Spark对接Kafka、HBase
本项目是为网站日志流量分析做的基础:网站日志流量分析系统,Kafka、HBase集群的搭建可参考:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),里面有关于该搭建过程
本次对接Kafka及HBase是基于使用Docker搭建Spark集群(用于实现网站流量实时分析模块)搭建的6个Docker容器来实现的对接。
代码地址:https://github.com/Simple-Coder/sparkstreaming-demo
一、SparkStreaming整合Kafka
1、maven代码

2、启动测试
2.1启动3个kafka并测试
生产端消息如下:

接收到的消息如下:
2.2spark提交jar任务,SparkStreaming消费Kafka消息
console-producer生产消息,spartkStreaming主动拉取消息,console-consumer也能收到消息,结果如下: 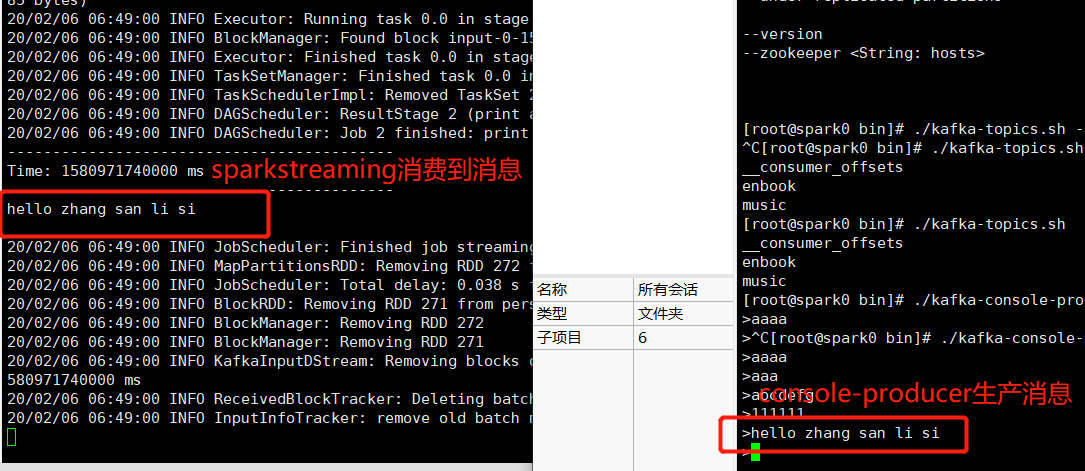
console-consumer接收到的消息如下:

至此、Spark对接Kafka完成
3、问题总结
KafkaUtils的选择,由于maven中央库只有1.6.3版本的spark-streaming-kafka,其他版本的spark-streaming-kafka-***的api调用个人不习惯,还是停留在之前的api,所以这可能是导致以下问题的所在,不过还好问题解决
