SpringCloud Alibaba Seata---处理分布式事务
前言:不断学习就是程序员的宿命
一、Seata概述
1、背景
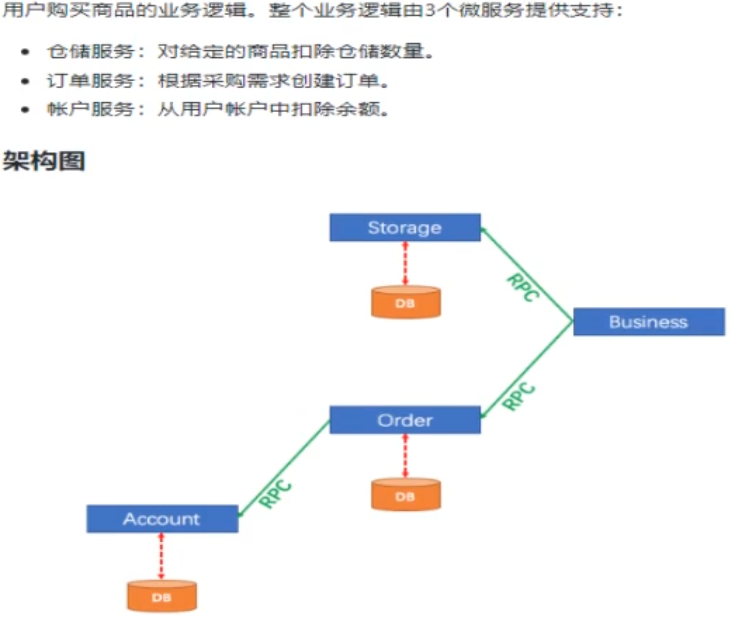
单体应用被拆分成微服务应用,原来的三个模块被拆分成三个独立的应用,分别使用不同的数据源,业务操作需要调用三个服务来完成。此时每个服务内部的数据一致性由本地事务来保证,但是全局的数据一致性问题没法保证。
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
2、一个典型的分布式事务过程(1+3)-分布式事务处理过程的一个ID+三组件模型:
(1)Transaction ID XID:全局唯一的事务ID
(2)三组概念:
①Transaction Coordinator(TC事务协调器):维护全局和分支事务状态,驱动全局事务提交或回滚
②Transaction Manager(TM事务管理器):控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议
③Resource Manager(RM资源管理器):控制分支事务,负责分支注册、状态汇报,并接受事务协调的指令,驱动分支(本地)事务的提交和回滚
3、Seata处理过程

①TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID;
