软件工程第二次实践个人编程作业
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 360 | 480 |
| Design Spec | 生成设计文档 | 40 | 50 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 50 |
| Design | 具体设计 | 40 | 40 |
| Coding | 具体编码 | 300 | 500 |
| Code Review | 代码复审 | 50 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 150 | 150 |
| 合计 | 1130 | 1525 |
题目回顾
数据来源
GH Archive
GH Archive 是一个 GitHub 归档数据的下载地址,它提供了从 2011 年至今的 GitHub 活动数据。
点击下载示例数据
题目要求
本题关注以下这几种信息类型:
需要统计以下内容
- (基础)个人的 4 种事件的数量。
- (基础)每一个项目的 4 种事件的数量。
- (提高)每一个人在每一个项目的 4 种事件的数量。
格式要求
- 执行文件为
GHAnalysis,拓展名依所选语言而定,注意 Linux 操作系统文件系统区分大小写。 - 初始化
- C++:
GHAnalysis <--init|-i> <path to data> - Java:
java -Dfile.encoding=UTF-8 -jar GHAnalysis.jar <--init|-i> <path to data> - Python:
python3 GHAnalysis.py <--init|-i> <path to data>
- C++:
- 查某用户的某事件数量运行格式:
- C++:
GHAnalysis <-u|--user> user <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent> - Java:
java -Dfile.encoding=UTF-8 -jar GHAnalysis.jar <-u|--user> user <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent> - Python:
python3 GHAnalysis.py <-u|--user> user <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent>
- C++:
- 查询某项目的某事件数量运行格式:
- C++:
GHAnalysis user/repo <-r|--repo> user/repo <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent> - Java:
java -Dfile.encoding=UTF-8 -jar GHAnalysis.jar <-r|--repo> user/repo <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent> - Python:
python3 GHAnalysis.py <-r|--repo> user/repo <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent>
- C++:
- 查询某用户在某项目的某事件数量运行格式:
- C++:
GHAnalysis <-u|--user> user <-r|--repo> user/repo <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent> - Java:
java -Dfile.encoding=UTF-8 -jar GHAnalysis.jar <-u|--user> user <-r|--repo> user/repo <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent> - Python:
python3 GHAnalysis.py <-u|--user> user <-r|--repo> user/repo <-e|--event> <push|IssueCommentEvent|IssuesEvent|PullRequestEvent>
- C++:
- 输出格式为单独的数字。
运行格式
- 会先运行一次初始化指令,然后在运行其他指令。
- 多个参数顺序不一定一致。
<path to data>是一个文件夹。
数据范围
- 数据文本小于 10GB。
任务分解
- 由于输入文件过大,内存不足,所以采取读取一个文件后立刻执行,再读入下一个文件
- 发现单进程初始化过慢,所以决定使用多进程
- 发现之后的查询整合爬下的15Gjson包过慢,所以考虑使用数据库提升速度
- 因此次任务颗分解为编辑命令行接口,json文件的读取,数据的解析,json文件的写入,数据的查找,单线程变为多线程,数据库接入
迭代过程描述与困难描述及解决办法寻找
- 前前后后迭代了近10个版本,在15G的json文件来回测试,这里只是说说主要的版本
 ,感觉迭代更新完善的过程离不开遇到的困难,于是放在一起讲了。
,感觉迭代更新完善的过程离不开遇到的困难,于是放在一起讲了。
前情任务
- 首先直接编写以上编辑命令行接口,json文件的读取,数据的解析,json文件的写入,数据的查找的代码(十分感谢助教的帮助【比心】)
大文件的输入
- 由于输入的上限是10G,因此直接一次性读取是不可能的,所以必须读取一个文件后立马执行,释放内存空间,而后再执行下一个文件
def __init(self, dict_address: str):
i = 1
for root, dic, files in os.walk(dict_address):
for f in files: # 找格式文件