①ClassNotFoundException: org.apache.kafka.common.utils.Utils:上传kafka-clients-0.8.2.0.jar至spark的jars目录
②java.lang.NoClassDefFoundError:org/apache/spark/streaming/kafka/KafkaUtils :上传kafka_2.11-0.8.2.1.jar、spark-streaming-kafka_2.11-1.6.3.jar至Spark的jars目录
③java.lang.NoClassDefFoundError:org/apache/spark/logging:开头maven结构图中,将工程jar上传至spark的jars目录
④NoClassDefFoundError: org/I0Itec/zkclient/serialize/ZkSerializer:上传zkclient-0.11.jar至spark的jars目录
二、SparkStreaming整合HBase
1、读取HBase表
1.1 scala代码

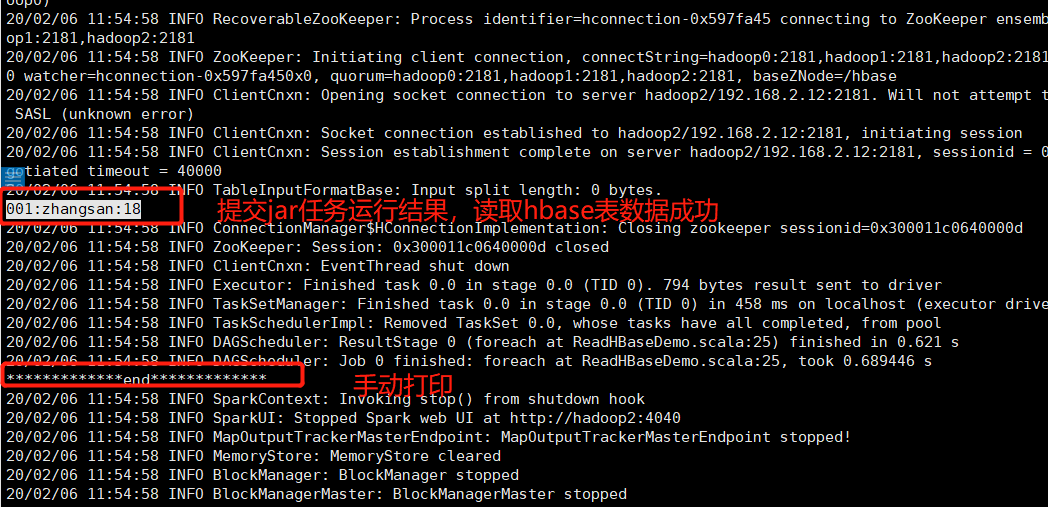
1.2 提交jar任务测试
由于是docker容器搭建的集群,本地不容易测试,只好提交jar至docker容器
提交任务截图如下:
HBase表t2数据如下:
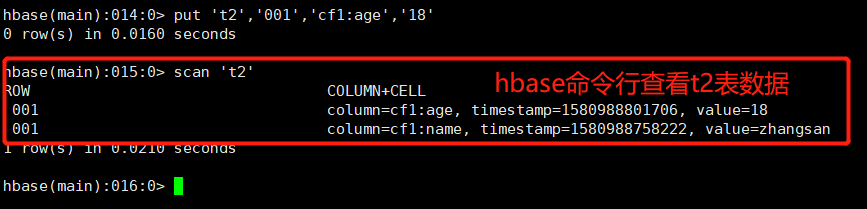
至此scala读取HBase数据成功,期间还是同样的问题,缺少关于HBase的jar,将maven依赖的HBase全部上传至Spark的jars目录下即可。
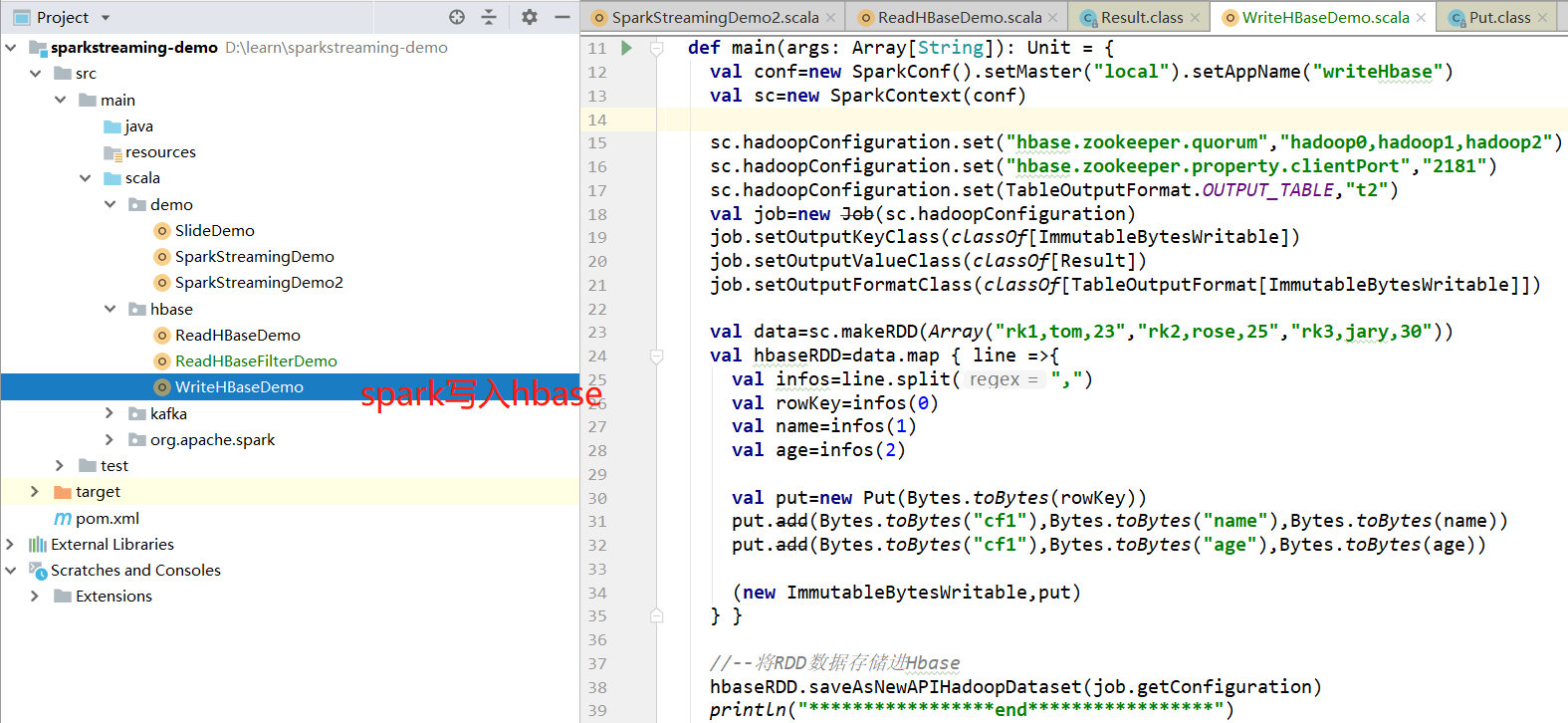
2、写入HBase表
2.1 scala代码
2.2 提交jar任务至spark测试
提交jar任务如下:
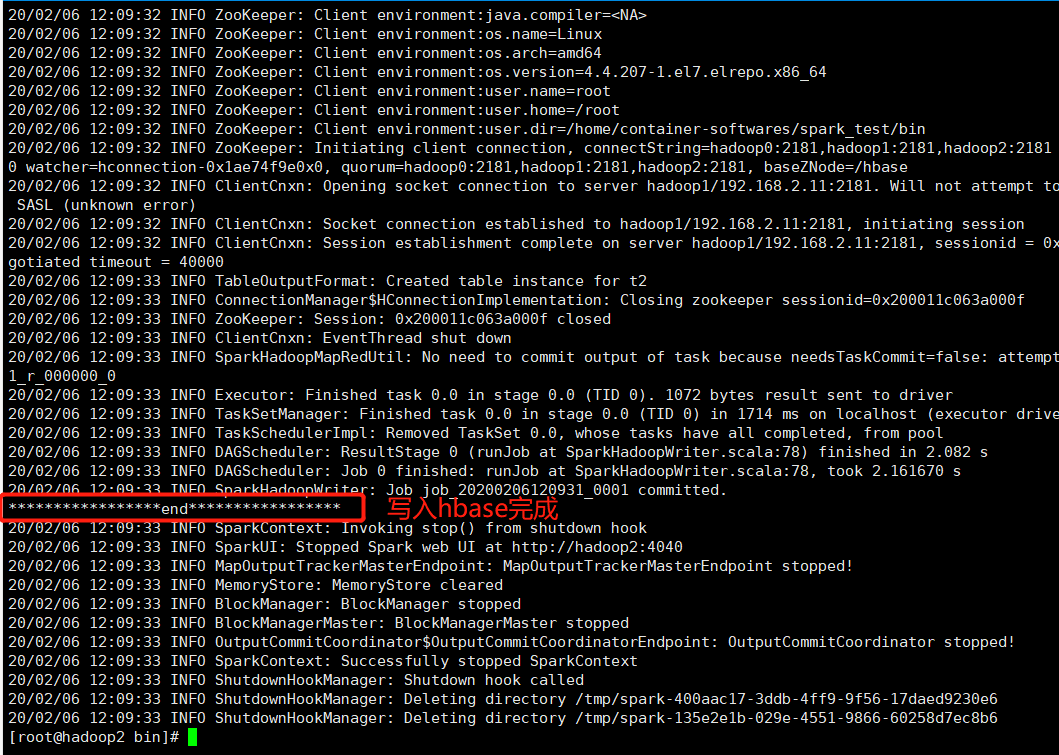
HBase命令行查看如下:
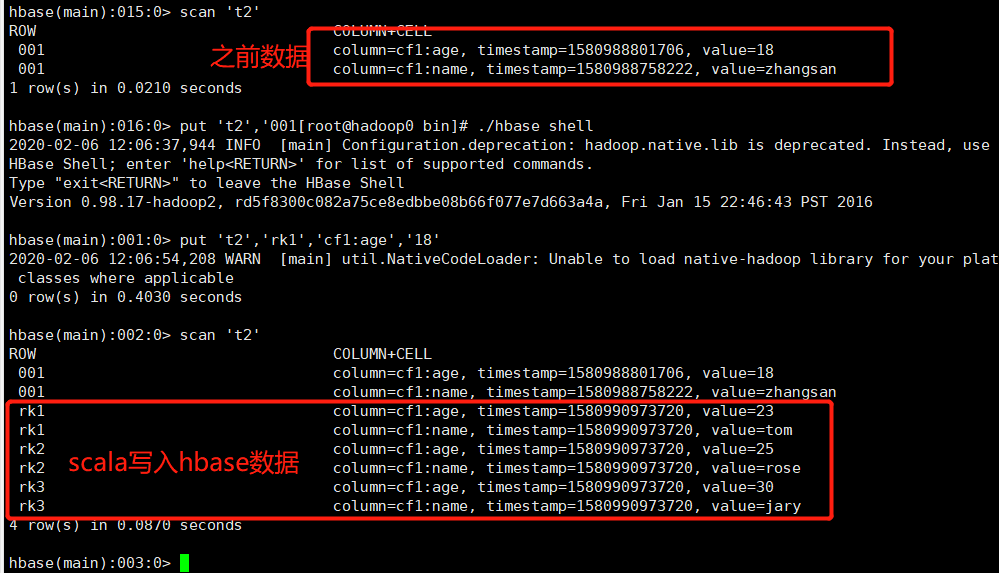