②XID在微服务调用链路的上下文传播
③RM向TC注册分支事务,将其纳入XID对应全局事务的管辖
④TM向TC发起针对XID的全局提交或回滚决议;
⑤TC调度XID下管辖的全部分支事务完成提交或回滚事务
二、Seata分布式交易解决方案
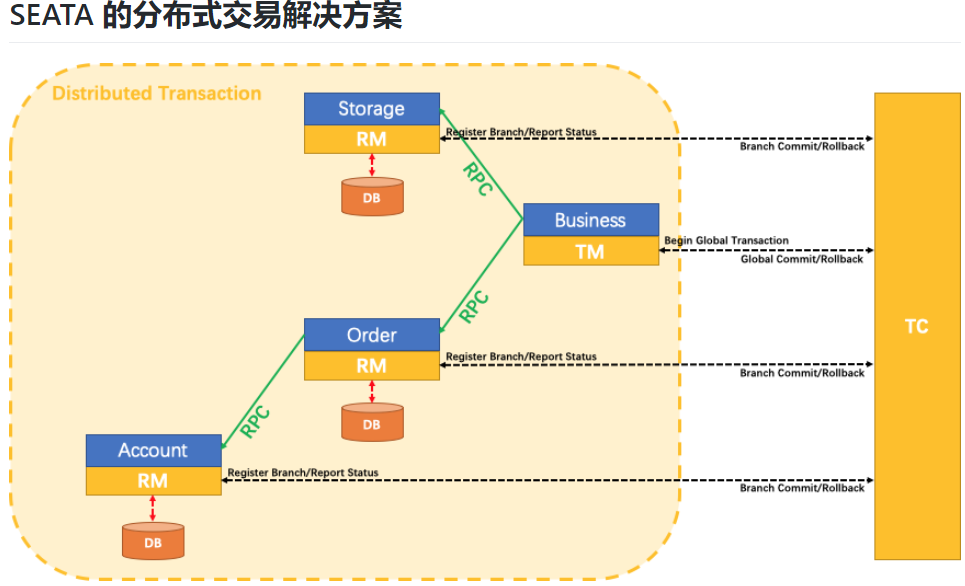
案例需求:下订单-->扣库存--->减账户余额---->修改订单状态
环境准备:3个数据库(订单库、库存库、账户库)、3个微服务(订单、库存、账户服务)
当用户下单时,会在订单服务中创建一个订单,然后通过远程调用库存服务来扣减下单商品的库存。再通过远程调用账户服务来扣减账户余额,最后在订单服务中修改订单状态为已完成。该操作跨越三个数据库,有两次远程调用,很明显会有分布式事务问题。
三、Seata-Server安装
下载地址:https://github.com/seata/seata/releases
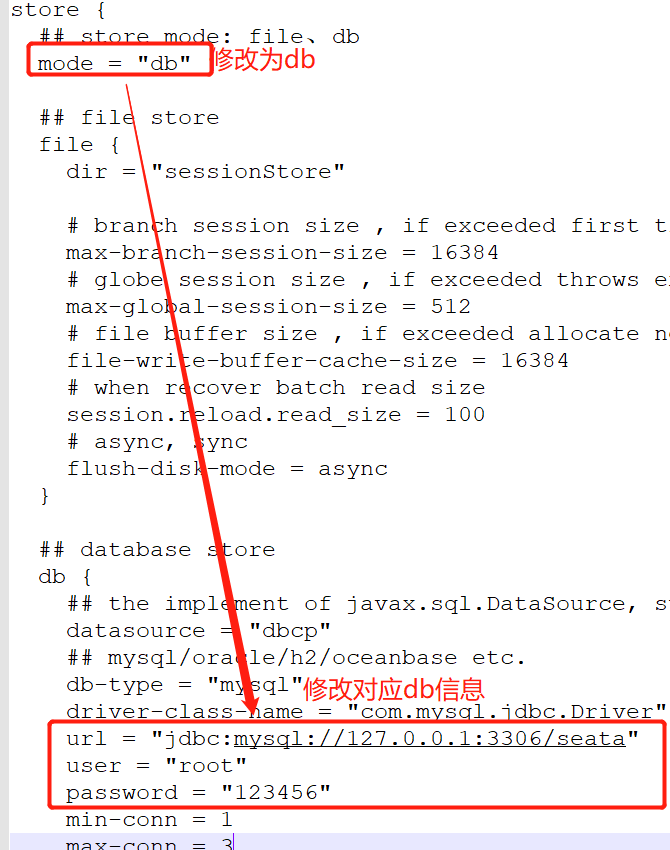
1、修改file.conf
主要修改:自定义事务组名称+事务日志存储模式为db+数据连接信息(ps:记得备份file.conf)
1.1 service模块

1.2store模块
2、数据库初始化
新建数据库seata,执行初始表sql位置:/seata/conf/db_store.sql