if f[-5:] == '.json':
json_list = [] # 读入
x = open(dict_address + '\\' + f,
'r', encoding='utf-8').read()
str_list = [_x for _x in x.split('\n') if len(_x) > 0]
for i, _str in enumerate(str_list): # 序号,每列字符
try:
json_list.append(json.loads(_str))
except: # 注意
pass
i += 1
self.solve(json_list)
del x, str_list, json_list
gc.collect()
- 这一步我觉得最关键的是将
json_list = []写入循环内,之前没仔细看,导致运行15G文件的时候内存不断向上飙,而且越运行越慢,然后怀疑python清理内存的机制,不断百度试了各种清理内存的方法比如甚至怀疑是变量的相互引用导致python无法清理于是用了
del 变量名
gc.collect()
用了这个内存确实增长较慢了,但还是在飙
而最后才发现json_list每次循环没及时清除,导致后面的处理要再干一遍之前的工作,内存理所应当地不断飙升
单进程变为多进程
- 完成以上操作后,运行占用的内存已经稳定在2G左右了(好后悔没边做边截图,之后许多内容也只能靠文字描述了),但是cpu利用率最多也才30%左右,于是我想到了多进程工作,压榨cpu,大大缩短初始化时间。
- 起初我使用的多进程方法代码为列表式的:
def __init(self, dict_address: str):
i = 0
for root, dic, files in os.walk(dict_address):
processes = []
for f in files:
if i < 3:
i += 1
processes.append(Process(target=self.fly, args=(f, dict_address, i,)))
else:
i = 0
processes.append(Process(target=self.fly, args=(f, dict_address, i,)))
for process in processes:
process.start()
for process in processes:
process.join()
processes = []
for process in processes: # 防止文件非整
process.start()
for process in processes:
process.join()
但是这个多进程的方式是4个进程一起执行,只有这4个都执行完后才有下面4个继续执行,特别要注意列表,一定要控制里面的个数,否则无限加进程,直接cpu跑满,内存跑炸,直接死机,亲测有效。
- 而后我又发现了另外一种进程池的方法:
def __init(self, dict_address: str):
i = 0
pool = multiprocessing.Pool(processes=4)
for root, dic, files in os.walk(dict_address):
for f in files:
pool.apply_async(self.fly, args=(f, dict_address,))
pool.close()
pool.join()
这个方法相比于上面同样是4个进程一起执行,但一旦有个进程执行完后立马重新加入一个进程,少了等待的时间。但是pool.apply_async(function, args=(,))函数中的参数要设置正确,不然会导致一个进程运行,多个进程在围观。
多进程成功后的处理
- 由于是多个相同的进程在跑,难免同时访问和存储一个变量,这就导致了头疼的问题,此时
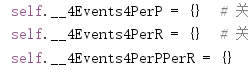 这三个字典在多进程写入后无法保存,最后返回的是三个空字典,若在访问时加个锁,难免会拖慢多进程的处理时间
这三个字典在多进程写入后无法保存,最后返回的是三个空字典,若在访问时加个锁,难免会拖慢多进程的处理时间 - 于是我想到了将每个多进程处理处理数据,将无用的数据例如URL等剔除,然后将每次处理结果保存在json_1这个文件夹内,最后利用单进程处理已经经过多进程处理过的数据,然后在把这个文件夹删除(我还是留着截图吧)
def __init(self, dict_address: str, k=1):
i = 0
if k:
pool = multiprocessing.Pool(processes=4)
for root, dic, files in os.walk(dict_address):
for f in files:
pool.apply_async(self.fly, args=(f, dict_address,))
pool.close()
pool.join()
else:
for root, dic, files in os.walk(dict_address):
for f in files: # 找格式文件
if f[-5:] == '.json':
x = open('json_1\\' + f,
'r', encoding='utf-8').read()
x = json.loads(x)
self.solve1(x)
def fly(self,f,dict_address):
self.done1+=1
if f[-5:] == '.json':
json_list = [] # 读入
x = open(dict_address + '\\' + f,
'r', encoding='utf-8').read()
str_list = [_x for _x in x.split('\n') if len(_x) > 0]
# str_list = [_x for _x in x.split('\n') if len(_x) > 0]
for i, _str in enumerate(str_list): # 序号,每列字符
