SparkStreaming个人记录
一、SparkStreaming概述
SparkStreaming是一种构建在Spark基础上的实时计算框架,它扩展了Spark处理大规模流式数据的能力,以吞吐量高和容错能力强著称。

SparkStreaming会将源数据以batch为单位来进行处理,每一批数据封装为一个DStream。即SparkStreaming处理的就是一个一个的DStream,而DStream底层就是RDD。
二、架构及原理
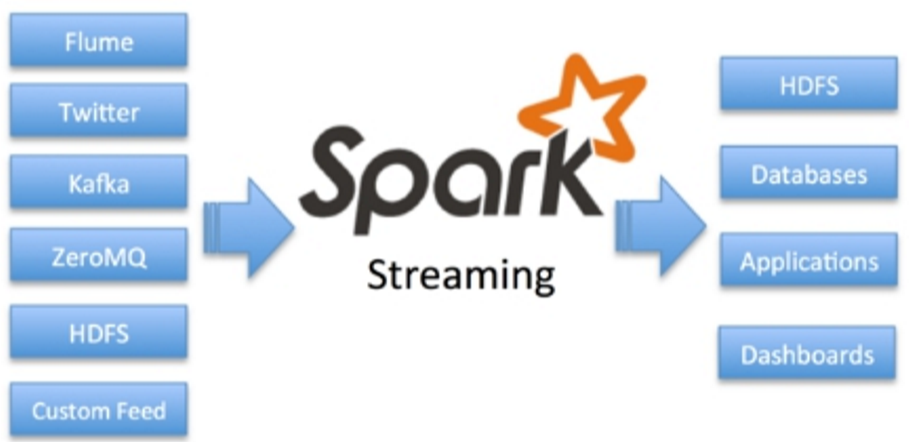
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对接多种数据源(如Kafka、Flume、Twitter、ZeroMQ、TCP套接字等)进行类似的Map、Reduce和Join等复杂操作,并将结果保存到外部系统、数据库或应用到实时仪表盘。
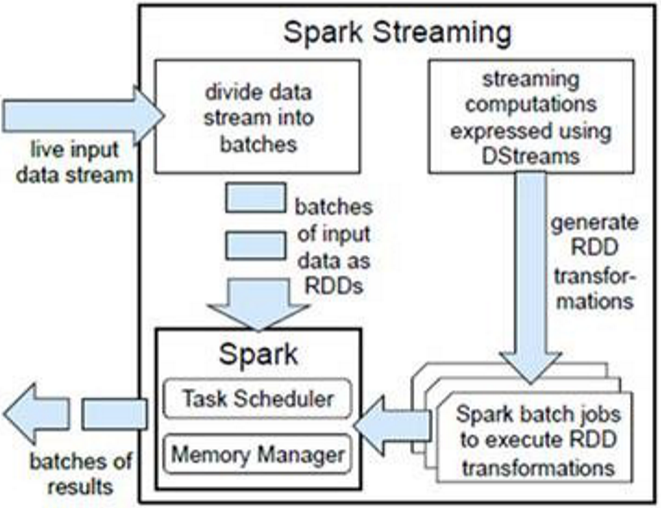
SparkStreaming是将流式计算分解成一系列短小的批处理作业,也就是SparkStreaming的输入数据按照batch