记录:对一致性Hash算法,Java代码实现的深入研究链接地址:
http://www.cnblogs.com/xrq730/p/5186728.html
全部来自:
https://mp.weixin.qq.com/s/yimfkNYF_tIJJqUIzV7TFA
https://www.zhihu.com/question/53927336
未解决的疑问,如果有知道的欢迎讨论:
1 什么时候会出现同一个key会计算出不同的hash值呢?为什么对于某些节点来说全局节点不可见????
2 redis中的缓存的slot和一致性hash算法的环形存储结构是如何映射的?
回答: 一致性hash计算的key的hash值对redis中的hash槽16384求余,根据余数确定key对应的hash槽,一个hash槽中会可能存放多个value值.??? 但是key贮存是根据顺时针最近的节点储存, 不知是否是 18384个槽对应2^32次方个数, redis中不同的槽位也代表了node节点覆盖的位置,因此储存在某个最近的节点其实是计算储存的槽位??????
3 根据key值计算的hash值是否和节点个数相关?
回答:一致性hash算法的计算key与节点的hash值与节点个数无关,其实下面的表述已经可以说明.
一致性hash算法主要用于分布式缓存中. 与传统的简单hash算法相比,能有效解决分布式存储结构下动态增加和删除节点的问题.
比如:使用简单hash%n (n表示分表的数量). 当数据量剧增,n张表已经无法存储时,就需要增加分表.但是原先的hash规则会打乱.使用hash%(n+m) 无法查找到原来存储的数据,因此需要进行整体的数据迁移,代价较高.
一致性hash算法:
1 我们把全量的缓存空间当做一个环形存储结构。环形空间总共分成2^32个缓存区,在Redis中则是把缓存key分配到16384个slot。

2 每一个缓存key都可以通过Hash算法转化为一个32位的二进制数,也就对应着环形空间的某一个缓存区。我们把所有的缓存key映射到环形空间的不同位置。
3 我们的每一个缓存节点(Shard)也遵循同样的Hash算法,比如利用IP做Hash,映射到环形空间当中。