try:
json_list.append(json.loads(_str))
except: # 注意
pass
i += 1
self.solve(json_list,f)
del x, str_list, json_list
gc.collect()
def solve(self,json_list,f1):
records = self.__listOfNestedDict2ListOfDict(json_list) #带所有字典的列表
k=[]
for i in records:
k.append({'actor__login':i['actor__login'],'type':i['type'],'repo__name':i['repo__name']})
with open('json_1\\'+f1, 'w', encoding='utf-8') as f: # 初始化
json.dump(k, f) # 写入
感觉这种方法还是挺傻的,但是简单呀
尝试过多线程,但不如人意,甚至拖慢速度
数据库
- 此处改进了查询速度,但只能对题目要求的四个事件进行查询,无法像原代码那样可以查询要求外的其他事件
- 使用了sqlite3库,数据库初始化
def make(self,u,e,t,t1):
s = "'{}',{},{},{},{}".format(u, e.get("PushEvent", 0), e.get("IssueCommentEvent", 0),
e.get("IssuesEvent", 0), e.get("PullRequestEvent", 0))
table=t
t1="{},repo1,repo2,repo3,repo4".format(t1)
self.insert(table, t1, s)
def db(self):
# repo1=push
# repo2=issuecomment
# repo3=issue
# repo4=pullrequest
cursor = self.cursor
sql = "create table users (user char(30) primary key ," \
"repo1 int,repo2 int,repo3 int,repo4 int)"
try:
cursor.execute(sql)
self.conn.commit()
except sqlite3.OperationalError:
pass
sql = "create table repos (repo char(30) primary key ," \
"repo1 int,repo2 int,repo3 int,repo4 int)"
try:
cursor.execute(sql)
self.conn.commit()
except sqlite3.OperationalError:
pass
sql = "create table numbers (userrepo char(50)primary key," \
"repo1 int,repo2 int,repo3 int,repo4 int)"
try:
cursor.execute(sql)
self.conn.commit()
except sqlite3.OperationalError:
pass
k=self.__4Events4PerP
for u, e in k.items():
self.make(u,e,"users","user")
k = self.__4Events4PerR
for u, e in k.items():
self.make(u, e, "repos", "repo")
k=self.__4Events4PerPPerR
for u, e1 in k.items():
for e2,e in e1.items():
self.make(u+e2, e, "numbers", "userrepo")
cursor.close()
self.conn.commit()
self.conn.close()
插入与查询代码为:
def select(self, table, c, w):
try:
sql = '''SELECT DISTINCT * FROM {table} where {c}'''.format(c=c, table=table)
cur = self.cursor.execute(sql)
for i in cur:
return i[w]
except sqlite3.OperationalError: # 找不到相应的数据
return 0
def insert(self, table, c, v, cursor):
try:
sql = "INSERT INTO {table}({c}) VALUES ({v})".format(table=table, c=c, v=v)
cursor.execute(sql)
self.conn.commit()
except sqlite3.IntegrityError: #数据重复插入
pass
对三个事件的搜索:
def switch(self,s):
if s=="PushEvent":
return 1
elif s=="IssueCommentEvent":
return 2
elif s=="IssuesEvent":
return 3
else:
return 4
def getEventsUsers(self, username: str, event: str) -> int: #事件一
w=self.switch(event)
c="user='{}'".format(username)
return self.select('users',c,w)
def getEventsRepos(self, reponame: str, event: str) -> int: #事件二
w = self.switch(event)
