极验反爬虫防护分析之接口交互的解密方法
本文要分享的内容是去年为了抢鞋而分析 极验(GeeTest)反爬虫防护的笔记,由于篇幅较长(为了多混点CB)我会按照我的分析顺序,分成如下四个主题与大家分享:
本文是第二篇《接口交互的解密方法》,书接上文,上一篇中,我们遗留了两个问题:
- 所有用于验证的代码都是混淆之后的,如何进行代码还原或者调试分析。
- 请求与返回的关键数据都是加密的后的字符串如上述3、4、6等接口中的W参数,如何解密。
下面进入正文~
JS代码的还原与调试分析
geetest的js代码不单是简单的压缩,应该是经过混淆加密的,下载一个geetest的js文件,格式化并还原编码后,会发现js加载之后直接执行了几个嵌套的大循环,猜测应该是通过decodeURI对关键信息进行解密,拼装成一个大数组,这样便达到隐藏关键代码和信息目的,如下图:

如此,程序的代码便可以写成封装成一个方法,通过数组下标来拼接程序代码,达到隐藏关键信息,预防静态分析的目的。根据我的经验,目前市面上好多前端代码都采用了这种代码加密思路,比如 同花顺数据中心的页面数据,为了防止接口被cors,构造了自定义的cookie信息,对应的js构造代码也是这类加密思路。由于还原此JS代码并不是本文的目的,所以我们就直接说调试分析方法,对还原代码有兴趣的童鞋可以自己再深入分析。
代码Hook及覆盖时机
如上说明,由于官网加载的Geetest脚本都是压缩加密混淆之后的代码,并不方便分析和调试。受X86年代更换目标dll路径就可以达到dll劫持思路的启发,我们将脚本下载下来格式化、替换转义字符之后,通过浏览器控制台加载修改后的脚本覆盖原js代码来达到同样的效果(因证书验证的问题,将代码放在了我自己的空间里):
var script = document.createElement('script'); script.src = "https://xxx/static/js/fullpage.8.8.4.js"; document.getElementsByTagName('head')[0].appendChild(script); var script = document.createElement('script'); script.src = "https://xxxx/static/js/slide.7.6.0.js"; document.getElementsByTagName('head')[0].appendChild(script);
经过分析,代码在执行完上一篇文章的第三步之后开始加载对应的代码,第四步的请求参数中的内容才开始加密的,因此要分析加密代码可以再加载了相应js之后再用我们的js进行覆盖即可。
加密代码的定位方法
浏览器中定位前端代码,最有效的方法莫过于通过 浏览器事件 + 条件断点的方式来定位了,但是由于上面说的代码加密的原因,这种定位方法在这里失效了,不论什么事件最终都会进入到上面说的大数组解析的方法中去,如下图:
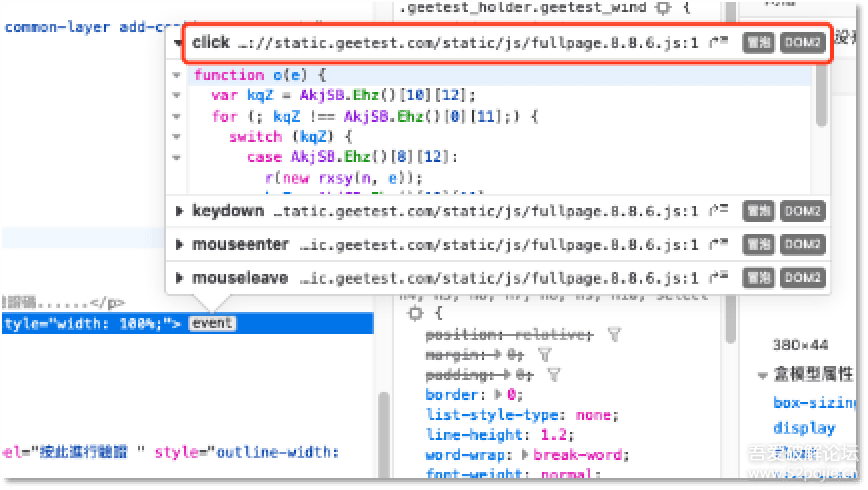
所以只能通过xhr请求入手,通过栈回溯的方法定位代码。值得庆幸的是火狐浏览器原生就支持堆栈跟踪,省了我们不少时间,如下图:
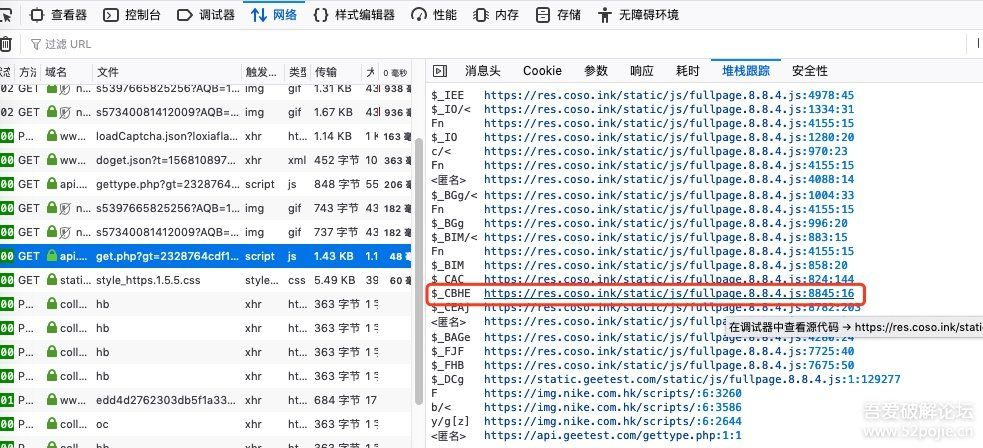
通过js下断点不断回溯,发现上图中红框部分是加密的代码部分,下断点,重新点击登录框,程序中断,如下图:

其中变量e的值记录一下:
46207!!219363!!CSS1Compat!!334!!-1!!-1!!-1!!-1!!1!!-1!!-1!!9!!60!!45!!9!!15!!-1!!-1!!-1!!-1!!-1!!1!!-1!!-1!!231!!2!!-1!!-1!!-1!!157!!23!!44!!23!!1396!!279!!1396!!877!!zh-CN!!zh-CN,zh,zh-TW,zh-HK,en-US,en!!-1!!1!!24!!Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:69.0) Gecko/20100101 Firefox/69.0!!1!!1!!1680!!1050!!1636!!1027!!1!!1!!1!!