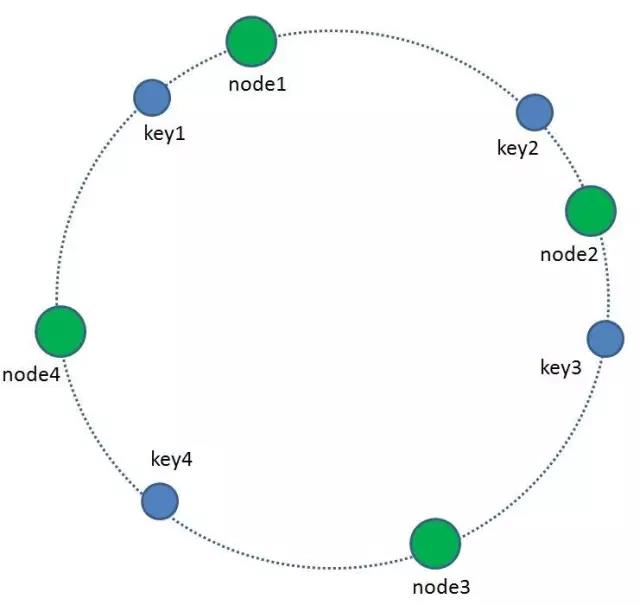
4 如何让key和节点对应起来呢?很简单,每一个key的顺时针方向最近节点,就是key所归属的存储节点。所以图中key1存储于node1,key2,key3存储于node2,key4存储于node3。
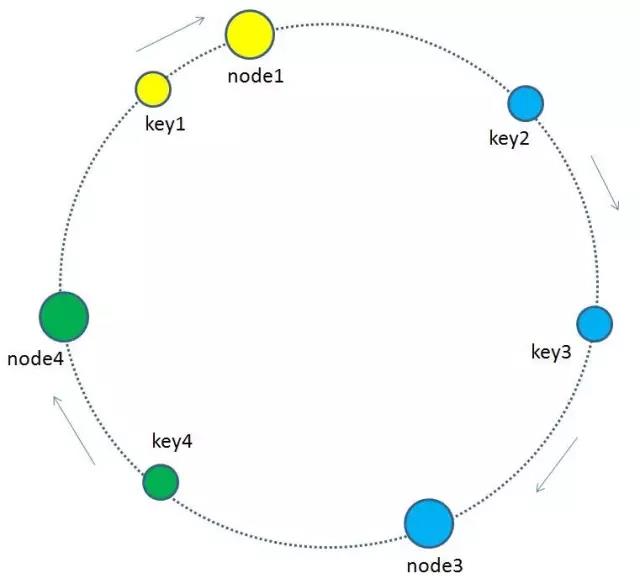
增加节点时:
当缓存集群的节点有所增加的时候,整个环形空间的映射仍然会保持一致性哈希的顺时针规则,所以有一小部分key的归属会受到影响。
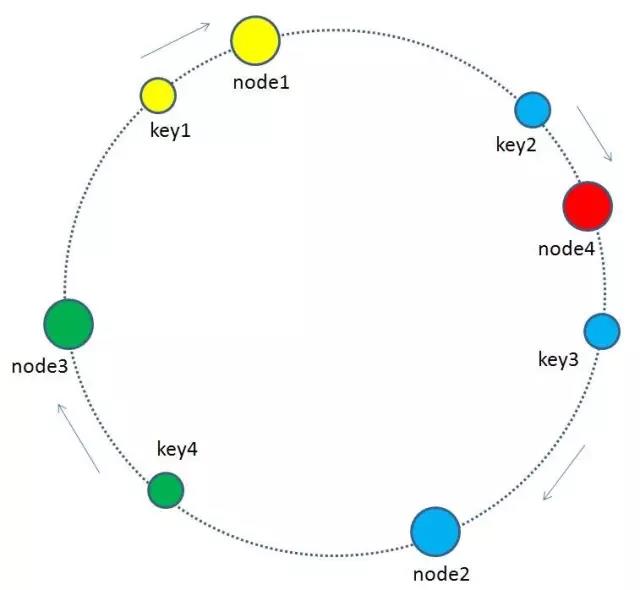
有哪些key会受到影响呢?图中加入了新节点node4,处于node1和node2之间,按照顺时针规则,从node1到node4之间的缓存不再归属于node2,而是归属于新节点node4。因此受影响的key只有key2。(我理解计算同一个key的hash值不变,但是挂载到不同的节点中,原节点的数据还存在,因此存在数据的冗余, 但是实际在测试时这个想法是错的. 因为在新增加节点的时候, 重新分配slot槽点时, 会将原来槽点中保存的数据会移动到新的节点中, 原来槽点中的数据也已经不存在, 因此不存在数据的冗余.)
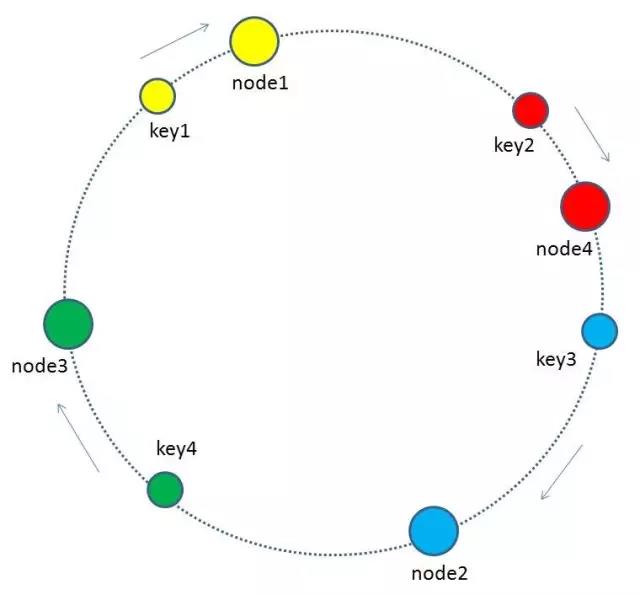
最终把key2的缓存数据从node2迁移到node4,就形成了新的符合一致性哈希规则的缓存结构。
删除节点
当缓存集群的节点需要删除的时候(比如节点挂掉),整个环形空间的映射同样会保持一致性哈希的顺时针规则,同样有一小部分key的归属会受到影响。
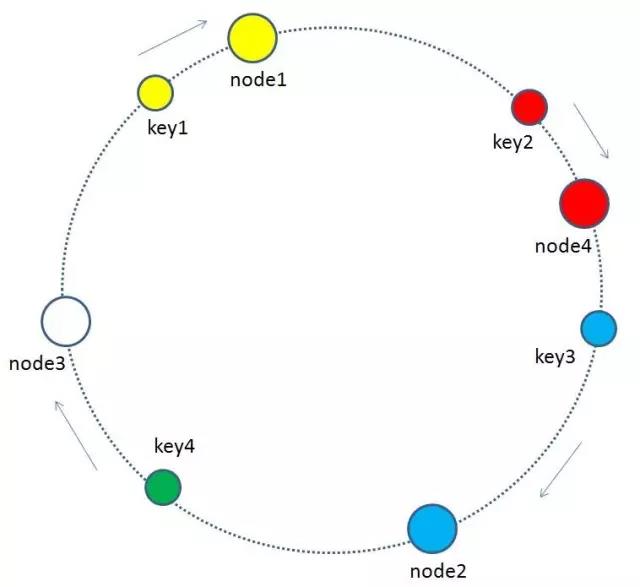
有哪些key会受到影响呢?图中删除了原节点node3,按照顺时针规则,原本node3所拥有的缓存数据就需要“托付”给node3的顺时针后继节点node1。因此受影响的key只有key4。
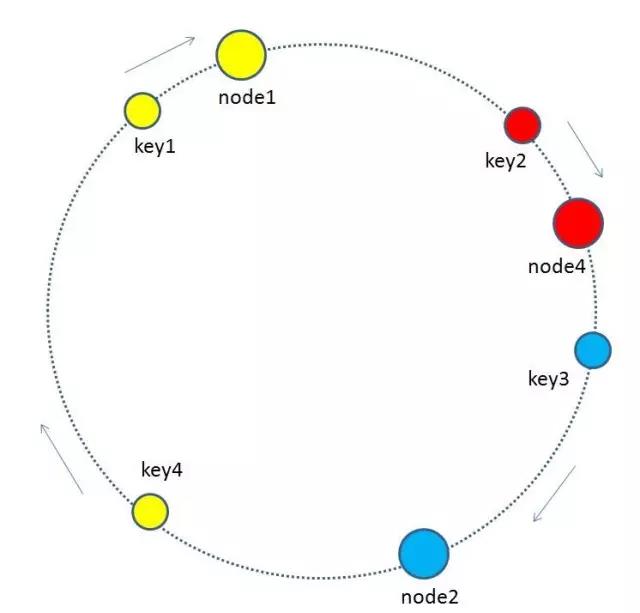
最终把key4的缓存数据从node3迁移到node1,就形成了新的符合一致性哈希规则的缓存结构.