size(如1秒)分成一段一段的数据DStream(Discretized-离散化Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将SparkStreaming中对DStream的Transformation操作变为针对Spark的RDD的Transformations操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务需求可以对中间的结果进行叠加或存储到外部设备。
对DStream的处理,每个DStream都要按照数据流到达的先后顺序依次进行处理。即SparkStreaming天然确保了数据处理的顺序性。这样使所有的批处理具有了一个顺序的特性,其本质是转换成RDD的血缘关系。所以,SparkStreaming对数据天然具有容错性保证。
为了提高SparkStreaming的工作效率,应合理配置批的时间间隔,最好能够实现上一个批处理完某个算子,下一个批算子刚好到来。
三、SparkStreaming入门案例
以下案例代码:https://github.com/Simple-Coder/sparkstreaming-demo
1、案例一
监控指定文件夹处理其中产生的新的文件
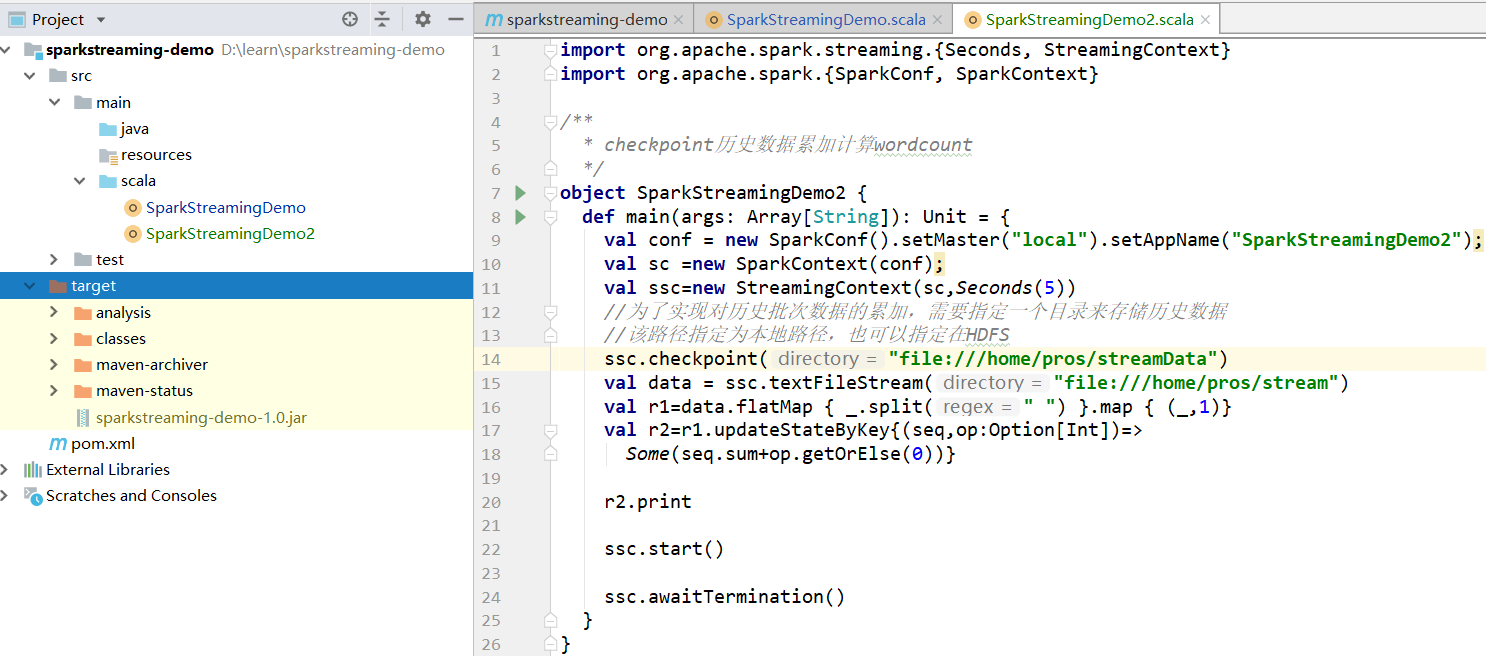
1.1 案例代码
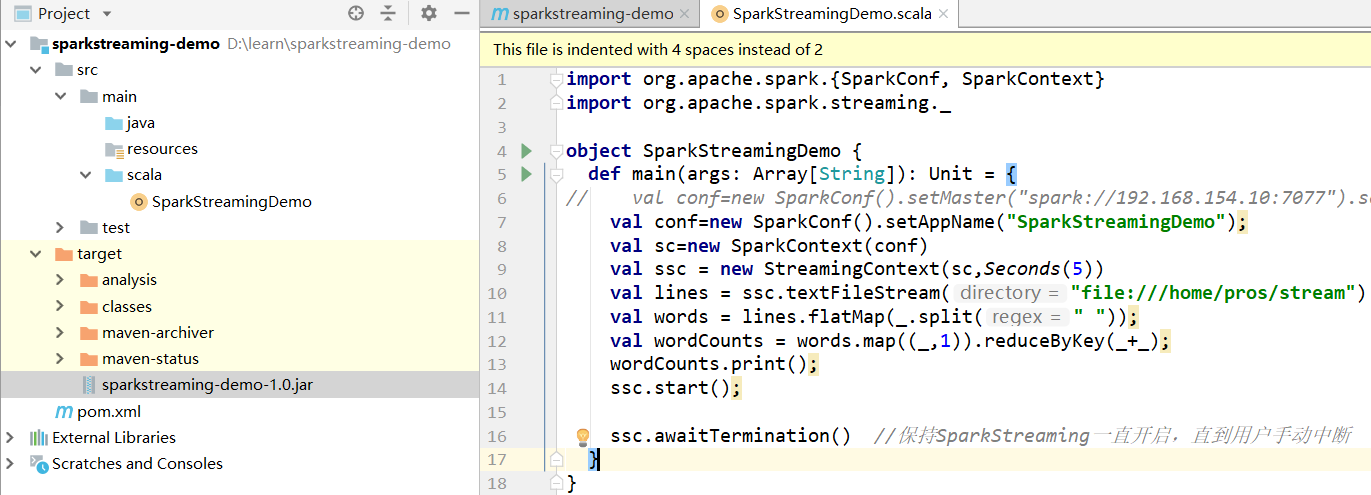
