wafw00f修改-多线程
2022-09-06 11:48 rnss 阅读(233) 评论(0) 收藏 举报简介
https://github.com/EnableSecurity/wafw00f/
wafw00f是一款知名的WAF识别工具,目前Github有3500的Star。
在日常使用中发现了一些问题,包括:
- 只能单线程,当有大量网站需要识别时效率低。
- 某些网站在识别时会导致程序错误直接终止,这在大批量识别时很要命,因为程序中断后不会生成结果文件,导致前面识别的结果都没有保存。
- 程序本身能生成.csv结果文件,但生成的结果文件每行结果之间有一个空行,且筛选会有问题。
针对这些问题,着手对其进行修改,修改的目的如下:
- 使用多线程识别
- 解决某些网站在识别时会导致程序错误直接终止的问题
- 增加xlsx输出,使结果更好处理
修改的原则是尽量少去修改它的代码结构,使得修改后的使用方式与修改前区别不大。
下载源码后执行python3 setup.py install安装。
目录分析
目录分析部分引用《wafw00f源码浅析》(https://xz.aliyun.com/t/9497)
整体
- docs:sphinx自动生成文档的工作
- wafw00f:代码
- setup.py:安装脚本
wafw00f
- bin:启动文件,执行这里的脚本即可启动程序
- lib:asciiarts是logo,evillib是发请求的工具类
- plugins:指纹识别的规则
- main:核心代码
- manager:管理规则的脚本
- wafprio:指纹识别优先级规定
代码分析
简单分析下代码,因为这次修改只涉及main.py文件,所以其它就不说了,直接看main.py

先定义了一个类WAFW00F,然后定义了5个不同漏洞的攻击语句,用于触发waf。
下面类中的其它函数和不在类中的一些函数都暂时不看,直接看最后

直接运行main.py其实就是运行main函数,所以直接看main函数
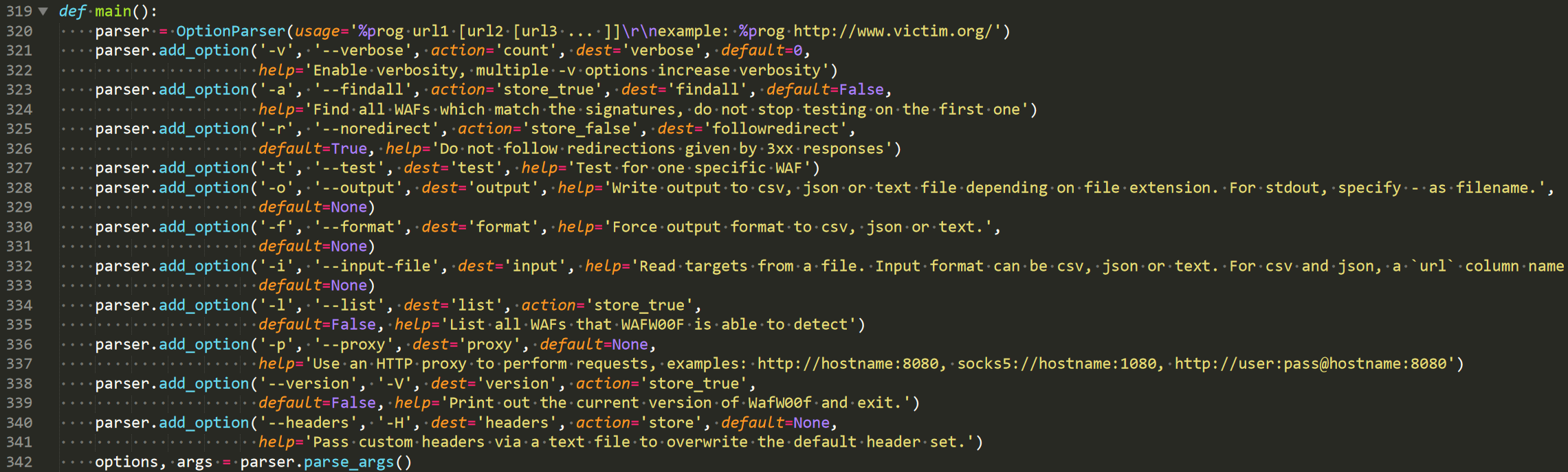
一开始获取参数,因为我们想提升批量识别时的效率,所以直接看input时的处理逻辑。