3、修改registry.conf

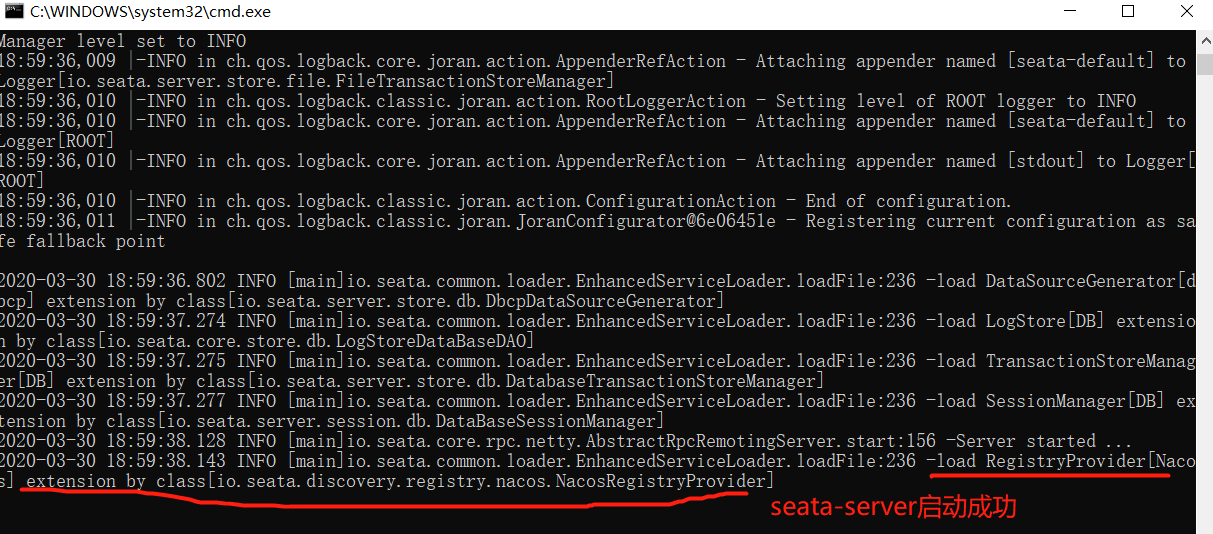
4、分别启动Nacos、seata-server
四、数据库初始化
①seata_order:存储订单数据库;
②seata_storage:存储库存数据;
③seata_account:存储账户信息数据库;


---seata biz create database seata_order; USE seata_order; CREATE TABLE `t_order` ( `int` bigint(11) NOT NULL AUTO_INCREMENT, `user_id` bigint(20) DEFAULT NULL COMMENT '用户id', `product_id` bigint(11) DEFAULT NULL COMMENT '产品id', `count` int(11) DEFAULT NULL COMMENT '数量', `money` decimal(11, 0) DEFAULT NULL COMMENT '金额', `status` int(1) DEFAULT NULL COMMENT '订单状态: 0:创建中 1:已完结', PRIMARY KEY (`int`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '订单表' ROW_FORMAT = Dynamic; CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; create database seata_storage; USE seata_storage; DROP TABLE IF EXISTS `t_storage`; CREATE TABLE `t_storage` ( `int` bigint(11) NOT NULL AUTO_INCREMENT, `product_id` bigint(11) DEFAULT NULL COMMENT '产品id', `total` int(11) DEFAULT NULL COMMENT '总库存', `used` int(11) DEFAULT NULL COMMENT '已用库存', `residue` int(11) DEFAULT NULL COMMENT '剩余库存', PRIMARY KEY (`int`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '库存' ROW_FORMAT = Dynamic; INSERT INTO `t_storage` VALUES (1, 1, 100, 0, 100); CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; CREATE database seata_account; USE seata_account; DROP TABLE IF EXISTS `t_account`; CREATE TABLE `t_account` ( `id` bigint(11) NOT NULL COMMENT 'id', `user_id` bigint(11) DEFAULT NULL COMMENT '用户id', `total` decimal(10, 0) DEFAULT NULL COMMENT '总额度', `used` decimal(10, 0) DEFAULT NULL COMMENT '已用余额', `residue` decimal(10, 0) DEFAULT NULL COMMENT '剩余可用额度', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '账户表' ROW_FORMAT = Dynamic; INSERT INTO `t_account` VALUES (1, 1, 1000, 0, 1000); CREATE TABLE `undo_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `branch_id` bigint(20) NOT