn负责的就是资源的调度,内容不是很多,重点是要能说出Yarn的工作机制,还有调度器的种类和彼此的区别。
写到这里,大数据的组件Hadoop算是告一段落了。结合前几篇介绍Hadoop的文章,Hadoop的组成:存储的HDFS、计算的MapReduce、资源调度的Yarn,都一一介绍完毕。当然单是会Hadoop还不能胜任大数据开发的工作,还需要编程语言java和sql的功底,其次还有一些大数据场景下的组件也需要掌握,比如kafka、spark、flink、clickhouse、hbase、redis、flume、doris等组件。这些有的是负责数据采集,有的是负责数据存储,还有的负责数据的处理,具体用哪个来做要看公司的需求,每个公司的组件未必都是一成不变的,但万变不离其宗,掌握这些后就可以做大数据开发了。
后面会继续更新其他的大数据组件和技术,另外面试题也在整理中,感兴趣的小伙伴可以关注一下。
以上就是今天的内容分享,下篇见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号