wafw00f提供json、csv以及txt三种输入方式,这里380行到408行就是解析不同的输入文件并将要识别的url存入targets数组,如果没有输入-i参数则直接识别单个url。
results = []
for target in targets:
if not target.startswith('http'):
log.info('The url %s should start with http:// or https:// .. fixing (might make this unusable)' % target)
target = 'https://' + target
print('[*] Checking %s' % target)
pret = urlParser(target)
if pret is None:
log.critical('The url %s is not well formed' % target)
sys.exit(1)
(hostname, _, path, _, _) = pret
log.info('starting wafw00f on %s' % target)
proxies = dict()
if options.proxy:
proxies = {
"http": options.proxy,
"https": options.proxy,
}
attacker = WAFW00F(target, debuglevel=options.verbose, path=path,
followredirect=options.followredirect, extraheaders=extraheaders,
proxies=proxies)
if attacker.rq is None:
log.error('Site %s appears to be down' % hostname)
continue
if options.test:
if options.test in attacker.wafdetections:
waf = attacker.wafdetections[options.test](attacker)
if waf:
print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, options.test, E))
else:
print('[-] WAF %s was not detected on %s' % (options.test, target))
else:
print('[-] WAF %s was not found in our list\r\nUse the --list option to see what is available' % options.test)
return
waf = attacker.identwaf(options.findall)
log.info('Identified WAF: %s' % waf)
if len(waf) > 0:
for i in waf:
results.append(buildResultRecord(target, i))
print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, (E+' and/or '+C).join(waf), E))
if (options.findall) or len(waf) == 0:
print('[+] Generic Detection results:')
if attacker.genericdetect():
log.info('Generic Detection: %s' % attacker.knowledge['generic']['reason'])
print('[*] The site %s seems to be behind a WAF or some sort of security solution' % target)
print('[~] Reason: %s' % attacker.knowledge['generic']['reason'])
results.append(buildResultRecord(target, 'generic'))
else:
print('[-] No WAF detected by the generic detection')
results.append(buildResultRecord(target, None))
print('[~] Number of requests: %s' % attacker.requestnumber)
这里就是在获取到targets数组后对数组中的所有url进行解析并识别,因为这次修改不涉及,所以不用了解识别waf的具体逻辑。注意上面解析url的部分:

这里就是造成程序终止的原因,当url解析失败时,程序会直接退出,等等这里需要修改。
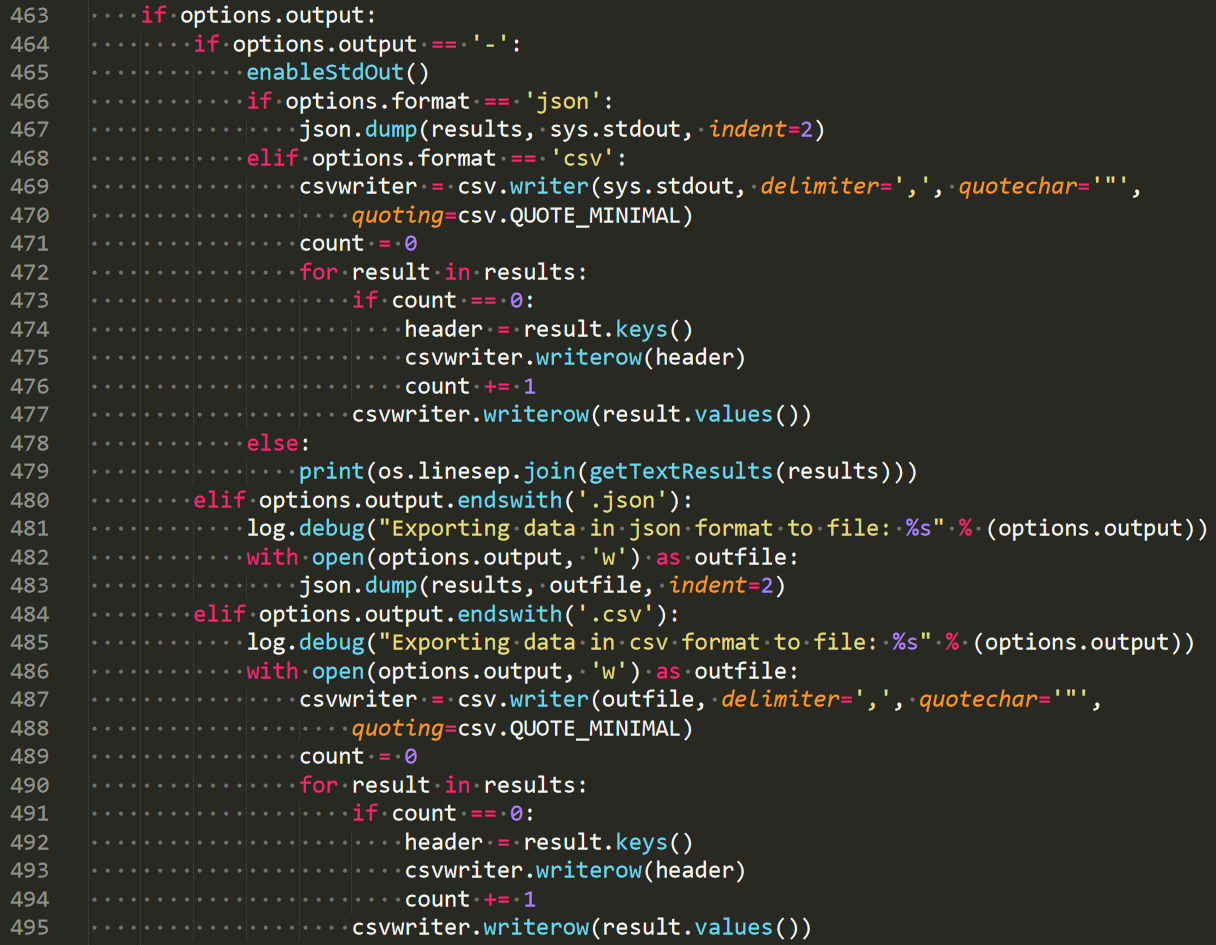
然后是输出结果到文件的代码,分别支持输出到json、csv或者txt。
代码修改
多线程
为了使用多线程,我把前面解析url及识别waf的代码写成了一个函数:
def handle_input(log, target_queue, options, extraheaders, results):
while True:
try:
target = target_queue.get()
if not target.startswith('http'):
log.info('The url %s should start with http:// or https:// .. fixing (might make this unusable)' % target)
target = 'https://' + target
# print('[*] Checking %s' % target)
pret = urlParser(target)
if pret is None:
log.critical('The url %s is not well formed' % target)
sys.exit(1)
(hostname, _, path, _, _) = pret
# log.info('starting wafw00f on %s' % target)
proxies = dict()
if options.proxy:
proxies = {
"http": options.proxy,
"https": options.proxy,
}
attacker = WAFW00F(target, debuglevel=options.verbose, path=path,
followredirect=options.followredirect, extraheaders=extraheaders,
proxies=proxies)
if attacker.rq is None:
log.error('Site %s appears to be down' % hostname)
continue
if options.test:
if options.test in attacker.wafdetections:
waf = attacker.wafdetections[options.test](attacker)
if waf:
print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, options.test, E))
else:
print('[-] WAF %s was not detected on %s' % (options.test, target))
else:
print('[-] WAF %s was not found in our list\r\nUse the --list option to see what is available' % options.test)
return
waf = attacker.identwaf(options.findall)
log.info('Identified WAF: %s' % waf)
if len(waf) > 0:
for i in waf:
results.append(buildResultRecord(target, i))
print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, (E+' and/or '+C).join(waf), E))
if (options.findall) or len(waf) == 0:
# print('[+] Generic Detection results:')
if attacker.genericdetect():
# log.info('Generic Detection: %s' % attacker.knowledge['generic']['reason'])
print('[*] The site %s seems to be behind a WAF or some sort of security solution' % target)
# print('[~] Reason: %s' % attacker.knowledge['generic']['reason'])
results.append(buildResultRecord(target, 'generic'))
else:
print('[-] No WAF detected by the generic detection')
results.append(buildResultRecord(target, None))
# print('[~] Number of requests: %s' % attacker.requestnumber)
finally:
target_queue.task_done()
同时为了解决线程间通信的问题,使用了队列来存储待识别的url。将部分不重要的打印信息注释掉,对于多线程的程序来说最好是一个url打印一条提示信息。
main函数中原来上面代码的位置改成下面的代码。
target_queue = Queue()
for target in targets:
target_queue.put(target)
results = []
for i in range(50):
t = Thread(target=handle_input, args=(log, target_queue, options, extraheaders, results))
t.daemon = True
t.start()
target_queue.join()
创建一个队列,然后将targets数组中的url都put进队列中,然后起50个线程去解析url并识别waf。这样多线程改造就完成了。
解决终止问题
看到上面说过的造成程序终止的地方:

因为前面添加的这个函数中直接用了while True死循环,所以这里的sys.exit(1)直接改成continue即可,对于多线程程序来说,碰到格式错误的url打印错误语句然后接着从队列中获取下一个url就行了。
输出xlsx
输出xlsx只要多写个elif即可
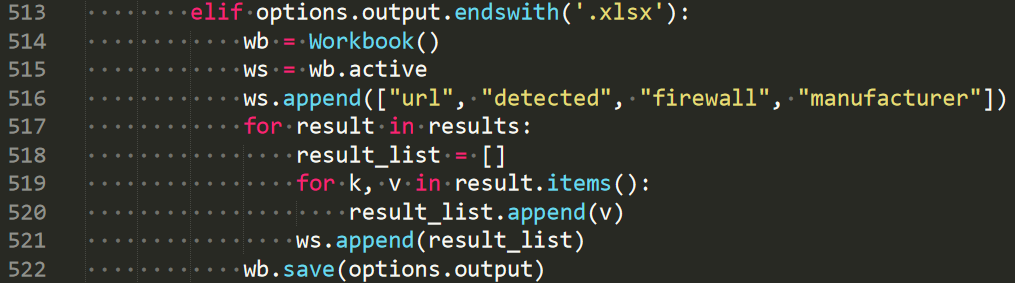
根据它csv的表头来生成xlsx文件即可。
最后线程数由命令行参数-T传入,默认50线程。
最终使用:
python3 main.py -i 1.txt -o 1.xlsx -T 20
总结
对于修改多线程或者增加输出格式这种功能来说,不需要修改它的核心代码,也就不需要去了解它核心代码的逻辑。
修改后的main.py: https://github.com/rnsss/wafw00f/blob/master/wafw00f/main.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号