由于node3已经挂掉,原来在node3上的节点缓存的数据不是直接从node3迁移过去,而是在再次查询时去查询顺时针的后续的后继节点,因缓存没有命中而刷新缓存,重新挂载到新的节点中.
4 每个缓存节点都按照iphash到环形空间,可能出现分布不均的情况,因此为了优化引入了虚拟节点.基于原来的物理节点映射出N个子节点,最后全部映射到环形空间.
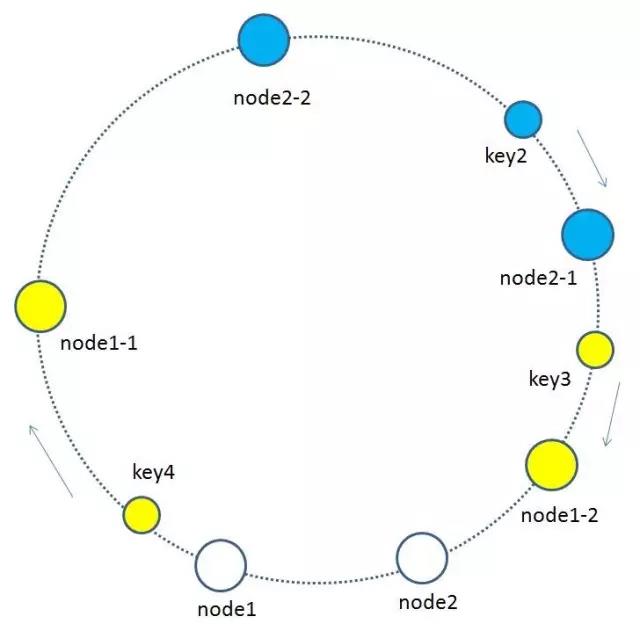
如上图所示,假如node1的ip是192.168.1.109,那么原node1节点在环形空间的位置就是hash(“192.168.1.109”)。
我们基于node1构建两个虚拟节点,node1-1 和 node1-2,虚拟节点在环形空间的位置可以利用(IP+后缀)计算,例如:
hash(“192.168.1.109#1”),hash(“192.168.1.109#2”)
此时,环形空间中不再有物理节点node1,node2,只有虚拟节点node1-1,node1-2,node2-1,node2-2。由于虚拟节点数量较多,缓存key与虚拟节点的映射关系也变得相对均衡了。
redis集群hash算法:
redis 3.0使用的是hash槽的概念,没有使用一致性hash算法.Redis的作者认为它的crc16(key) mod 16384的效果已经不错了,虽然没有一致性hash灵活,但实现很简单,节点增删时处理起来也很方便。
当往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有很多key和value。可以理解成表的分区,使用单节点时的redis时只有一个表,所有的key都放在这个表里;改用Redis Cluster以后会自动生成16384个分区表,你insert数据时会根据上面的简单算法来决定key应该存在哪个分区,每个分区里有很多key。
转自CSDN的sherry_y_fan用户,网址:https://blog.csdn.net/sherry_y_fan/article/details/80293361

 浙公网安备 33010602011771号
浙公网安备 33010602011771号