
本节进入机器学习的核心内容 - 机器学习算法篇,我会用实例演示一些常用的机器学习算法。
下面演示第一个机器学习算法:决策树
决策树与其他算法相比有很多优点,其中最主要的一个优点是机器和人都能看懂,我们使用机器学习的模型就能完成预测任务。
在代码演示之前需要安装一个树型结构的显示工具:graphviz
在Mac系统中使用如下命令进行安装:
$ brew install graphviz
案例背景描述:
小文,女,芳龄28,苗条淑女一枚,人见人爱,花见花开型的。可能是自己的条件比较优越,再加上人际圈比较广,对选择男朋友的标准也比较多,按她的话说眼睛都挑花了,后面都挑麻木了。作为小文的老朋友,她也知道我是搞数据分析决策方面的工作,不帮她确实有点不厚道啊~~ 经过跟小文沟通,她也积极配合,根据她之前约会的一些经验,共同整理了一份数据表:
| 约会对象 | 年龄 | 长相 | 身高 | 收入 | 家庭背景 | 职业 | 进展情况(结果) |
| 张三 | 较大 | 一般 | 较矮 | 较高 | 一般 | 稳定 | 发展一般 |
| 李四 | 同龄 | 一般 | 同高 | 凑合 | 较好 | 潜力 | 发展一般 |
| 王五 | 较小 | 较帅 | 较高 | 较低 | 较好 | 不好 | 没有发展 |
| 赵六 | 较大 | 较丑 | 同高 | 较高 | 一般 | 稳定 | 发展一般 |
| 陈七 | 较大 | 一般 | 较高 | 较高 | 一般 | 稳定 | 发展迅速 |
| 高八 | 同龄 | 一般 | 较矮 | 凑合 | 较差 | 潜力 | 没有发展 |
| 罗九 | 较大 | 较帅 | 较高 | 凑合 | 较差 | 潜力 | 发展迅速 |
以上数据似乎少了些,实际数据至少需要20条。有了以上数据后,我们开始下面的代码:
from sklearn.feature_extraction import DictVectorizer import numpy as np featureList = [{'年龄': '较大', '长相': '一般', '身高': '较矮', '收入':'较高', '家庭背景':'一般', '职业':'稳定'}, {'年龄': '同龄', '长相': '一般', '身高': '同高', '收入':'凑合', '家庭背景':'较好', '职业':'潜力'}, {'年龄': '较小', '长相': '较帅', '身高': '较高', '收入':'较低', '家庭背景':'较好', '职业':'不好'}, {'年龄': '较大', '长相': '较丑', '身高': '同高', '收入':'较高', '家庭背景':'一般', '职业':'稳定'}, {'年龄': '较大', '长相': '一般', '身高': '较高', '收入':'较高', '家庭背景':'一般', '职业':'稳定'}, {'年龄': '同龄', '长相': '一般', '身高': '较矮', '收入':'凑合', '家庭背景':'较差', '职业':'潜力'}, {'年龄': '较大', '长相': '较帅', '身高': '较高', '收入':'凑合', '家庭背景':'较差', '职业':'潜力'}] vec = DictVectorizer() dummyX = vec.fit_transform(featureList) .toarray() print('X样本数据:') print(dummyX) labelList = ['发展一般', '发展一般', '没有发展', '发展一般', '发展迅速', '没有发展', '发展迅速'] lb = preprocessing.LabelBinarizer() dummyY = lb.fit_transform(labelList) print('Y样本数据:') print(dummyY) clf = tree.DecisionTreeClassifier(criterion='entropy') clf = clf.fit(dummyX, dummyY) # Visualize model with open("./love.dot", 'w') as f: f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) #假如我们要预测:{'年龄': '较大', '长相': '一般', '身高': '同高', '收入':'凑合', '家庭背景':'一般', '职业':'潜力'} newRowX = np.array([[1., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 1., 0., 0., 1., 0., 0]]) print(newRowX) print("预测X数据: " + str(newRowX)) predictedY = clf.predict(newRowX) print("预测Y结果: " + str(predictedY)) #预测本次交往结果是【发展一般】
【运行结果如下】
X样本数据: [[ 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 0. 1. 0. 1. 0. 0.] [ 0. 1. 0. 1. 0. 0. 1. 0. 0. 0. 1. 0. 1. 0. 0. 1. 0. 0.] [ 0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 1. 0. 0. 1.] [ 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 1. 0. 0. 0. 1. 0.] [ 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 0. 0. 1. 1. 0. 0.] [ 0. 0. 1. 1. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 0. 1. 0. 0.] [ 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1.]] Y样本数据: [[1 0 0] [1 0 0] [0 0 1] [1 0 0] [0 1 0] [0 0 1] [0 1 0]] [[ 1. 0. 0. 0. 1. 0. 1. 0. 0. 0. 1. 0. 1. 0. 0. 1. 0. 0.]] 预测X数据: [[ 1. 0. 0. 0. 1. 0. 1. 0. 0. 0. 1. 0. 1. 0. 0. 1. 0. 0.]] 预测Y结果: [[ 1. 0. 0.]]