1.2 提交jar包

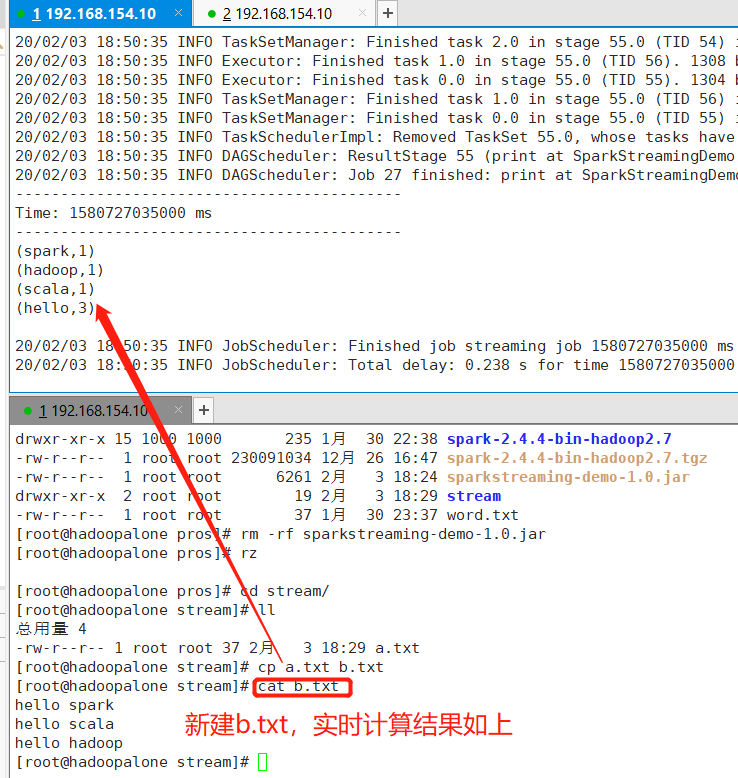
1.3 新增文件测试
2、案例二
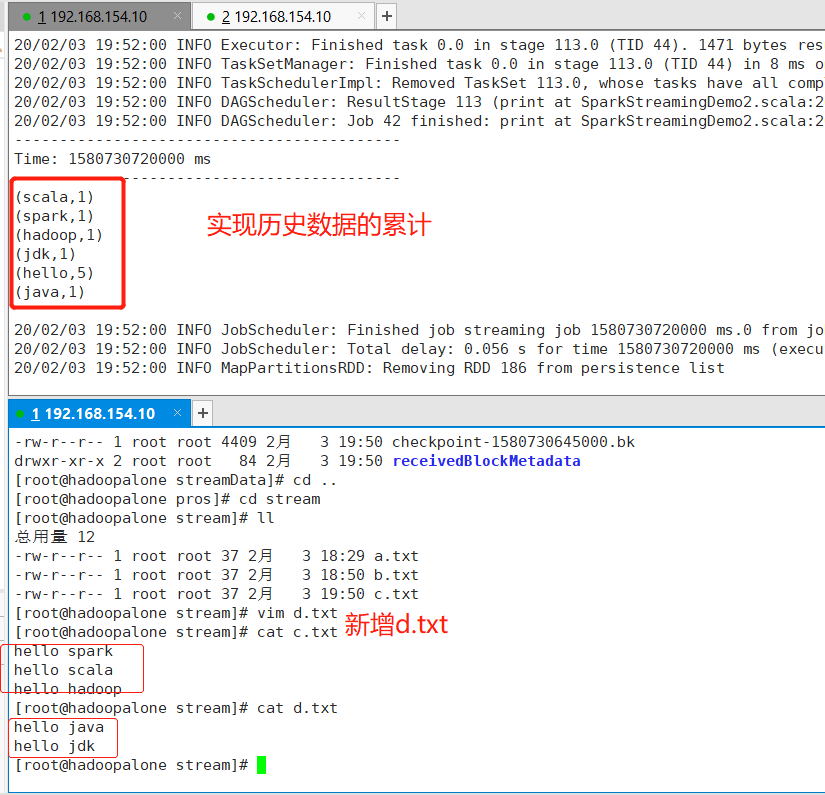
实现:SparkStreaming对历史数据的累加处理
经过测试,案例一的代码确实可以监控指定的文件夹,处理其中产生的新的文件,但是数据在每个周期到来后,都会重新进行计算,而如果需要对历史数据进行累计处理,这时就用到了Spark的CheckPoint机制,首先需要设置一个检查点目录,在这个目录,存储了历史周期数据。通过在临时文件夹中存储中间数据,为历史数据累计处理提供了可能性。
2.1 案例代码
2.2 测试结果
3、案例三
案例二的数据不停的累计下去,有些时候业务需求却是:每隔一段时间重新统计下一段时间的数据,并且能够对设置的批时间进行更细粒度的控制,这样的功能可以通过滑动窗口的方式来实现
Spark的滑动窗口机制:每隔一段时间(滑动区间)计算下一个段时间(窗口长度)的数据
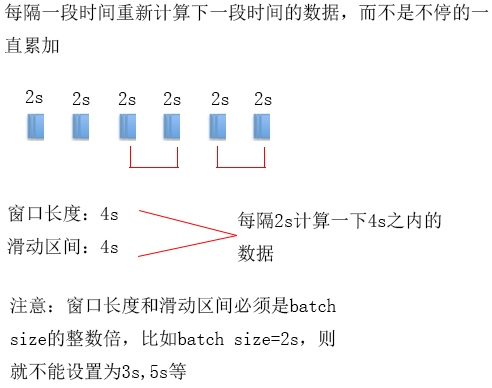
注:窗口长度和滑动区间必须是batch size的整数倍
3.1 案例代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号