c = "repo='{}'".format(reponame)
return self.select('repos', c, w )
def getEventsUsersAndRepos(self, username: str, reponame: str, event: str) -> int: #事件三
w = self.switch(event)
c = "userrepo='{}'".format(username+reponame)
return self.select('numbers', c, w)
- 数据库的引入大大加快了查询的速度,但单进程数据库代码测试时无错误,但是将代码整合在多进程的时候多进程出现了无法写入json文件的错误,正在调试中
- 数据库查询虽快,但是一条条插入真的好慢,极大地增加了初始化的时间,但节省了日后的查询时间。
- 在deadline时间上,我终于发现了数据库的插入为啥这么慢,因为我是直接在文件上插入的,每次插入都要打开一次文件,这极大拖慢了插入时间,差不多每次插入都要100ms左右
- 于是我发现了更好的办法,先在内存中创建数据库,插入完成后再将其写入文件中,这里放出较为简明的代码概述
import sqlite3
from io import StringIO
self.conn = sqlite3.connect(":memory:")
self.cursor=self.conn.cursor()
con_file = sqlite3.connect('test.db3')
cur_file = con_file.cursor()
# 执行内存数据库脚本
try:
cur_file.executescript(str_buffer.getvalue())
except sqlite3.OperationalError: #之前已经初始化过了
pass
# 关闭文件数据库
cur_file.close()
#不要忘记在类的死亡前关闭数据库
def __del__(self):
self.cursor.close()
self.conn.close()
- 每条插入都是微秒级的
单元测试
单元测试截图和描述

单元测试覆盖率
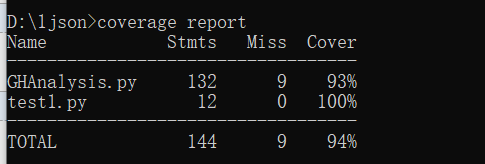
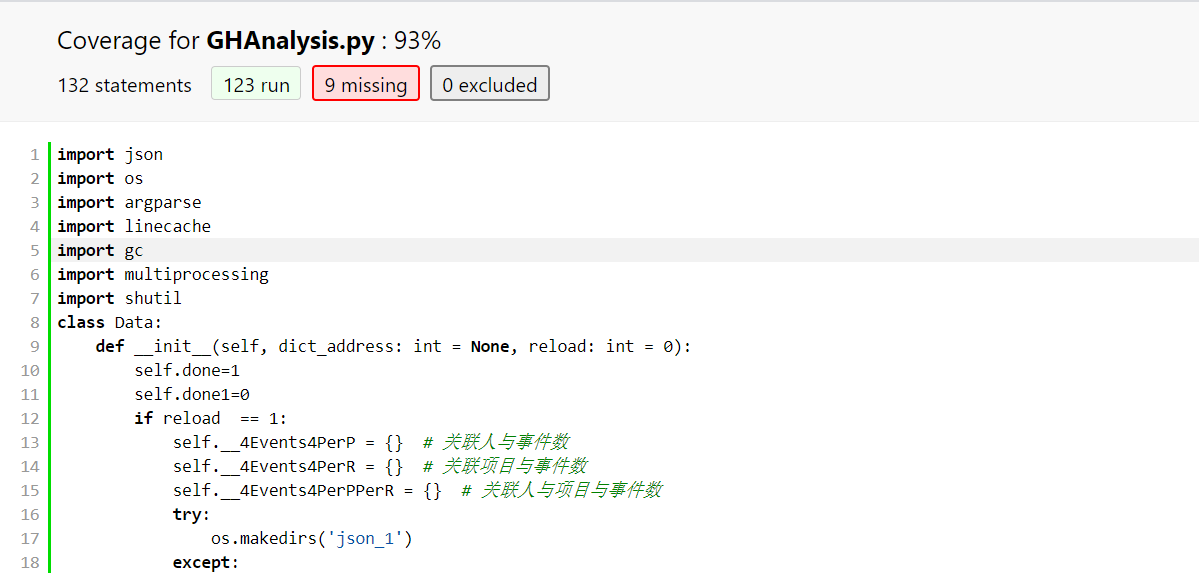
代码覆盖率达到了93%
性能优化及性能测试
单线程与多线程初始化时间测试
- 此处测试的数据大小为1.18G
单线程

多线程

- 可见多进程大大节约了初始化的时间
- 此处多进程为4个进程
数据库查询与普通查询时间测试
- 此处测试的数据大小为1.18G
数据库查询

普通json文件字典查询

- 可见普通查询多花费了数据库查询近176倍时间
代码说明
- 此次,我主要变更的是Data类的方法,使用的库
import json
import os
import argparse
import gc
import multiprocessing
import shutil
import sqlite3
from io import StringIO
- Data类初始化,reload为1时,执行初始化。然后检查路径,和有无数据库文件:
def __init__(self, dict_address: int = None, reload: int = 0):
self.conn = sqlite3.connect(":memory:")
self.cursor = self.conn.cursor()
self.done = 1
self.done1 = 0
if reload == 1:
self.__4Events4PerP = {} # 关联人与事件数
self.__4Events4PerR = {} # 关联项目与事件数
self.__4Events4PerPPerR = {} # 关联人与项目与事件数
try:
os.makedirs('json_1')
except:
# os.remove('json_1') #无法删除
shutil.rmtree('json_1') # 可以
os.makedirs('json_1')
self.__init(dict_address, 1)
self.__4Events4PerP = {} # 关联人与事件数
self.__4Events4PerR = {} # 关联项目与事件数
self.__4Events4PerPPerR = {} # 关联人与项目与事件数
self.__init(dict_address, 0)
shutil.rmtree('json_1') # 不需要该文件夹,删除
self.db()
if dict_address is None and not os.path.exists('test.db'): # 要查却没文件
raise RuntimeError('error: init failed')
self.conn = sqlite3.connect("test.db3")
self.cursor = self.conn.cursor()
- k=1时,进入多进程,k=0时,单进程完成后续任务(目前还没搞定添加上使用数据库代码导致多进程无法写入json文件,也就是多进程无法进入self.fly这个函数,贼头疼,搞了很久都无法解决,所以将多进程注释掉了,github代码也没传数据库部分的)
def __init(self, dict_address: str, k=1):
i = 0
if k:
#pool = multiprocessing.Pool(processes=4)
for root, dic, files in os.walk(dict_address):
for f in files:
# pool.apply_async(self.fly, args=(f,dict_address))
self.fly(f, dict_address)
#pool.close()
#pool.join()
else:
for root, dic, files in os.walk(dict_address):
for f in files: # 找格式文件
if f[-5:] == '.json':
x = open('json_1\\' + f,
'r', encoding='utf-8').read()
x = json.loads(x)
self.solve1(x)
- 多进程将每个json文件变成只有人,项目,事件的简单json,供后续单进程读入
def fly(self, f, dict_address):
self.done1 += 1
if f[-5:] == '.json':
json_list = [] # 读入
x = open(dict_address + '\\' + f,
'r', encoding='utf-8').read()
str_list = [_x for _x in x.split('\n') if len(_x) > 0]
for i, _str in enumerate(str_list): # 序号,每列字符
try:
json_list.append(json.loads(_str))
except: # 注意
pass
print(self.done1, i)
i += 1
self.solve(json_list, f)
del x, str_list, json_list
gc.collect()
def solve1(self, json_list):
for i in json_list:
if not self.__4Events4PerP.get(i['actor__login'], 0): # 字典中若不存在这个人
self.__4Events4PerP.update({i['actor__login']: {}}) # 加入这个人
self.__4Events4PerPPerR.update({i['actor__login']: {}}) # 加入
self.__4Events4PerP[i['actor__login']][i['type']
] = self.__4Events4PerP[i['actor__login']].get(i['type'], 0) + 1 # 这项事件数加一
if not self.__4Events4PerR.get(i['repo__name'], 0): # 若字典中没有这个项目
self.__4Events4PerR.update({i['repo__name']: {}}) # 创建
self.__4Events4PerR[i['repo__name']][i['type']
] = self.__4Events4PerR[i['repo__name']].get(i['type'], 0) + 1 # 这个项目此次事件加一
if not self.__4Events4PerPPerR[i['actor__login']].get(i['repo__name'], 0): # 若这个人字典中没有这个项目
self.__4Events4PerPPerR[i['actor__login']].update({i['repo__name']: {}}) # 创建
self.__4Events4PerPPerR[i['actor__login']][i['repo__name']][i['type']
] = self.__4Events4PerPPerR[i['actor__login']][i['repo__name']].get(i['type'], 0) + 1 # 人的项目的事件数加一
def solve(self, json_list, f1):
records = self.__listOfNestedDict2ListOfDict(json_list) # 带所有字典的列表
k = []
for i in records:
k.append({'actor__login': i['actor__login'], 'type': i['type'], 'repo__name': i['repo__name']})
with open('json_1\\' + f1, 'w', encoding='utf-8') as f: # 初始化
json.dump(k, f) # 写入
def __parseDict(self, d: dict, prefix: str):
_d = {}
for k in d.keys(): # 键
if str(type(d[k]))[-6:-2] == 'dict':
list = []
list1 = []
list.append(d[k])
list1.append(k)
while list:
d2 = list[0]
prefix = list1[0]
del list[0], list1[0]
for k1 in d2.keys():
if str(type(d2[k1]))[-6:-2] == 'dict':
list.append(d2[k1])
list1.append(k1)
else:
_k = f'{prefix}__{k1}' if prefix != '' else k1 # 把字典里的字典整到外面
_d[_k] = d2[k1]
else:
_k = f'{prefix}__{k}' if prefix != '' else k # 把字典里的字典整到外面
_d[_k] = d[k]
return _d
def __listOfNestedDict2ListOfDict(self, a: list):
records = []
for d in a: # d:一条项目
_d = self.__parseDict(d, '')
records.append(_d) # 字典放入列表,列表存有所有项目
return records
- 这是数据库初始化插入的代码
def select(self, table, c, w):
try:
sql = '''SELECT DISTINCT * FROM {table} where {c}'''.format(c=c, table=table)