NULL, `xid` varchar(100) NOT NULL, `context` varchar(128) NOT NULL, `rollback_info` longblob NOT NULL, `log_status` int(11) NOT NULL, `log_created` datetime NOT NULL, `log_modified` datetime NOT NULL, `ext` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
1、建立对应3个数据库与对应的回滚日志表
(回滚日志表对应建表语句:/seata/conf/db_undo_log.sql)
2、初始数据

五、代码实现及测试
1、代码模块
2001服务为订单服务驱动业务
2002服务为库存服务
2003服务为账户服务

代码地址:
2、分布式事务测试
2.1正常情况测试
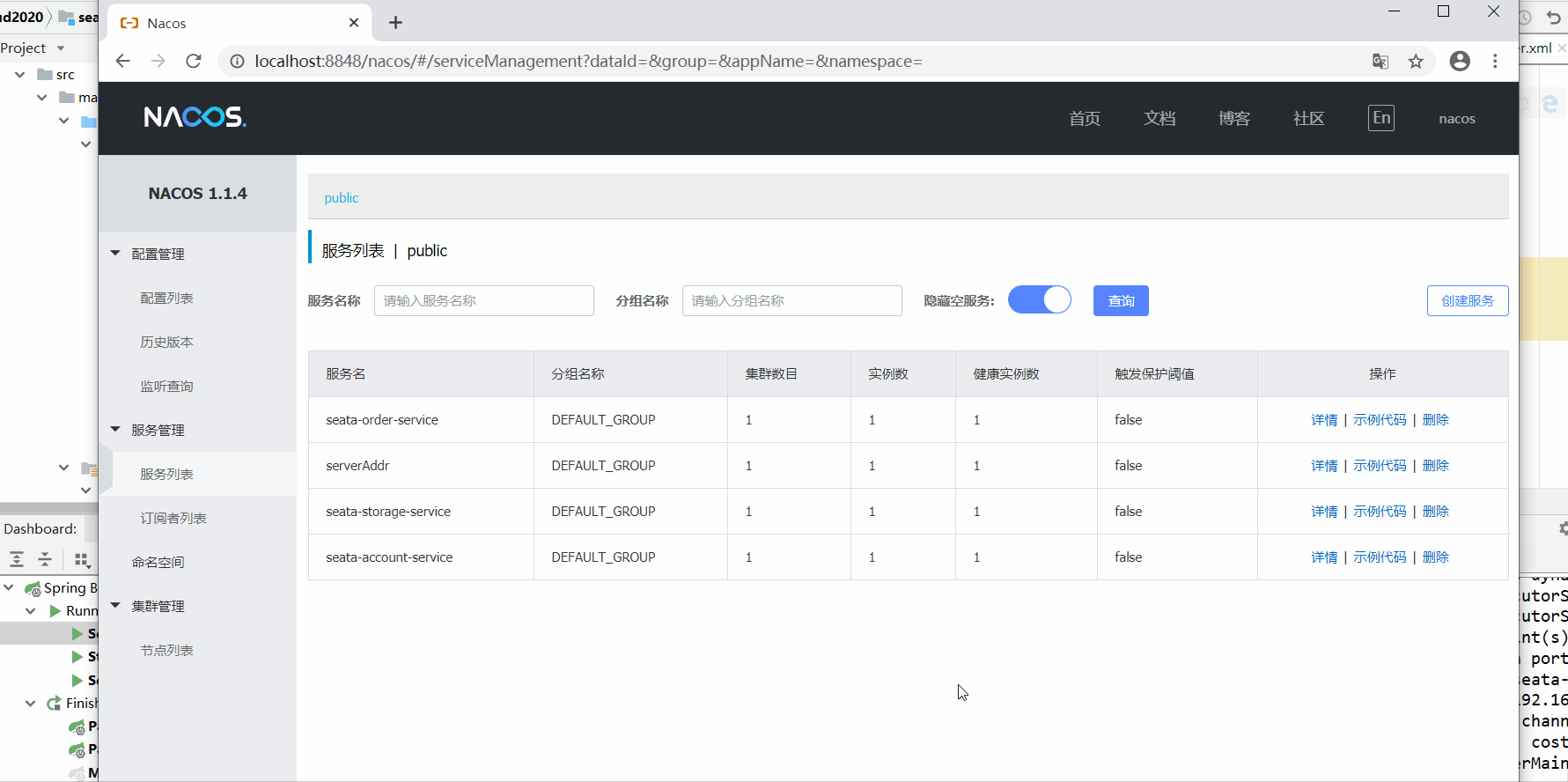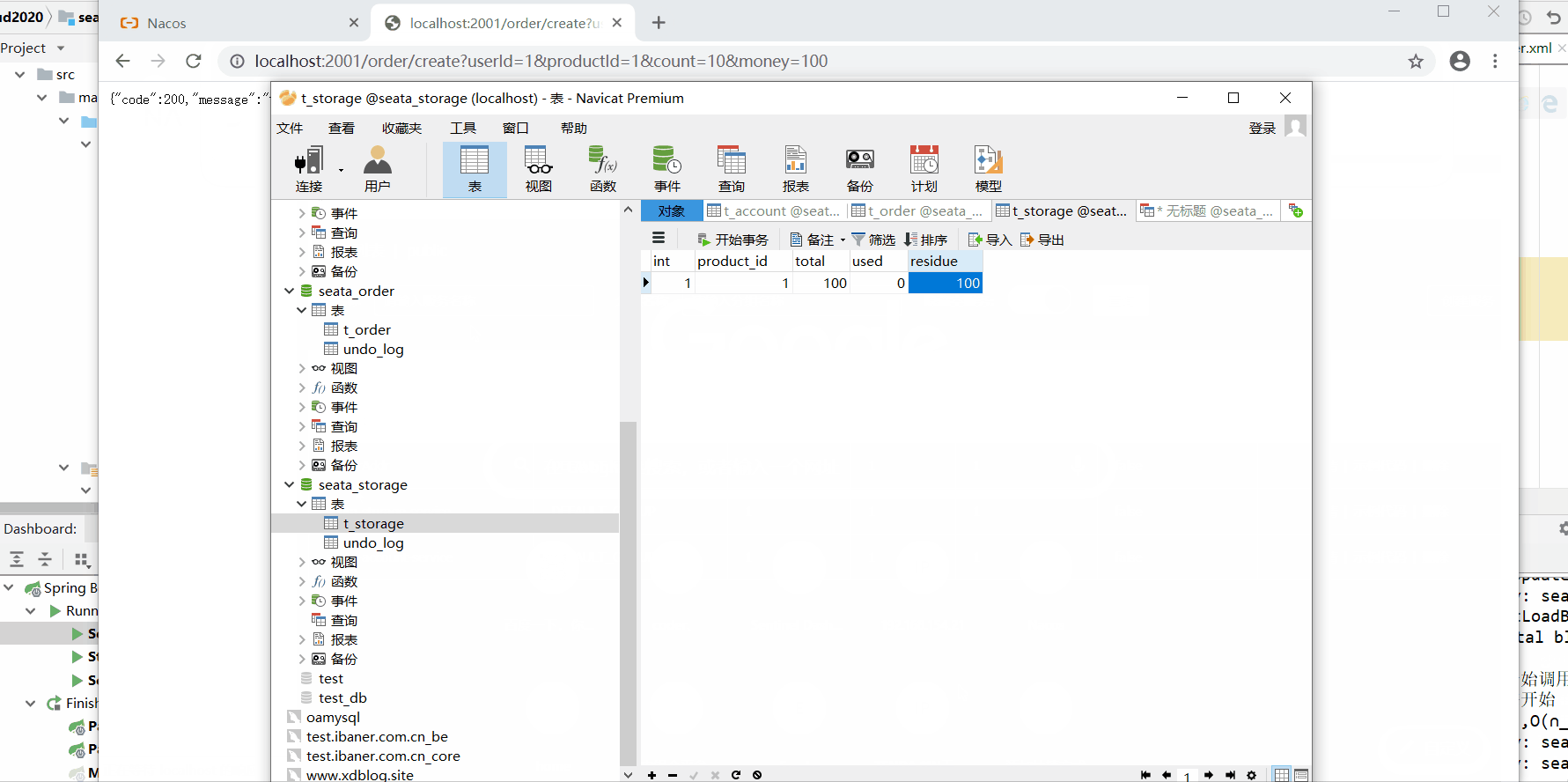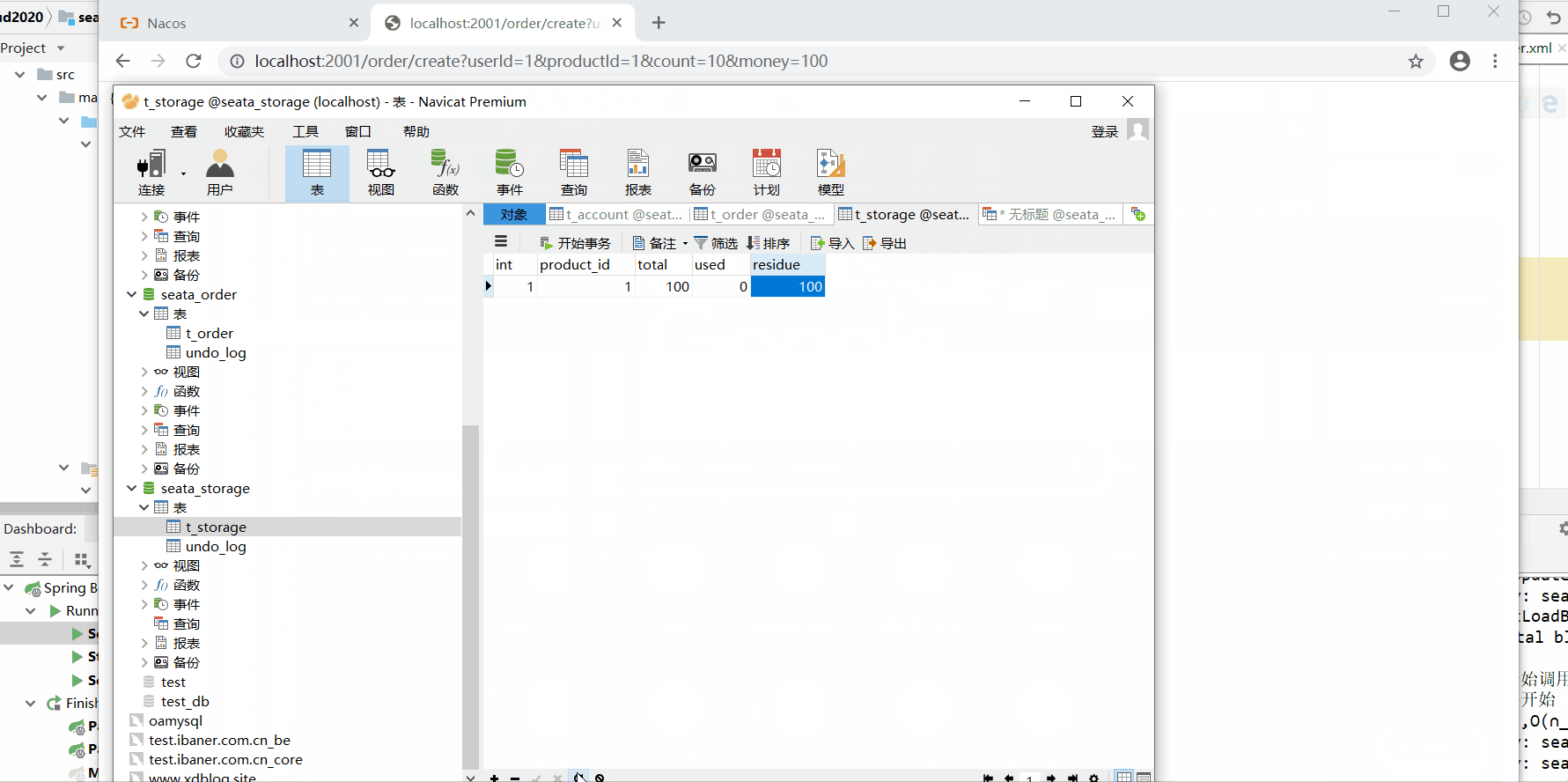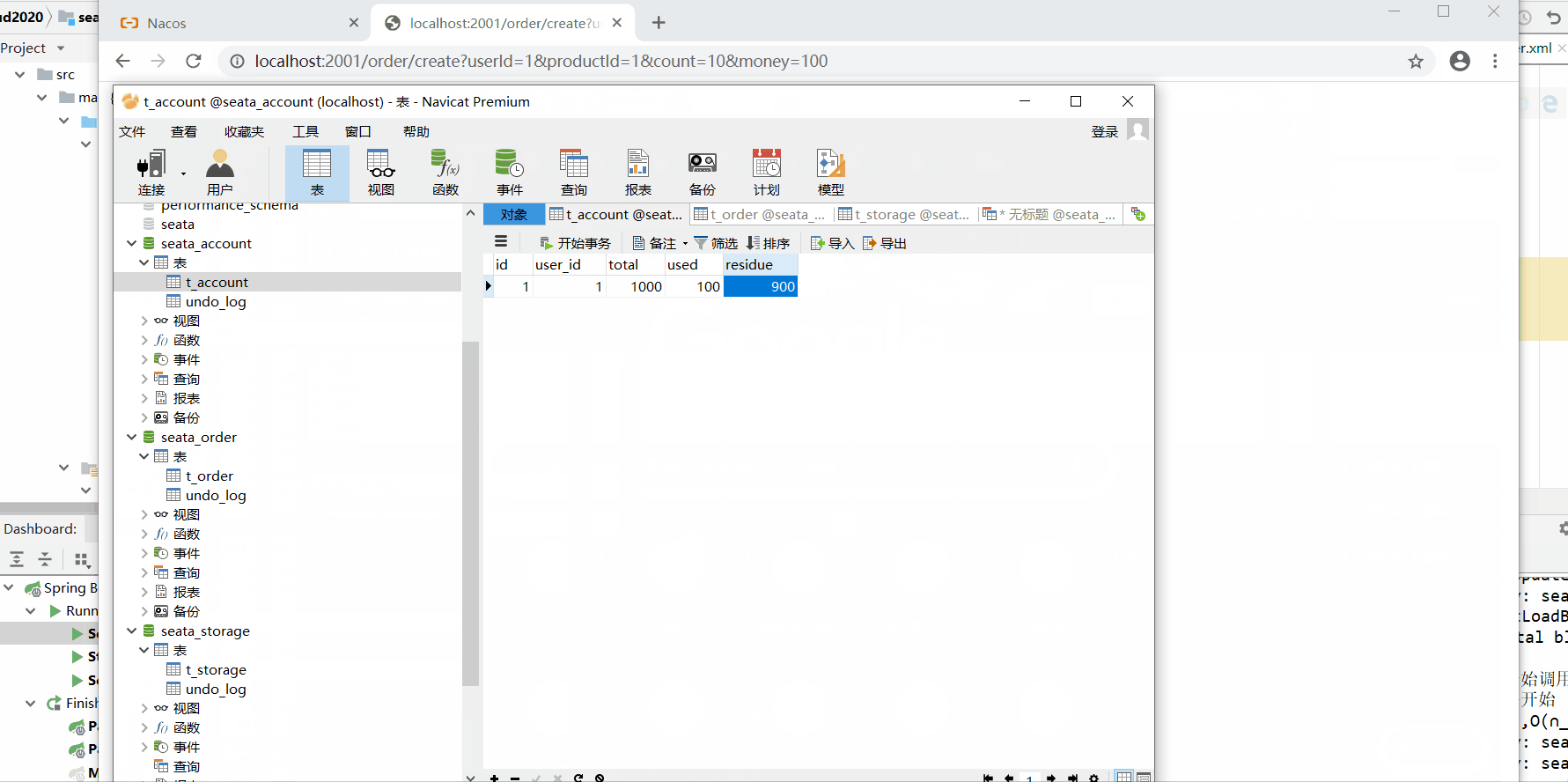
数据库情况:
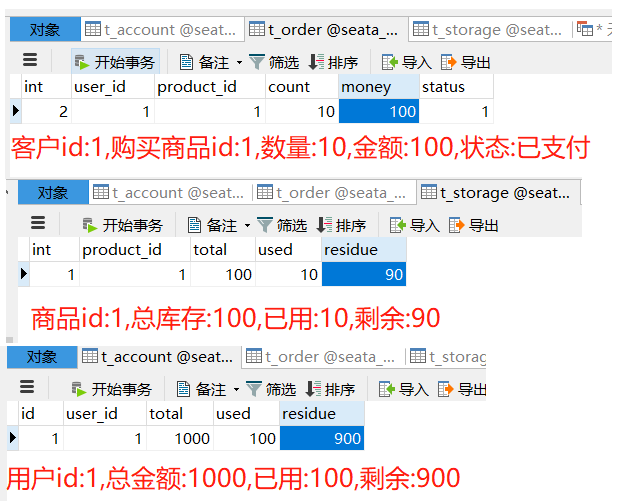
