
zookeeper的安装以及shell命令使用
zookeeper概述:
zookeeper是一个开源的分布式协调服务,提供分布式数据一致性解决方案,分布式应用程序可以实现数据发布订阅、负载均衡、命名服务、集群管理分布式锁、分布式队列等功能。
数据一致性分为强一致性和最终一致性,强一致性指的如果数据不一致,就不对外提供数据服务,保证用户读取的数据始终是一致的。数据强一致性只需要通过锁机制即可解决,只有当同步完成以后才对外提供服务。而最终一致性要求数据最终同步即可,没有实时性要求。
应用场景:维护配置信息、分布式锁服务、集群管理、生成分布式唯一ID
CAP原则:CAP在分布式系统中主要指的是一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)
一致性:一致性指的是强一致性
可用性:系统提供的服务一直处于可用状态,用户的操作请求在指定的响应时间内响应请求,超出时间范围,认为系统不可用
分区容错性:分布式系统在遇到任何网络分区故障的时候,仍需要能够保证对外提供一致性和可用性服务,除非是整个网络都发生故障。
在一个分布式系统中不可能同时满足一致性、可用性、分区容错性,最多满足两个,对于分布式互联网应用而言,必须保证P,所以要么满足AP模型、要么满足CP模型
zookeeper 的三种角色 :
为了避免zk的单点问题,zk采用集群方式保证zk高可用
leader
leader负责处理集群的写请求,并发起投票,只有超过半数的节点同意后才会提交该写请求
follower
处理读请求,响应结果。转发写请求到leader,在选举leader过程中参与投票
observer
observer可以理解为没有投票权的follower,主要职责是当整个zk集群读请求负载很高时协助follower处理读请求。
为什么不增加follower节点呢?原因是增加follower节点会让leader在提出写请求提案时,需要半数以上的follower投票节点同意,这样会增加leader和follower的通信压力,降低写操作效率。
zookeeper 两种模式:
恢复模式
当服务启动或领导崩溃后,zk进入恢复状态,选举leader,leader选出后,将完成leader和其他机器的数据同步,当大多数server完成和leader的同步后,恢复模式结束
广播模式
一旦Leader已经和多数的Follower进行了状态同步后,进入广播模式。进入广播模式后,如果有新加入的服务器,会自动从leader中同步数据。leader在接收客户端请求后,会生成事务提案广播给其他机器,有超过半数以上的follower同意该提议后,再提交事务。
zookeeper环境搭建:需要先安装jdk环境
1)单机环境
1.上传zookeeper压缩包,并解压:tar -zxvf zookeeper-3.4.9.tar.gz
2.为 zookeeper 准备配置文件:
cd conf cp zoo_sample.cfg zoo.cfg
在zookeeper根目录下,创建 data 文件夹 mkdir data
修改zoo.cfg中的data属性 dataDir=/usr/local/zookeeper/zookeeper-3.4.9/data
3.zookeeper 服务启动
进入bin目录,启动服务输入命令 ./zkServer.sh start
关闭服务输入命令 ./zkServer.sh stop
查看状态 ./zkServer.sh status
2)集群环境
1.基于zookeeper-3.4.9复制三份,目录名称分别为zookeeper2181、zookeeper2182、zookeeper2183
cp -r zookeeper-3.4.9 zookeeper2181
cp -r zookeeper-3.4.9 zookeeper2182
cp -r zookeeper-3.4.9 zookeeper2183
2.修改zookeeper2181服务器对应配置文件

3.在上一步dataDir指定的目录下,创建myid文件,然后在该文件添加上一步server配置的对应A数字

4.zookeeper2182、zookeeper2183参照步骤2/3进行相应配置
5.分别启动三台服务器,检验集群状态
./zkServer.sh start
登录命令:

6.observer角色及其配置

数据结构:
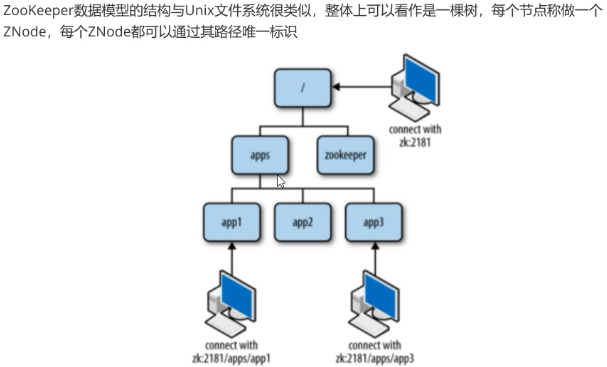
Znode 节点类型:
持久化目录节点( PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在
持久化顺序编号目录节点( PERSISTENT_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点依旧存在,Zookeeper会给该节点按照顺序编号
临时目录节点( EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除
临时顺序编号目录节点( EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,Zookeeper会给该节点按照顺序编号
zookeeper常用的shell命令:
登录zookeeper客户端:./zkCli.sh 远程登录:./zkCli.sh -server ip (./zkCli.sh -server 192.168.43.182:2181)
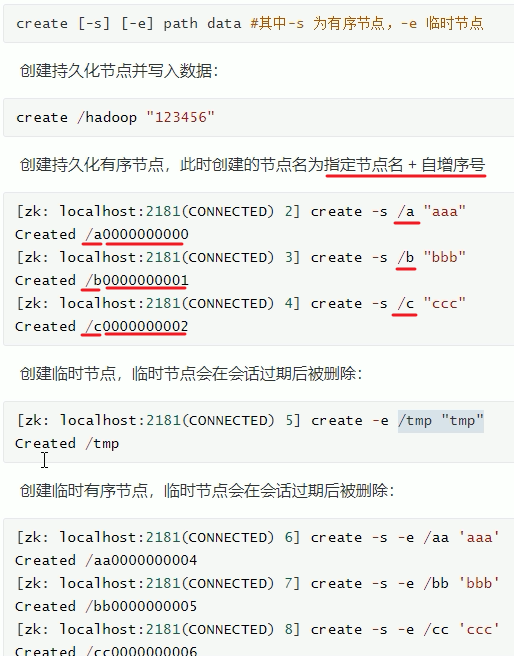
新增节点:
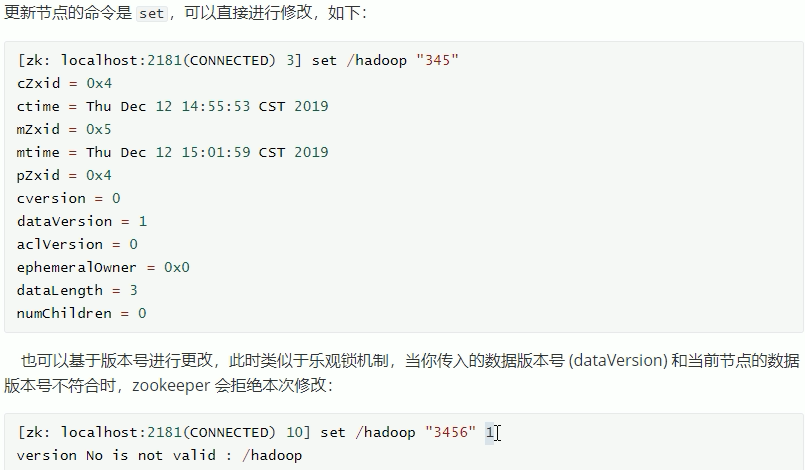
更新节点:
删除节点:

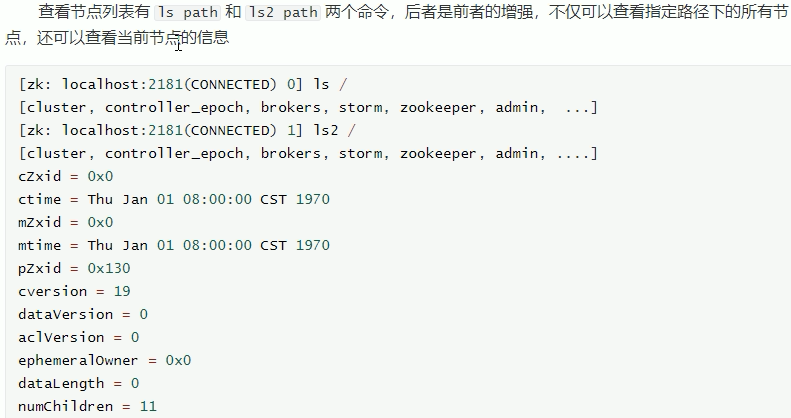
查看节点:


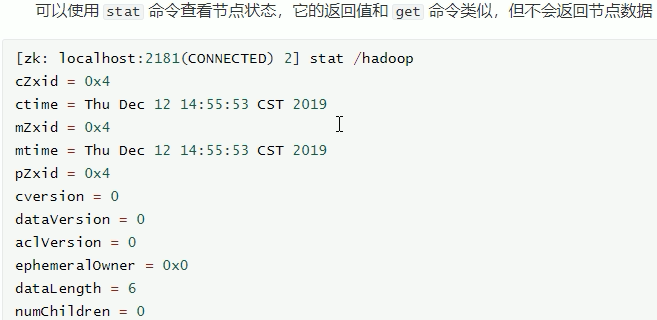
查看节点状态:
查看节点列表:
监听器get path [watch]:

监听器stat path [watch]:

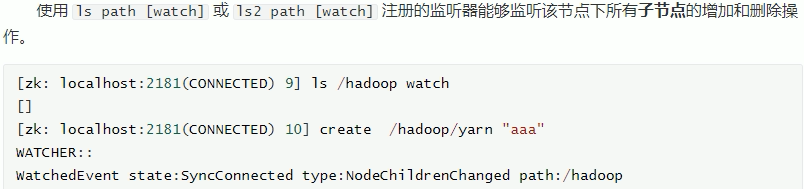
监听器 ls\ls2 path [watch]:
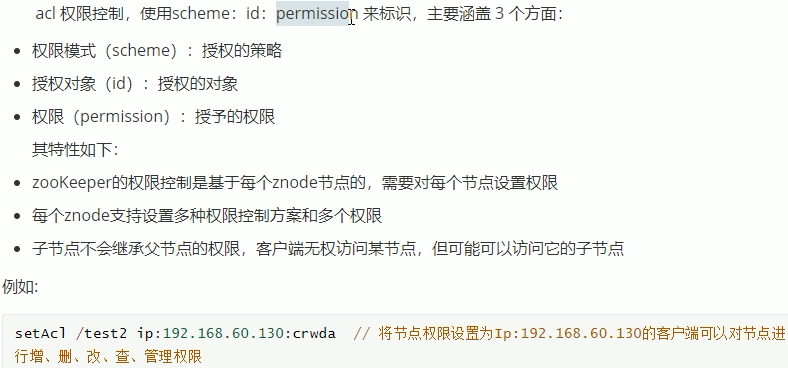
zookeeper的acl权限控制:
概述:
zookeeper类似文件系统,client可以创建节点、更新节点、删除节点,那么如何做到节点的权限的控制呢?
zookeeper的 access control list 访问控制列表可以做到这一点。
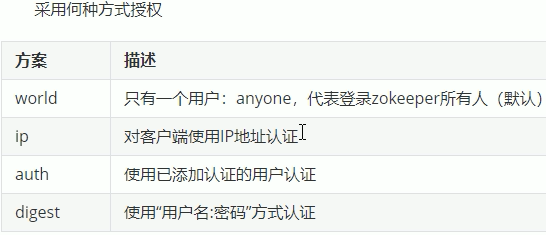
权限模式:
授权的对象:
授权对象ID是指,权限赋予的实体,例如:IP地址或用户。
授予的权限:
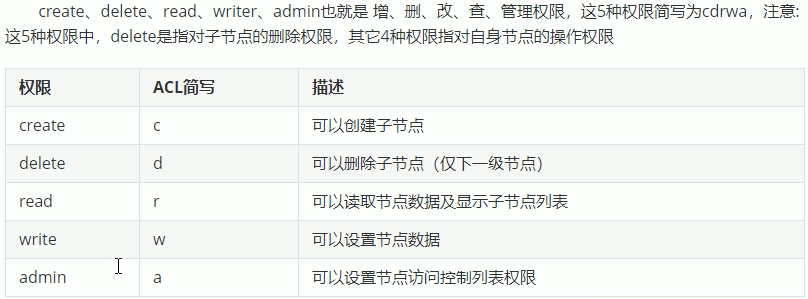
授权的相关命令:
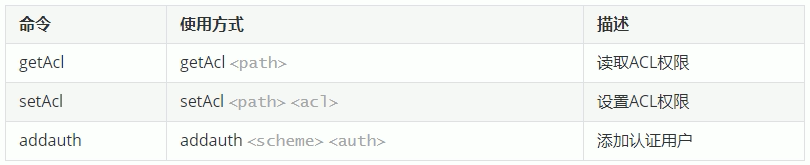
案例:
getAcl /node1
world授权模式:
命令:setAcl <path> world:anyone:<acl>
setAcl /node1 world:anyone:drwa
IP授权模式:
命令:setAcl <path> ip:<ip>:<acl>
setAcl /node2 ip:192.168.43.33:cdrwa
setAcl /node2 ip:192.168.43.33:cdrwa,ip:192.168.43.34:cdrwa
Auth授权模式:
命令:addauth digest <user>:<password> #添加认证用户
setAcl <path> auth:<user>:<acl>
addauth digest fan:123456 setAcl /node3 auth:fan:cdrwa
Digest授权模式:
命令:setAcl <path> digest:<user>:<password>:<acl>
这里的密码是经过SHA1及BASE64处理的密文,在shell中可以通过以下命令计算出:
echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64
echo -n fan:123456 | openssl dgst -binary -sha1 | openssl base64 #c2+ooVbyofyH2yzwMEZOmHYO7cE=
setAcl /node4 digest:fan:c2+ooVbyofyH2yzwMEZOmHYO7cE=:cdwra
添加了权限之后需要授权才能访问:addauth digest fan:123456
多种模式授权:
setAcl /node5 ip:192.168.43.33:cdr,auth:admin:cdrwa
acl超级管理员:
zookeeper的权限管理模式有一种叫做super,该模式提供一个超管可以方便访问任何权限的节点
假设这个超管是:super:admin,需要先为超管生成密码的密文:
echo -n super:admin | openssl dgst -binary -sha1 | openssl base64 #xQJmxLMiHGwaqBvst5y6rkB6HQs=
打开zookeeper目录下的/bin/zkServer.sh服务器脚本文件,找到如下一行:
nohup "$JAVA" "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}"
这是脚本中启动zookeeper的命令,默认只有以上两个配置项,我们需要添加一个超管的配置项
nohup "$JAVA" "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" "-Dzookeeper.DigestAuthenticationProvider.superDigest=super:xQJmxLMiHGwaqBvst5y6rkB6HQs="
启动zookeeper,输入如下命令添加权限:添加之后,此会话可以访问任何权限的节点
addauth digest super:admin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号