cur = self.cursor.execute(sql)
for i in cur:
return i[w]
except sqlite3.OperationalError: # 找不到相应的数据
return 0
# 找不到记得等等返回0
def insert(self, table, c, v):
try: # 为了多次测
sql = "INSERT INTO {table}({c}) VALUES ({v})".format(table=table, c=c, v=v)
self.cursor.execute(sql)
self.conn.commit()
except sqlite3.IntegrityError:
pass
def make(self, u, e, t, t1):
s = "'{}',{},{},{},{}".format(u, e.get("PushEvent", 0), e.get("IssueCommentEvent", 0),
e.get("IssuesEvent", 0), e.get("PullRequestEvent", 0))
table = t
t1 = "{},repo1,repo2,repo3,repo4".format(t1)
self.insert(table, t1, s)
def db(self):
cursor = self.cursor
sql = "create table users (user char(30) primary key ," \
"repo1 int,repo2 int,repo3 int,repo4 int)"
try:
cursor.execute(sql)
self.conn.commit()
except sqlite3.OperationalError:
pass
sql = "create table repos (repo char(30) primary key ," \
"repo1 int,repo2 int,repo3 int,repo4 int)"
try:
cursor.execute(sql)
self.conn.commit()
except sqlite3.OperationalError:
pass
sql = "create table numbers (userrepo char(50)primary key," \
"repo1 int,repo2 int,repo3 int,repo4 int)"
try:
cursor.execute(sql)
self.conn.commit()
except sqlite3.OperationalError:
pass
k = self.__4Events4PerP.items()
for u, e in k:
self.make(u, e, "users", "user")
k = self.__4Events4PerR.items()
for u, e in k:
self.make(u, e, "repos", "repo")
k = self.__4Events4PerPPerR.items()
for u, e1 in k:
e1 = e1.items()
for e2, e in e1:
self.make(u + e2, e, "numbers", "userrepo")
str_buffer = StringIO()
for line in self.conn.iterdump():
str_buffer.write('%s\n' % line)
self.conn.commit()
con_file = sqlite3.connect('test.db3')
cur_file = con_file.cursor()
# 执行内存数据库脚本
try:
cur_file.executescript(str_buffer.getvalue())
except sqlite3.OperationalError: # 之前已经初始化过了
pass
# 关闭文件数据库
cur_file.close()
- 这是数据库执行三个查询的代码
def switch(self, s):
if s == "PushEvent":
return 1
elif s == "IssueCommentEvent":
return 2
elif s == "IssuesEvent":
return 3
else:
return 4
def getEventsUsers(self, username: str, event: str) -> int: # 事件一
w = self.switch(event)
c = "user='{}'".format(username)
return self.select('users', c, w)
def getEventsRepos(self, reponame: str, event: str) -> int: # 事件二
w = self.switch(event)
c = "repo='{}'".format(reponame)
return self.select('repos', c, w)
def getEventsUsersAndRepos(self, username: str, reponame: str, event: str) -> int: # 事件三
w = self.switch(event)
c = "userrepo='{}'".format(username + reponame)
return self.select('numbers', c, w)
代码规范链接
实践总结
- 这次实践编程真的学习了很多,特别是github的使用,单元测试及其覆盖率,还有性能测试。疯狂查资料和修改代码,特别是数据库的代码要一行行调试。总而言之,学到了好多新知识,才发现以前打代码编程好不规范,收获颇丰!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号