至此、spark写入hbase成功。
3、过滤器
随即的返回row的数据,chance取值为0到1.0,如果<0则为空,如果>1则包含所有的行。
3.1 scala代码
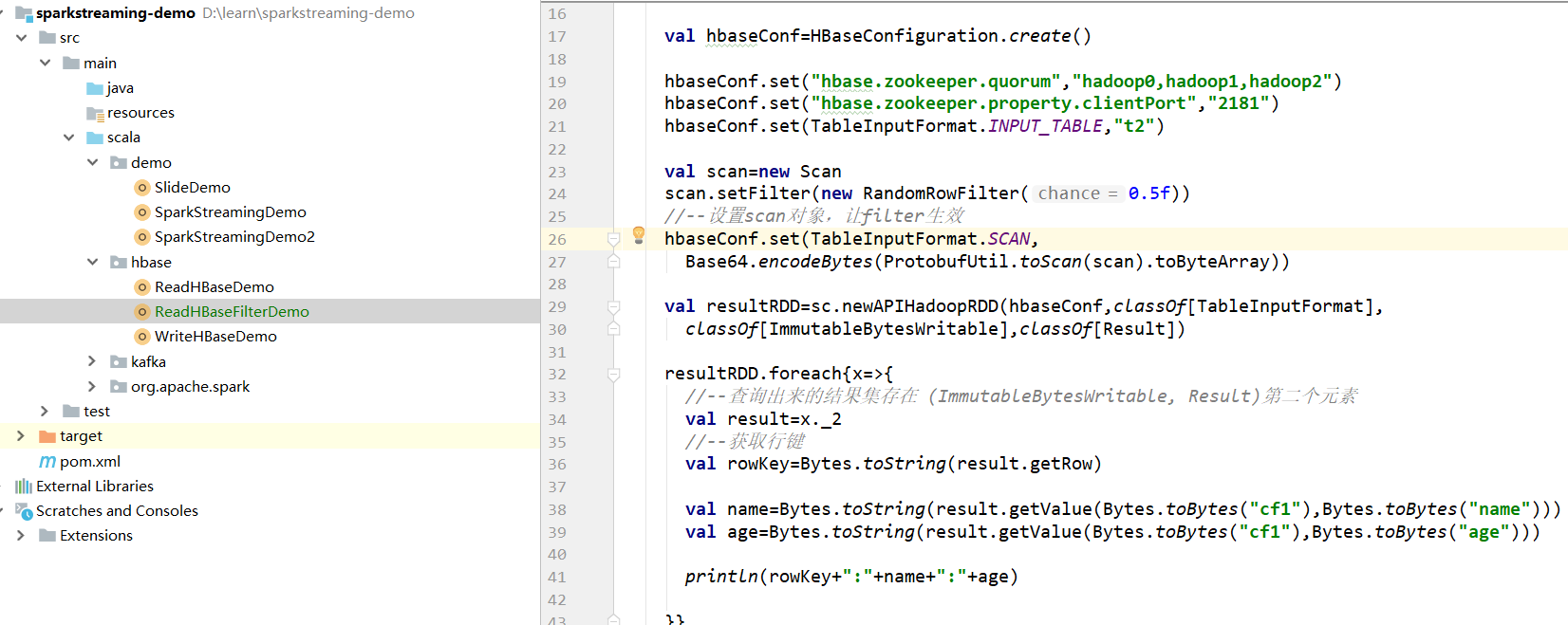
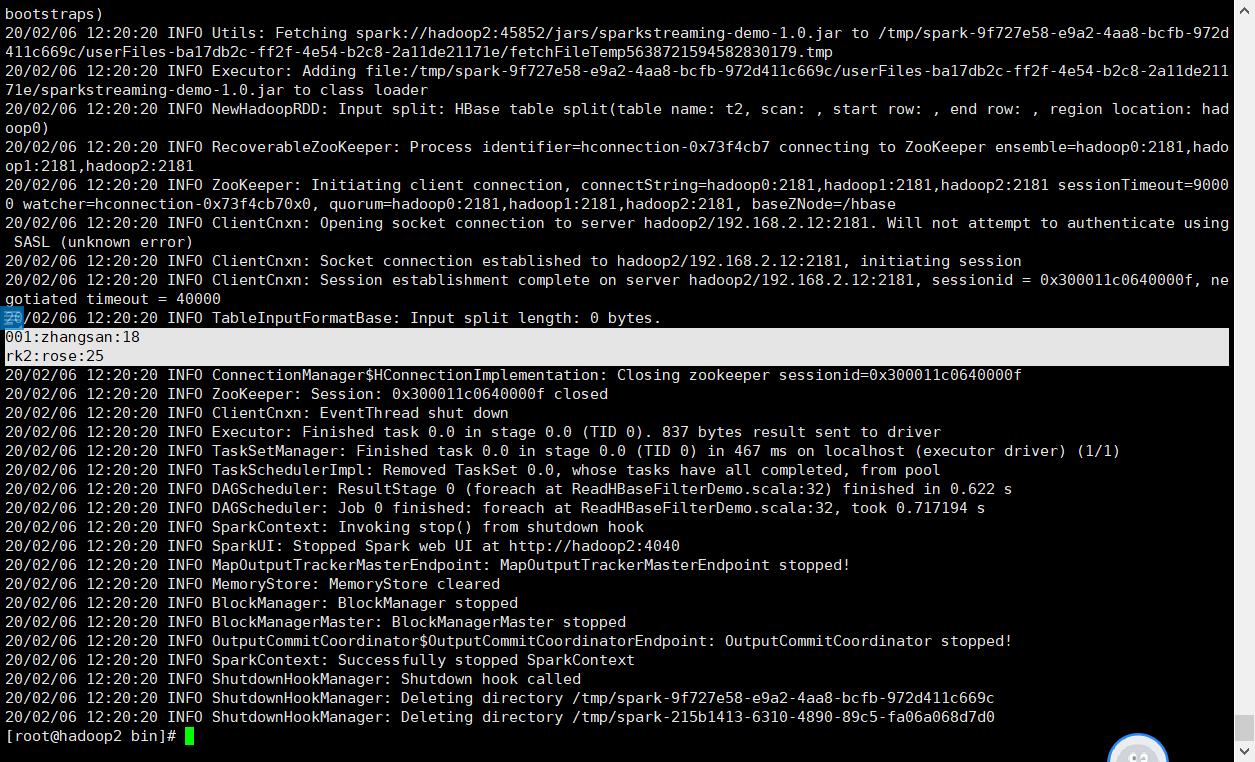
3.2 提交jar至spark测试
第一次如下:
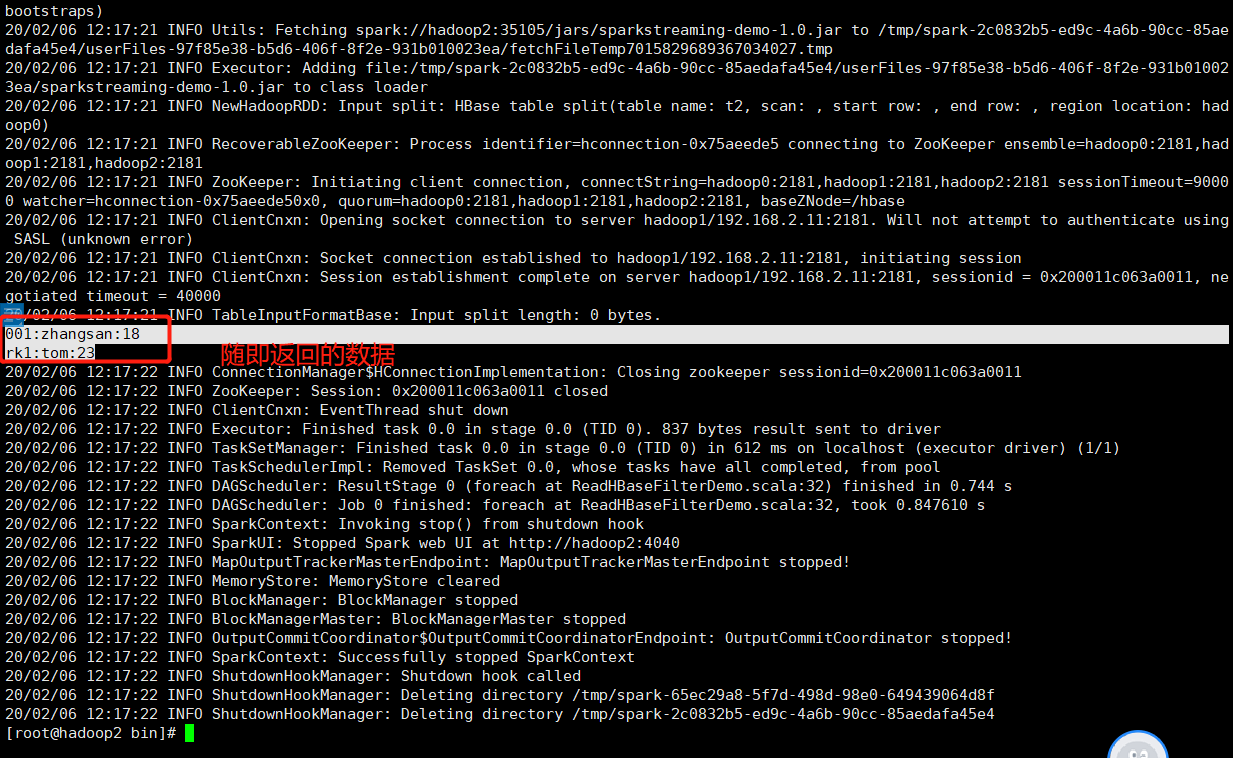
第二次如下:
至此、spark对接kafka及HBase完成,欢迎各位读者指正、交流~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号