


Datawhale 之NLP学习-打卡(二)
Task2 数据读取与数据分析
1.学习目标
- 学习使用Pandas读取赛题数据
- 分析赛题数据的分布规律
2.数据读取
-
代码示例:
import pandas as pd file_dir = "nlp_data_list" train_df = pd.read_csv("./{}/train_set.csv".format(file_dir),sep='\t',nrows=100) -
代码分析:
读取的文件路径可修改成你实际使用的本地路径;
sep 指每列的分隔符,默认是“,”,此文件中是“\t”;
nrows 指读取行数。 -
代码结果:
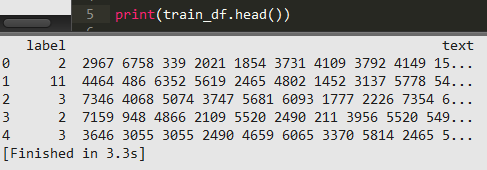
label列为新闻的类别,text列为新闻的字符
3.数据分析
-
句子长度分析
-
代码示例
train_df['text_len'] = train_df['text'].apply(lambda x:len(x.split(' '))) print(train_df['text_len'].describe()) -
代码结果
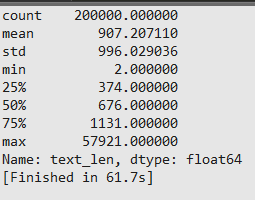
通过统计可得出,每个句子平均有907个字符构成,最短的句子长度为2,最长的句子长度为57921 -
绘制直方图
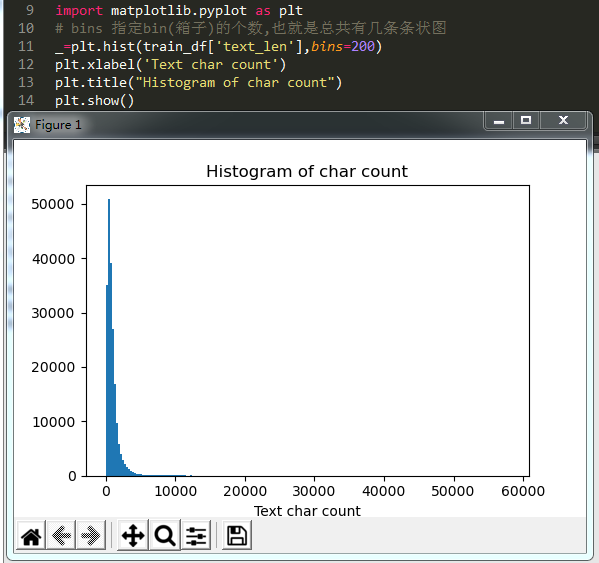
-
-
新闻类别分布
-
代码示例
train_df['label'].value_counts().plot(kind='bar') plt.title('News class count') plt.xlabel("category") plt.show() -
代码结果
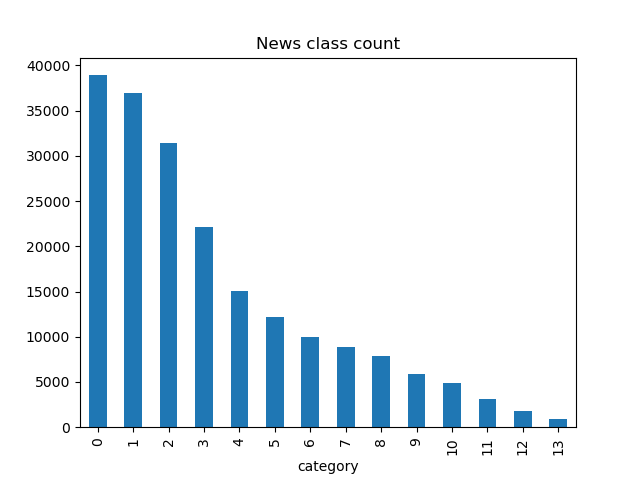
数据集中标签的对应关系如下: -
结果分析
赛题的数据集类别分布存在较为不均匀的情况。在训练集中科技类类新闻最多,其次是股票类新闻,最多的是星座类新闻
-
-
字符分布统计
- 统计每个字符出现的次数
from collections import Counter all_lines = ' '.join(list(train_df['text'])) word_count = Counter(all_lines.split(" ")) word_count = sorted(word_count.items(),key=lambda d:d[1], reverse=True) print("len(word_count)=",len(word_count)) print("word_count[0]=",word_count[0]) print("word_count[-1]=",word_count[-1]) - 统计字符在每个句子的出现情况,反推出标点符号
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' '))))) all_lines = ' '.join(list(train_df['text_unique'])) word_count = Counter(all_lines.split(" ")) word_count = sorted(word_count.items(),key=lambda d:d[1], reverse=True) print("word_count[0]=",word_count[0]) print("word_count[1]=",word_count[1]) print("word_count[2]=",word_count[2])
- 统计每个字符出现的次数
4.数据分析的结论
- 赛题中每个新闻包含的字符个数平均为1000个,还有一些新闻字符较长
- 赛题中新闻类别分布不均,科技类新闻样本接近4w,星座类新闻样本量不到1k
- 赛题总共包括7000-8000个字符
5.本章小结
- 对赛题数据进行读取,并对新闻句子长度、类别和字符进行了可视化分析
6.本章作业
-
假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成
(待更新) -
统计每类新闻中出现次数最多的字符
(待更新)