-1!!MacIntel!!1!!-8!!805a6cdeadd4f48ade985597f74928cb!!cc03697d39800df1ef0d2229132a62e8!!!!0!!-1!!0!!4!!AndaleMono,Arial,ArialBlack,ArialNarrow,ArialRoundedMTBold,ArialUnicodeMS,ComicSansMS,Courier,CourierNew,Geneva,Georgia,Helvetica,HelveticaNeue,Impact,LUCIDAGRANDE,MicrosoftSansSerif,Monaco,Palatino,Tahoma,Times,TimesNewRoman,TrebuchetMS,Verdana!!1568168747074!!-1,-1,-15,0,0,0,0,97,230,2,134245,8,7,441,444,992,3151782,3151782,3151970,-1!!-1!!-1!!577!!75!!49!!222!!75!!false!!false
RSA加的分析
单步步入跟进变量r的计算过程,由于方法是通过数组转义的,所以需要步入多次才能进入到正确的变量中,如下图:

到这里,需要分两步分析:
i. 待加密的内容92c689c0f4282f4e是什么,怎么得到的。
i. 跟进继续分析,看是否能得到RSA加密的公钥
这里备份一下加密的结果:
031d0a23604ba7778905403f8403e780224cdfa6854551f55d2efd84436434df3579139c391d0b34d2ff91cbb29bf24902cf2dc1b03e165db3601d5f6cdbb6a1f1ef81f03b8085c5606671b50f22db362f8ddfec89551f163f96e84b1e22387b6e229fe1ab2ab76f8dcc2a8a15b840ebad8c75b7afbf126f2b6f33f478774e8d
待加密的那串字符串已经执行过了,需要再重新启动调试分析,所以这里不打断本次调试,继续分析RSA的公钥,如下图:
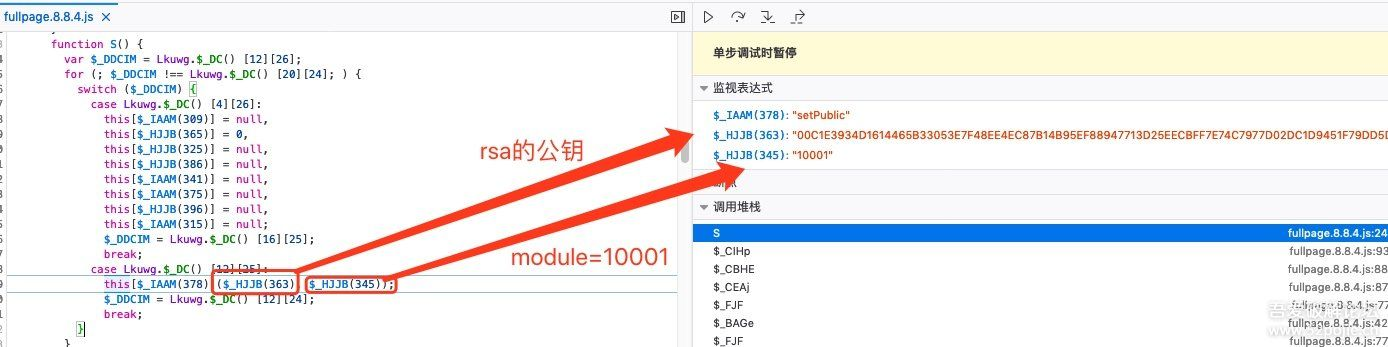
得到的RSA的公钥信息为:
publicExponent = 10001
publicKey = 00C1E3934D1614465B33053E7F48EE4EC87B14B95EF88947713D25EECBFF7E74C7977D02DC1D9451F79DD5D1C10C29ACB6A9B4D6FB7D0A0279B6719E1772565F09AF627715919221AEF91899CAE08C0D686D748B20A3603BE2318CA6BC2B59706592A9219D0BF05C9F65023A21D2330807252AE0066D59CEEFA5F2748EA80BAB81
至此,RSA加密需要的信息我们分析完毕,模拟RSA加密的python代码如下:
import rsa from binascii import b2a_hex e = '010001' e = int(e, 16) n = '00C1E3934D1614465B33053E7F48EE4EC87B14B95EF88947713D25EECBFF7E74C7977D02DC1D9451F79DD5D1C10C29ACB6A9B4D6FB7D0A0279B6719E1772565F09AF627715919221AEF91899CAE08C0D686D748B20A3603BE2318CA6BC2B59706592A9219D0BF05C9F65023A21D2330807252AE0066D59CEEFA5F2748EA80BAB81' n = int(n, 16) pub_key = rsa.PublicKey(e=e, n=n) print(b2a_hex(rsa.encrypt(b"0fe524023c414bb5", pub_key)))
AES加密的分析
继续单步步入AES加密的方法之前,意外发现了上下文变量中的信息,如下图:

至此,我们知道上面遗留待分析的字符串: 92c689c0f4282f4e, 是AES加密用的Key。一会儿代码中证实一下。
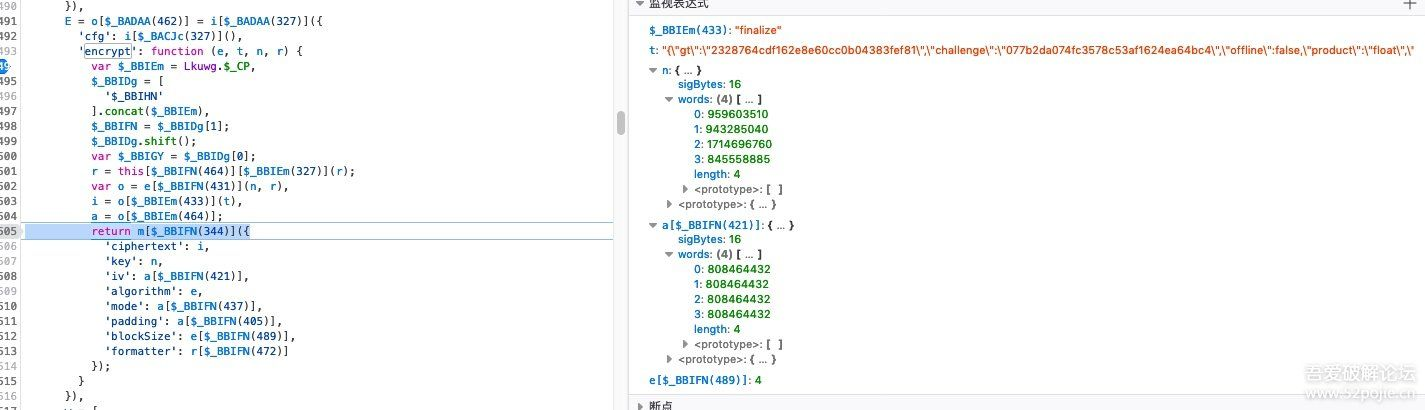
由上图可知,
a. key=n: 密钥key,对应的值: 959603510..., 转换为十六进制为: 0x39326336...,对应的ascii为: 92c6..., 说明上面的字符串确实是AES加密用的key。
b. iv=a[$_BBIFN(344)]; 补位值, 对应的值是: 808464432..., 转换为十六进制为: 0x30303030...,说明补位以字符0000000000000000补齐
c. mode=a[$_BBIFN(344)]; 加密模式,分析可知是CBC模式的加密
d. blockSize=4; 切分区块大小为4字节
e. ciphertext=i; 序列化后的代加密字符,原文是t,下面记录下代加密的原文内容:
{ "gt": "2328764cdf162e8e60cc0b04383fef81", "challenge": "960780255cdadcbdebde1fb646d5cb77", "offline": false, "product": "float", "width": "100%", "lang": "zh-hk", "protocol": "https://", "fullpage": "/static/js/fullpage.8.8.4.js", "beeline": "/static/js/beeline.1.0.1.js", "static_servers": ["static.geetest.com/", "dn-staticdown.qbox.me/"], "slide": "/static/js/slide.7.6.3.js", "maze": "/static/js/maze.1.0.1.js", "aspect_radio": { "click": 128, "pencil": 128, "beeline": 50, "voice": 128, "slide": 103 }, "voice": "/static/js/voice.1.2.0.js", "pencil": "/static/js/pencil.1.0.3.js", "type": "fullpage", "click": "/static/js/click.2.8.5.js", "geetest": "/static/js/geetest.6.0.9.js", "cc": 4, "ww": true, "i": "46207!!219363!!CSS1Compat!!334!!-1!!-1!!-1!!-1!!1!!-1!!-1!!9!!60!!45!!9!!15!!-1!!-1!!-1!!-1!!-1!!1!!-1!!-1!!231!!2!!-1!!-1!!-1!!157!!23!!44!!23!!1396!!279!!1396!!877!!zh-CN!!zh-CN,zh,zh-TW,zh-HK,en-US,en!!-1!!1!!24!!Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:69.0) Gecko/20100101 Firefox/69.0!!1!!1!!1680!!1050!!1636!!1027!!1!!1!!1!!-1!!MacIntel!!1!!-8!!805a6cdeadd4f48ade985597f74928cb!!cc03697d39800df1ef0d2229132a62e8!!!!0!!-1!!0!!4!!AndaleMono,Arial,ArialBlack,ArialNarrow,ArialRoundedMTBold,ArialUnicodeMS,ComicSansMS,Courier,CourierNew,Geneva,Georgia,Helvetica,HelveticaNeue,Impact,LUCIDAGRANDE,MicrosoftSansSerif,Monaco,Palatino,Tahoma,Times,TimesNewRoman,TrebuchetMS,Verdana!!1568168747074!!-1,-1,-15,0,0,0,0,97,230,2,134245,8,7,441,444,992,3151782,3151782,3151970,-1!!-1!!-1!!577!!75!!49!!222!!75!!false!!false" }