2.2不使用@GlobalTransactional注解超时异常测试
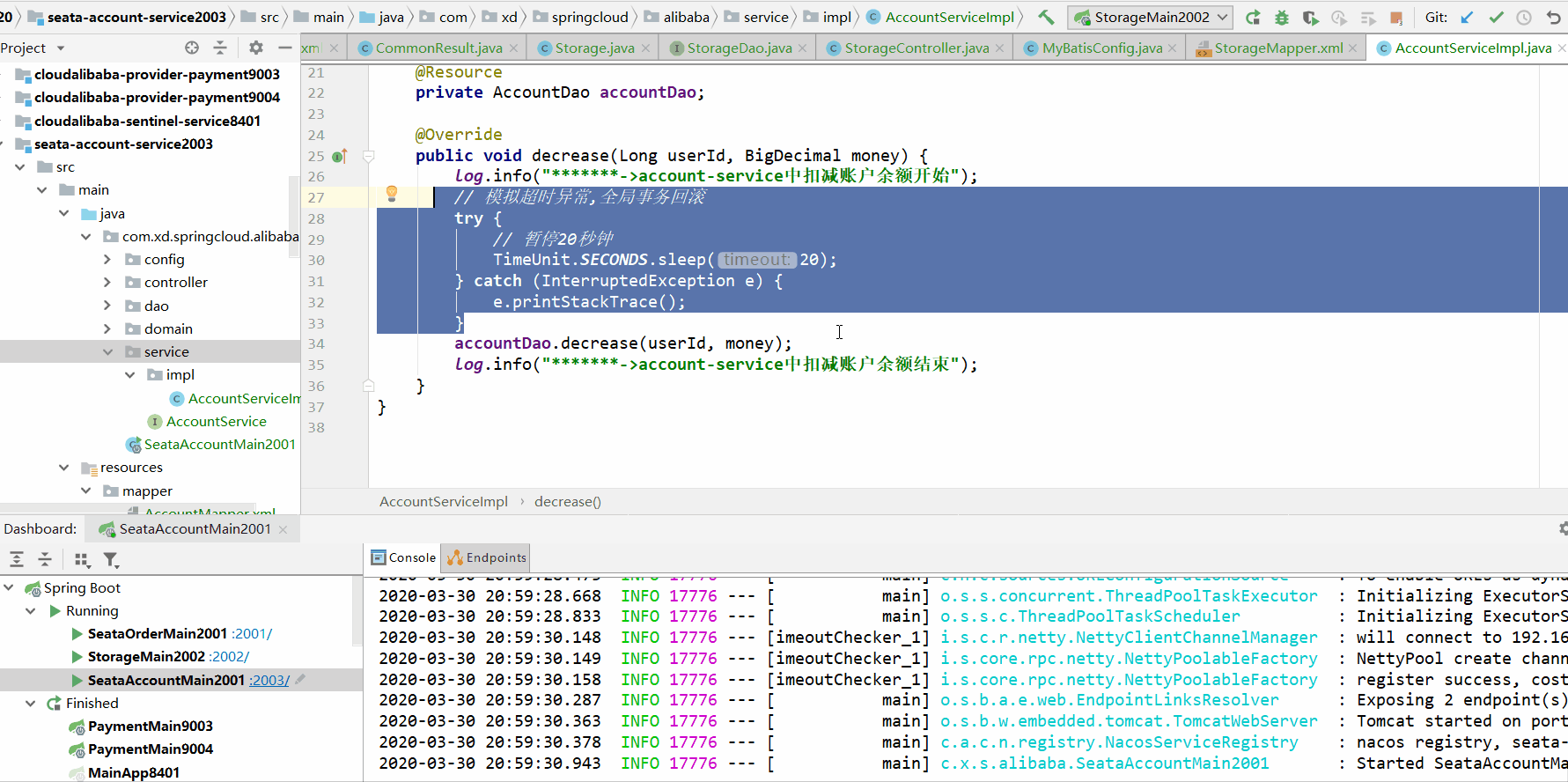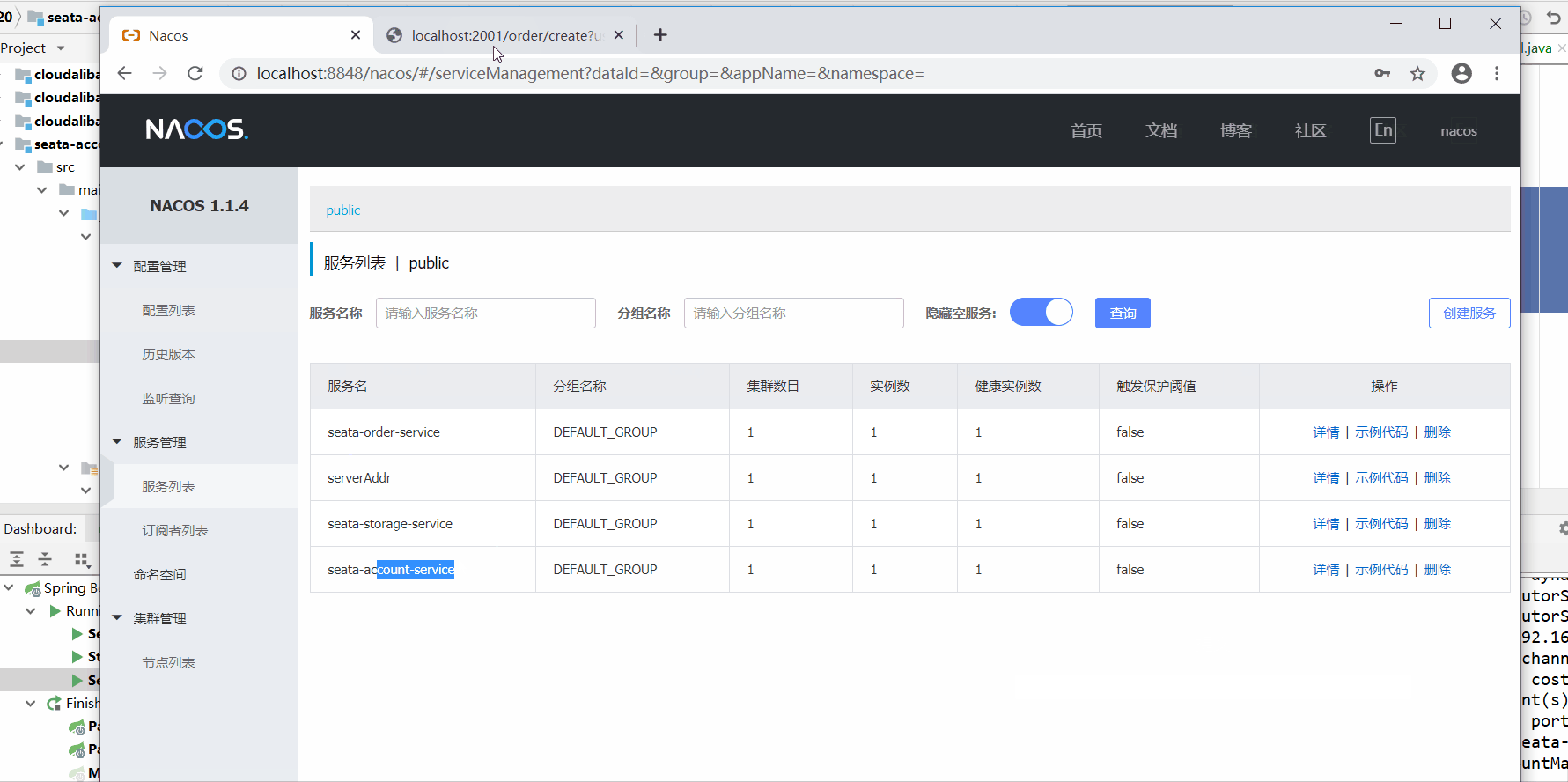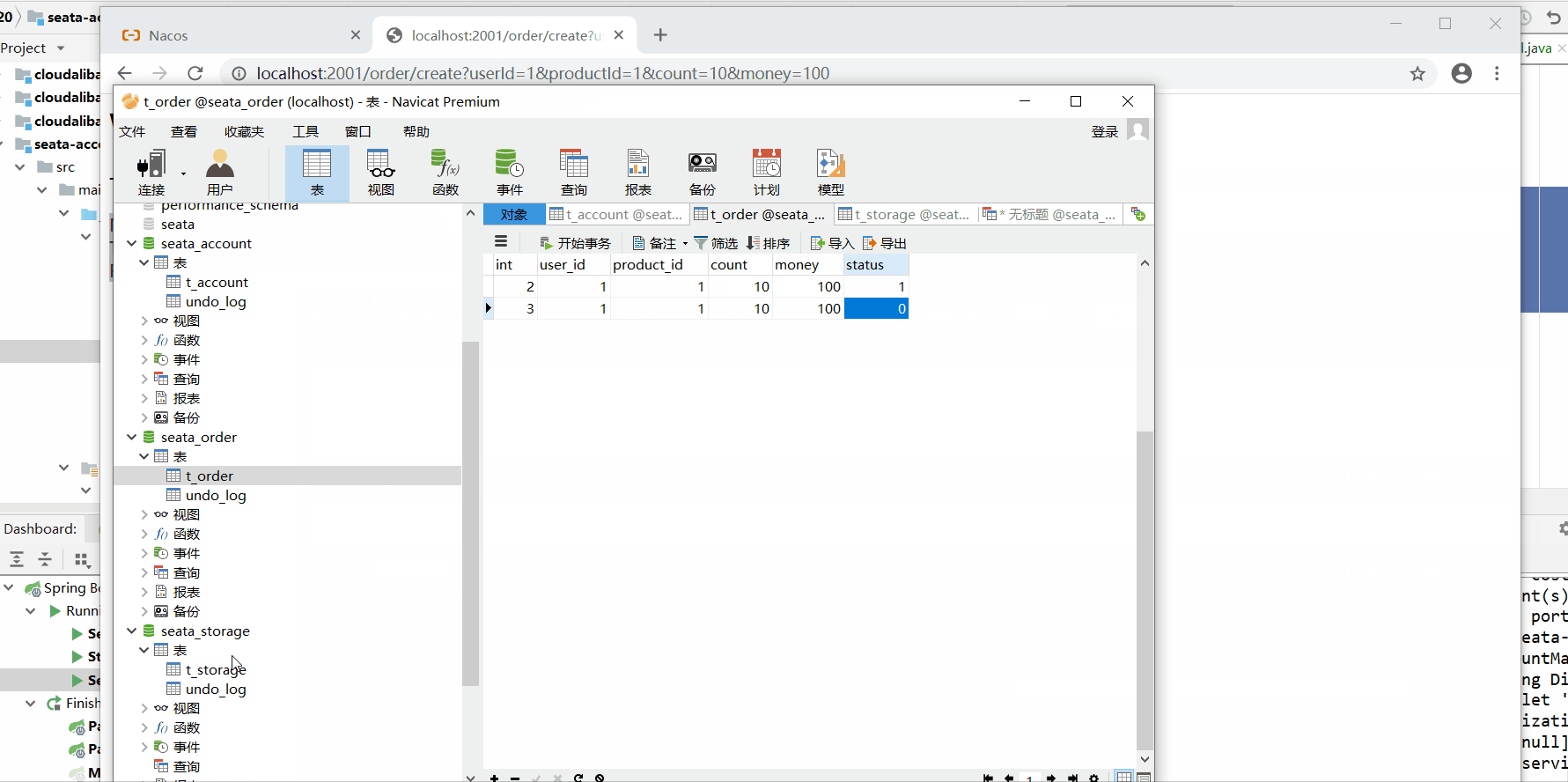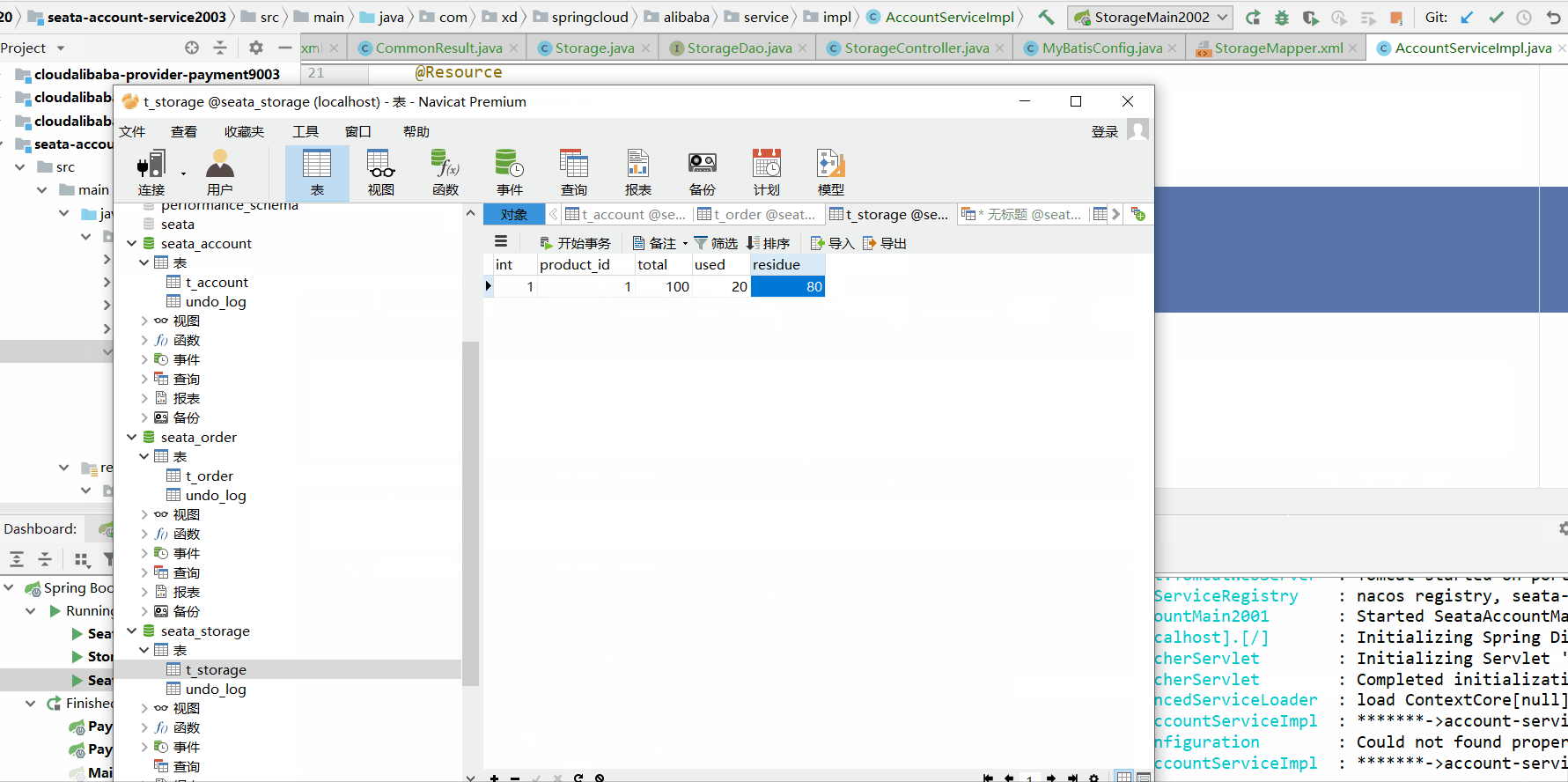
数据库情况:订单状态未支付但用户已扣钱且库存已减
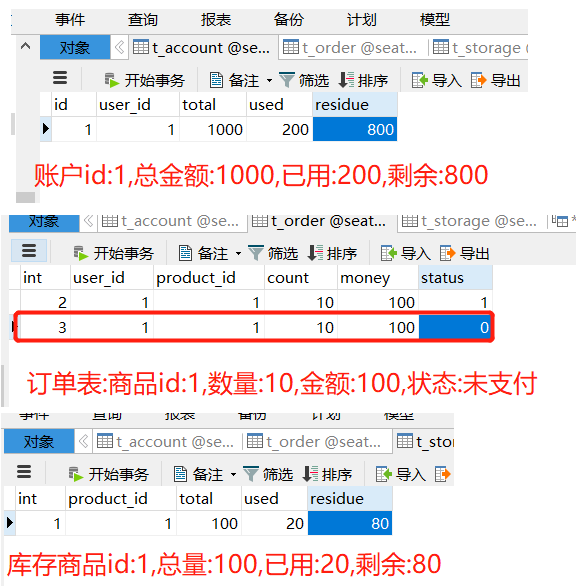
2.3使用@GlobalTransactional注解

测试情况:
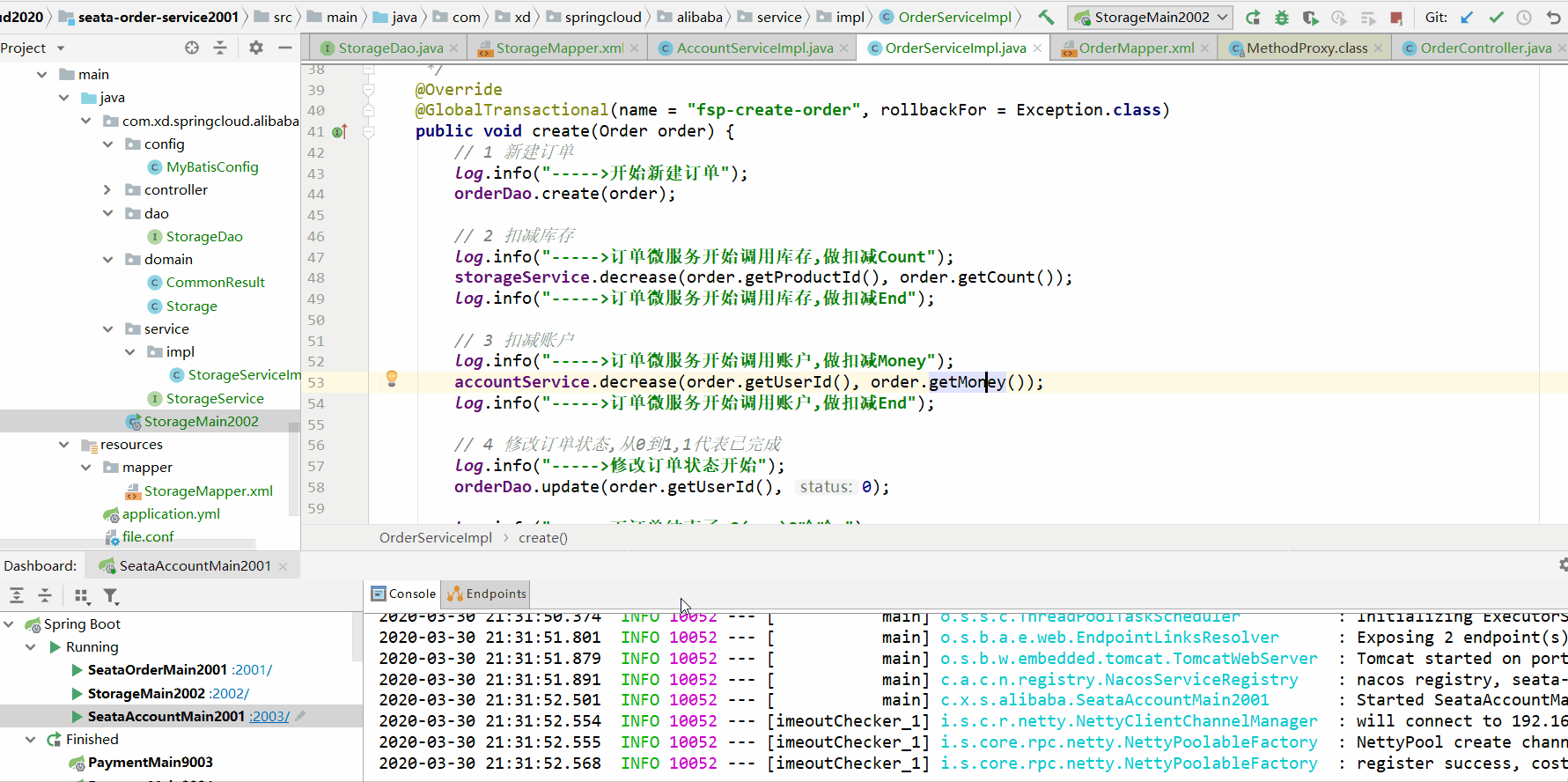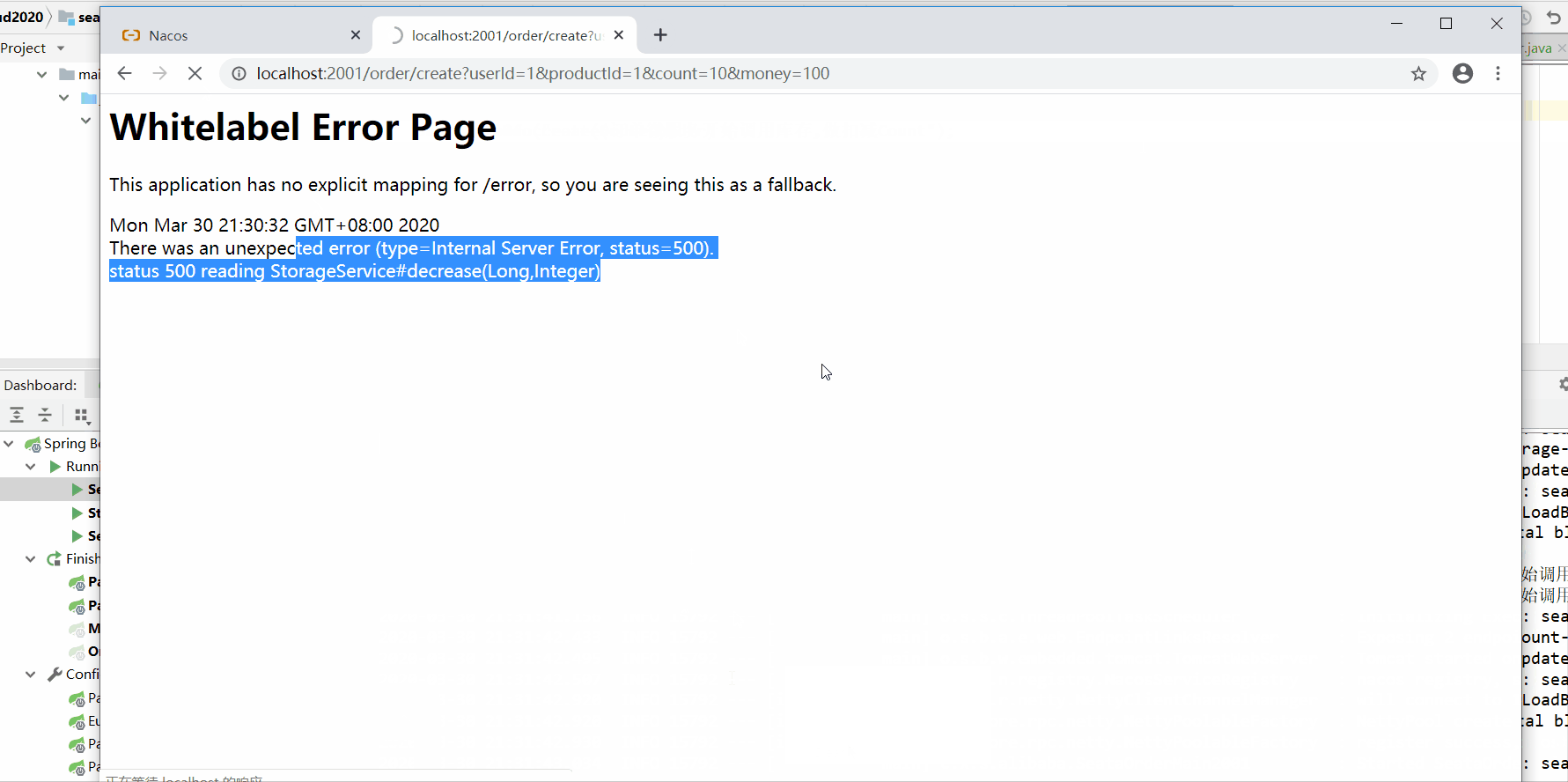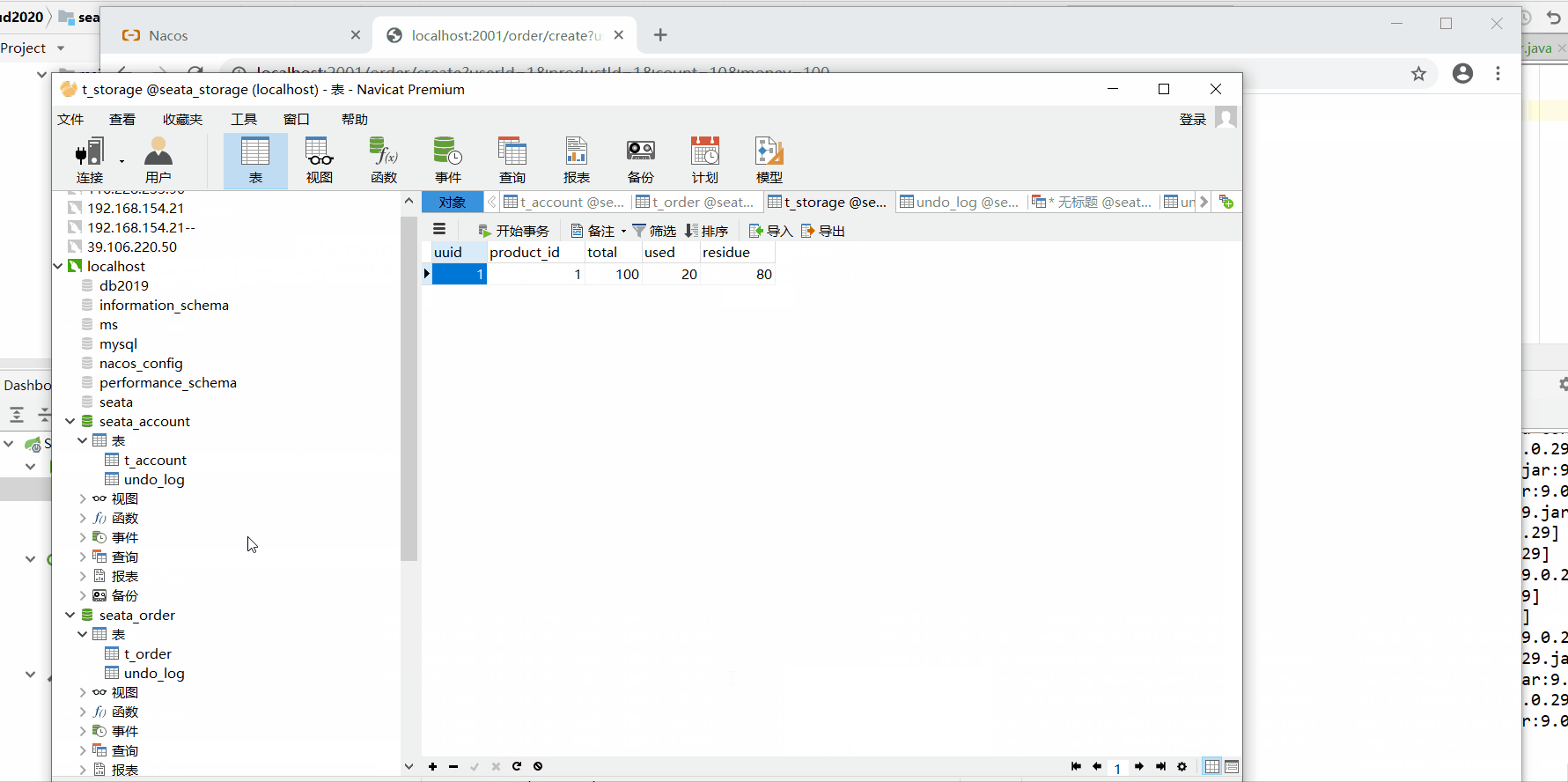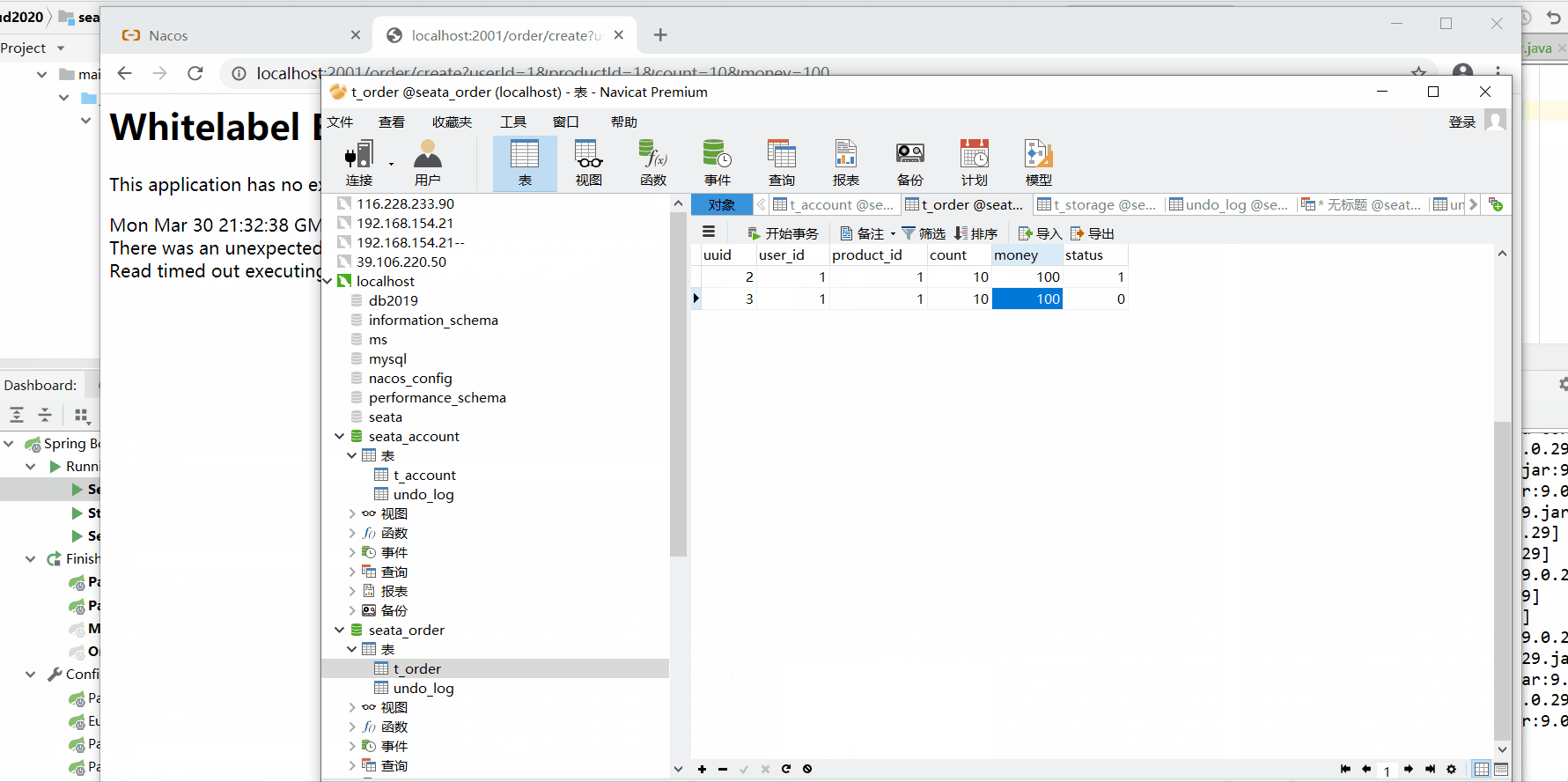
发现使用@GlobalTransactional注解后,数据库记录进行了回滚。实现了分布式事务
六、Seata原理简介
官网:http://seata.io/zh-cn/docs/dev/mode/at-mode.html(默认为AT模式)
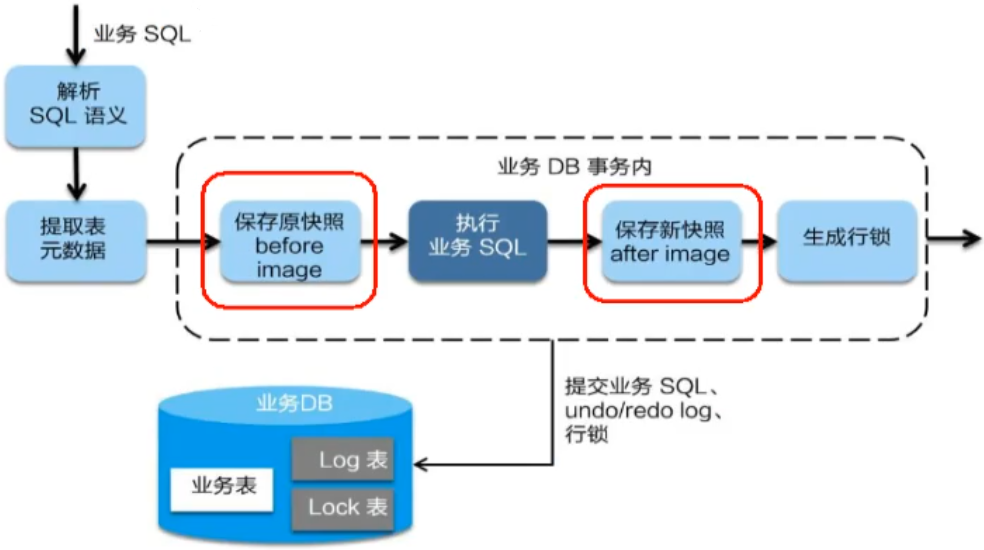