因为样本调用函数后顺序有所改变,经过整理如下:
featureList = [{'家庭背景':'一般','年龄': '较大','收入':'较高','职业':'稳定','身高':'较矮','长相':'一般'},
{'家庭背景':'较好','年龄': '同龄','收入':'凑合','职业':'潜力','身高':'同高','长相':'一般'},
{'家庭背景':'较好','年龄': '较小','收入':'较低','职业':'不好','身高':'较高','长相':'较帅'},
{'家庭背景':'一般','年龄': '较大','收入':'较高','职业':'稳定','身高':'同高','长相':'较丑'},
{'家庭背景':'一般','年龄': '较大','收入':'较高','职业':'稳定','身高':'较高','长相':'一般'},
{'家庭背景':'较差','年龄': '同龄','收入':'凑合','职业':'潜力','身高':'较矮','长相':'一般'},
{'家庭背景':'较差','年龄': '较大','收入':'凑合','职业':'潜力','身高':'较高','长相':'较帅'}]
这里我们用0和1来表示数据:
家庭背景: 100一般, 010较好, 001较差
年龄:100同龄,010较大, 001较小
收入:100凑合, 010较低, 001较高
职业:100不好, 010潜力, 001稳定
身高:100同高, 010较矮, 001较高
长相:100一般, 010较丑, 001较帅
现在提出如下疑问:小文下次想要见面约会的人的基本资料如下,我们来预测一下他们后面的发展到底如何呢?
约会对象:柯南
年龄:较大, 长相:一般, 身高:同高,收入:凑合,家庭背景:一般,职业:潜力
样本用0和1表示,调整列名顺序后,输入值如下: 100 010 100 010 100 100
[[1., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 1., 0., 0., 1., 0., 0]]
预测结果如下:
预测Y结果: [[ 1. 0. 0.]]
经过分析,用符号表示结果如下:
100:发展一般, 001: 没有发展, 010: 发展迅速
因为经过算法计算后的结果是100,所以小文本次与柯南相处,我们预测他们【发展一般】,至于后面的事情,让小文自己好好考虑吧,毕竟是终身大事:)
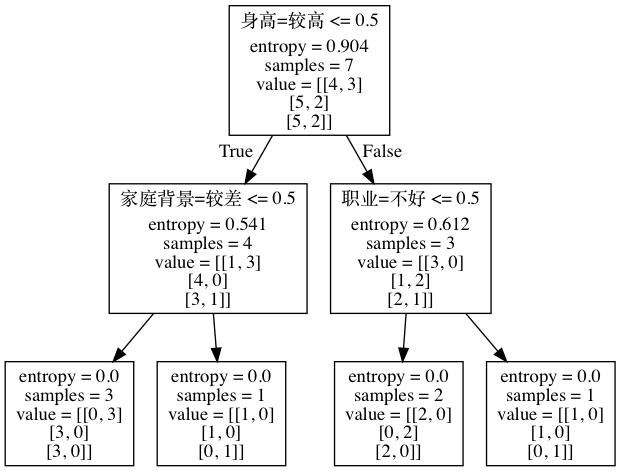
此外,graphviz安装完成后,打开终端,用命令定位到love.dot文件的目录位置后,执行下面的语句生成一张png的树型结构图。
$ dot -Tpng love.dot -o love.png
图片内容显示如下:
OK, 本讲到此结束,后续更多精彩内容,请持续关注我的博客。
本博文为原创文章,请珍惜博主的劳动成果,转载请注明出处。
本文地址:http://www.cnblogs.com/robin201711/p/7989370.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号