至此,AES加密分析结束,整理的python代码如下:
import base64 from Crypto.Cipher import AES from binascii import b2a_hex, a2b_hex class PrpCrypt(object): def __init__(self, key): self.key = key.encode('utf-8') self.mode = AES.MODE_CBC # 加密函数,如果text不足16位就用空格补足为16位, # 如果大于16当时不是16的倍数,那就补足为16的倍数。 def encrypt(self, text): text = text.encode('utf-8') cryptor = AES.new(self.key, self.mode, b'0000000000000000') # 这里密钥key 长度必须为16(AES-128), # 24(AES-192),或者32 (AES-256)Bytes 长度 # 目前AES-128 足够目前使用 length = 16 count = len(text) if count < length: add = (length - count) # \0 backspace # text = text + ('\0' * add) text = text + ('0' * add).encode('utf-8') elif count > length: add = (length - (count % length)) # text = text + ('\0' * add) text = text + ('0' * add).encode('utf-8') self.ciphertext = cryptor.encrypt(text) # 因为AES加密时候得到的字符串不一定是ascii字符集的,输出到终端或者保存时候可能存在问题 # 所以这里统一把加密后的字符串转化为16进制字符串 return b2a_hex(self.ciphertext) # 解密后,去掉补足的空格用strip() 去掉 def decrypt(self, text): cryptor = AES.new(self.key, self.mode, b'0000000000000000') plain_text = cryptor.decrypt(a2b_hex(text)) # return plain_text.rstrip('\0') return bytes.decode(plain_text).rstrip('\0') if __name__ == '__main__': txt = "{\"gt\":\"2328764cdf162e8e60cc0b04383fef81\",...}" pc = PrpCrypt('92c689c0f4282f4e') # 初始化密钥 e = pc.encrypt(txt) # 加密 d = pc.decrypt(e) # 解密 print("加密:", e) print("解密:", d)
后记
对比发现,之前记录的e的值,就是这里待加密内容中 i的值。gt 和 challenge可以从上一章的分析中得到,AES加密之后,将加密的结果base64编码处理。
至此,我们知道,其大致的交互方式为:
- 用时间戳生成AES的密钥,并将密钥通过RSA加密。
- 通过AES+密钥将要提交的内容加密。
- 将提交内容的密文与密钥的密文拼接成w参数进行提交,
w参数的格式为:base64(aes(json))+rsa(aes的密钥)
本章遗留了如下两个问题:
- AES的密钥如何生成。
- e的值是什么内容,如何计算得到。
限于篇幅,这两个问题,待到下一篇《极验反爬虫防护分析之接口交互的解密方法补遗》 中进行分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号