(1)一阶段加载
在一阶段,Seata会拦截“业务SQL”:
①解析SQL语义,找到“业务SQL”要更新的业务数据,在业务数据被更新之前,将其保存成“before image”
②执行“业务SQL”更新业务数据,在业务数据更新之后,将其生成“after image”
③生成行锁
以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
(2)二阶段提交
二阶段如果是顺利的话,因为“业务SQL”在一阶段已经提交至数据库,所以Seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
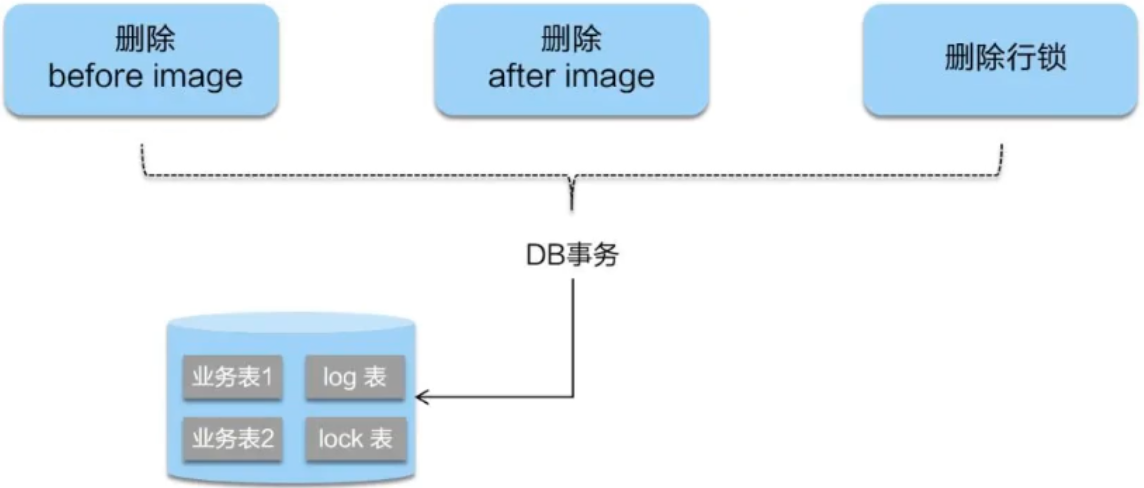
(3)二阶段回滚
二阶段如果回滚的话,Seata就需要回滚一阶段已执行的“业务SQL”,还原业务数据
回滚方式便是用“before image”还原业务数据;但在还原之前首先要校验脏写,对比“数据当前业务数据”和“after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明脏鞋,需要人工处理。
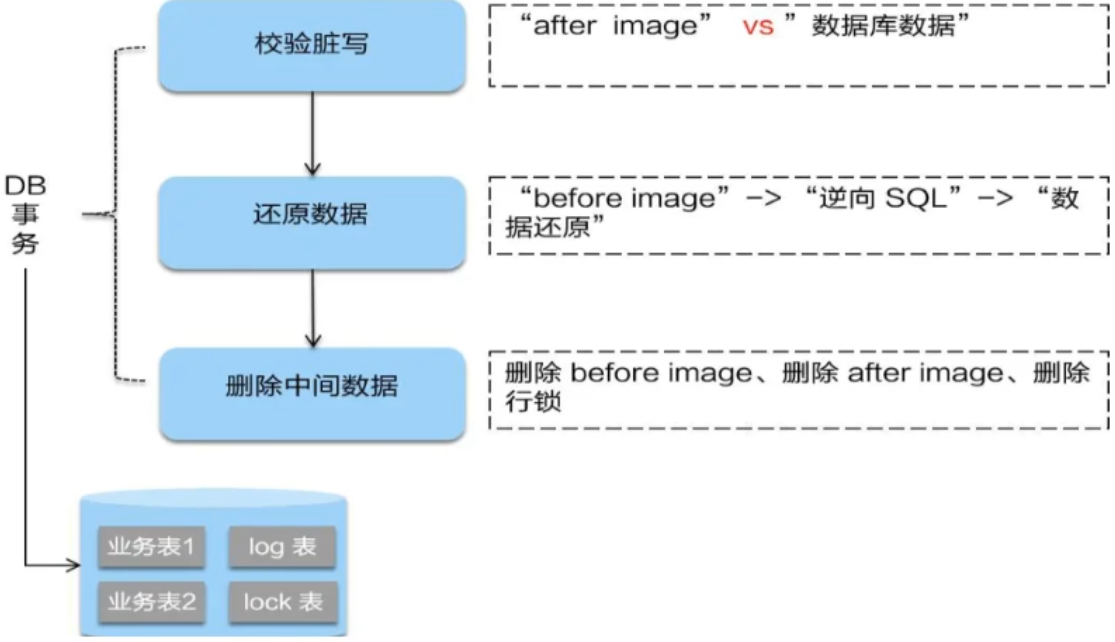
ps:总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号