
上节介绍了机器学习的决策树算法,它属于分类算法,本节我们介绍机器学习的另外一种分类算法:最近邻规则分类KNN,书名为【k-近邻算法】。
KNN算法的工作原理是:将预测的目标数据分别跟样本进行比较,得到一组距离的数据,取最近的K个数据,遵循少数服从多数的原则,从而获得目标数据的分类。
简单的说,就是【近朱者赤,近墨者者黑】,下面我们一起通过KNN算法来演示这句名言的内涵。
【案例背景】
我的一个表弟,自幼聪明过人,读书的时候称得上名列前茅,父母以此为骄傲。但是好景不长,自从参加工作后,结识了几个狐朋狗友,从此进入了堕落的生活,名声也臭名远扬。
家里人经分析,主要是环境影响人,让他尽快远离他那些所谓的哥们朋友,多结识些正能量有思想有理想的人,也在此祝他成功吧~
【代码演示】
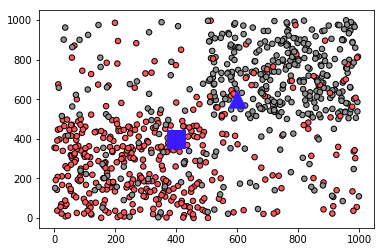
from sklearn import neighbors import numpy as np import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap #加上这句 #构造800个随机分布的点 X1 = np.random.randint(0, 500, (250, 2)) X2 = np.random.randint(500, 1000, (250, 2)) X3 = np.random.randint(0, 1000, (300, 2)) #这里添加一些杂点 X = np.concatenate((X1, X2, X3), axis=0) #初始化数据,用0和1表示结果 y = np.ones(800, dtype=np.int) y[0:250] = 0 y[500:650] = 0 #KNN算法核心语句,其中k=15 clf = neighbors.KNeighborsClassifier(15, weights='uniform') clf.fit(X, y) #显示预测结果 test_x1 = 400 test_y1 = 400 test_x2 = 600 test_y2 = 600 x = np.array([[test_x1, test_y1]]) Z = clf.predict(x) print('蓝色方块归类:', Z) x = np.array([[test_x2, test_y2]]) Z = clf.predict(x) print('蓝色三角归类:', Z) #将数据图形化显示, 结果0用红色显示,1用黑色显示 cmap_bold = ListedColormap(['#ff6666', '#919191']) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=30) plt.scatter([test_x1], [test_y1],marker='s', color='#224EFF', s= 300) plt.scatter([test_x2], [test_y2], marker='^', color='#224EFF', s= 300) plt.show()
【运行结果】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号