网站日志流量分析系统之(日志收集)
一、概述
网站日志流量分析系统之(日志埋点)这里我们已经将相关数据通过ajax发送至日志服务器,这里我只用了一台日志服务器(本机Windows环境),日志收集主要分为以下几个步骤:
①日志服务器集结合logback,并自定义日志过滤器,将日志发给对应FlumeAgent客户端
②FlumeAgent客户端根据接收器策略分发至中心服务器
③中心服务器将数据分别落地至HDFS及Kafka(这里先做离线分析,中心服务器落地HDFS;实时分析中心服务器的Flume策略暂时不加,后续实时分析时加上)
二、服务器规划
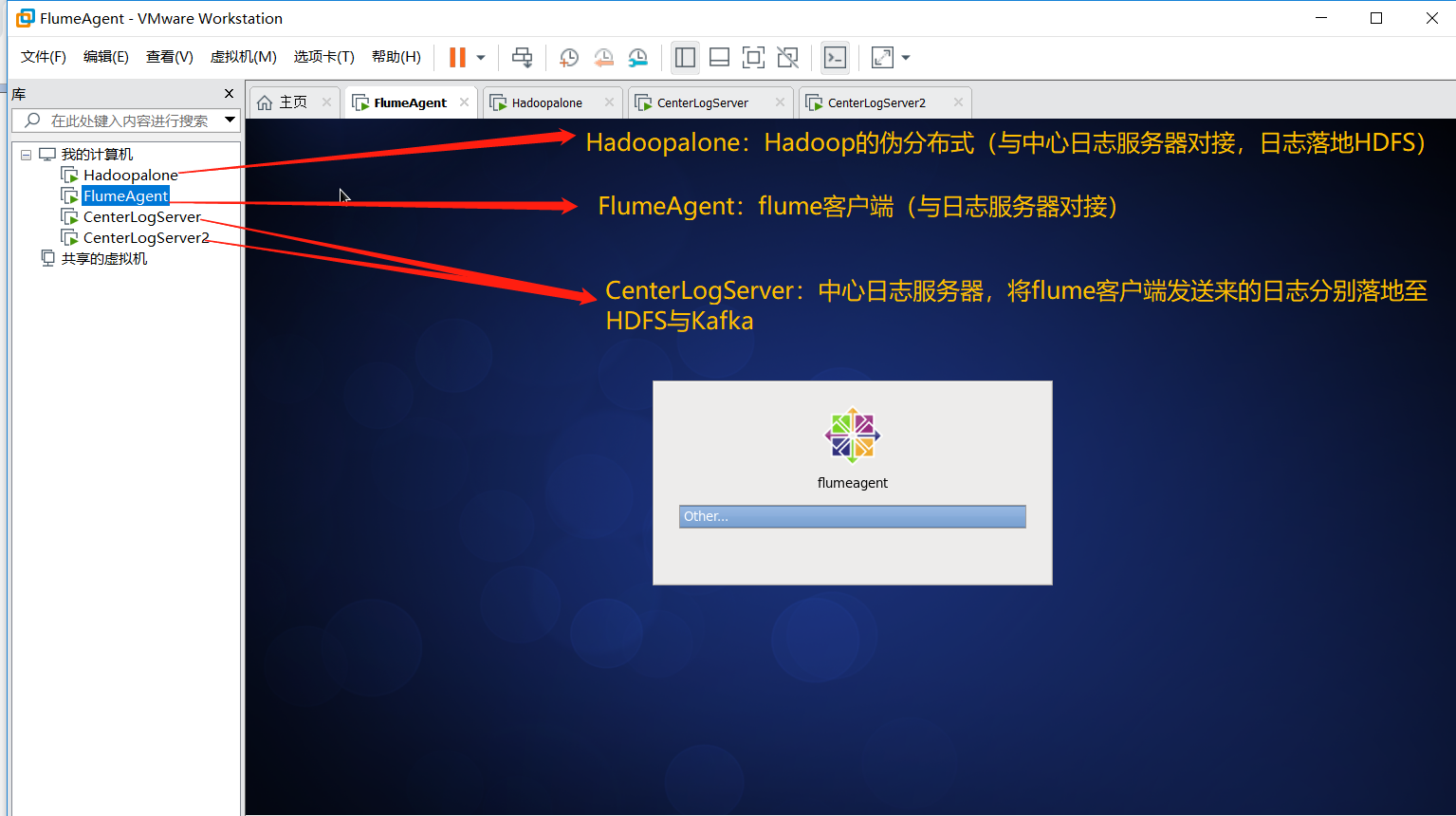
三、日志收集实现
①日志服务器结合logback,并自定义日志过滤器,将日志发送至FlumeAgent客户端
继续编写日志服务器代码(代码已经上传Github:https://github.com/Simple-Coder/log-demo),增加logback.xml配置如下:


<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration> <configuration> <appender name="consoleAppender" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%d{yyy MMM dd HH:mm:ss.SSS} [%thread] %-5level %logger{36}:%L- %msg%n </pattern> </encoder> </appender> <!-- name:自取即可, class:加载指定类(ch.qos.logback.core.rolling.RollingFileAppender类会将日志输出到>>>指定的文件中), patter:指定输出的日志格式 file:指定存放日志的文件(如果无,则自动创建) rollingPolicy:滚动策略>>>每天结束时,都会将该天的日志存为指定的格式的文件 FileNamePattern:文件的全路径名模板 (注:如果最后结尾是gz或者zip等的话,那么会自动打成相应压缩包) --> <appender name="fileAppender" class="ch.qos.logback.core.rolling.RollingFileAppender"> <!-- 把日志文件输出到:项目启动的目录下的log文件夹(无则自动创建)下 --> <file>log/logFile.log</file> <!-- 把日志文件输出到:name为logFilePositionDir的property标签指定的位置下 --> <!-- <file>${logFilePositionDir}/logFile.log</file> --> <!-- 把日志文件输出到:当前磁盘下的log文件夹(无则自动创建)下 --> <!-- <file>/log/logFile.log</file> --> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!-- TimeBasedRollingPolicy策略会将过时的日志,另存到指定的文件中(无该文件则创建) --> <!-- 把因为 过时 或 过大 而拆分后的文件也保存到目启动的目录下的log文件夹下 --> <fileNamePattern>log/logFile.%d{yyyy-MM-dd}.%i.log </fileNamePattern> <!-- 设置过时时间(单位:<fileNamePattern>标签中%d里最小的时间单位) --> <!-- 系统会删除(分离出去了的)过时了的日志文件 --> <!-- 本人这里:保存以最后一次日志为准,往前7天以内的日志文件 --> <MaxHistory> 7 </MaxHistory> <!-- 滚动策略可以嵌套; 这里嵌套了一个SizeAndTimeBasedFNATP策略, 主要目的是: 在每天都会拆分日志的前提下, 当该天的日志大于规定大小时, 也进行拆分并以【%i】进行区分,i从0开始 --> <timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>5MB</maxFileSize> </timeBasedFileNamingAndTriggeringPolicy> </rollingPolicy> <encoder> <pattern>%d{yyy MMM dd HH:mm:ss.SSS} [%thread] %-5level %logger{36}:%L- %msg%n </pattern> </encoder> </appender> <appender name="flumeagent" class="com.teambytes.logback.flume.FlumeLogstashV1Appender"> <filter class="com.logs.filter.StrFilter"></filter> <flumeAgents> 192.168.229.132:33333 </flumeAgents> <flumeProperties> connect-timeout=4000; request-timeout=8000 </flumeProperties> <batchSize>1000</batchSize> <reportingWindow>1000</reportingWindow> <additionalAvroHeaders> myHeader = myValue </additionalAvroHeaders> <application>flumeagent</application> <layout class="ch.qos.logback.classic.PatternLayout"> <pattern>%d{HH:mm:ss.SSS} %-5level %logger{36} - \(%file:%line\) - %message%n%ex</pattern> </layout> </appender> <logger name="com" level="info"> <appender-ref ref="flumeagent"/> </logger> <root level="info"> <appender-ref ref="consoleAppender"/> </root> </configuration>
②编辑FlumeAgent客户端配置文件(flumeagentlog.conf)
#声明Agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
#声明source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port =33333
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = ^(?:[^\\|]*\\|){14}\\d+_\\d+_(\\d+)\\|.*$
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.serializers.s1.name = timestamp
#声明sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname =centerlogserver
a1.sinks.k1.port =33333
a1.sinks.k2.type = avro
a1.sinks.k2.hostname =centerlogserver2
a1.sinks.k2.port =33333
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
#声明channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#绑定关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
在flume/bin目录下启动该flume客户端: ./flume-ng agent --conf ../conf/ --conf-file ../conf/flumeagentlog.conf --name a1 -Dflume.root.logger=INFO,console
③中心日志服务器代码(centerlogserver.conf)(2台中心日志服务器代码相同)
#配置agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#声明Source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 33333
#声明sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoopalone:9000/logdemo/reportTime=%Y-%m-%d
a1.sinks.k1.hdfs.rollInterval = 30
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.timeZone = GMT+8
#声明channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#绑定关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在flume/bin目录下分别启动两个中心日志服务器flume:./flume-ng agent --conf ../conf/ --conf-file ../conf/centerlogserver.conf --name a1 -Dflume.root.logger=INFO,console
④启动hadoopalone服务器,启动hadoop的伪分布式:start-all.sh
⑤测试
(1)分别启动:AppServer和LogServer,浏览器输入:http://localhost:8080/appserver/a.jsp,分别点击对应连接
(2)使用IDEA连接Hadoop伪分布式,查看结果如下:说明数据已经落地至HDFS,说明测试成功!
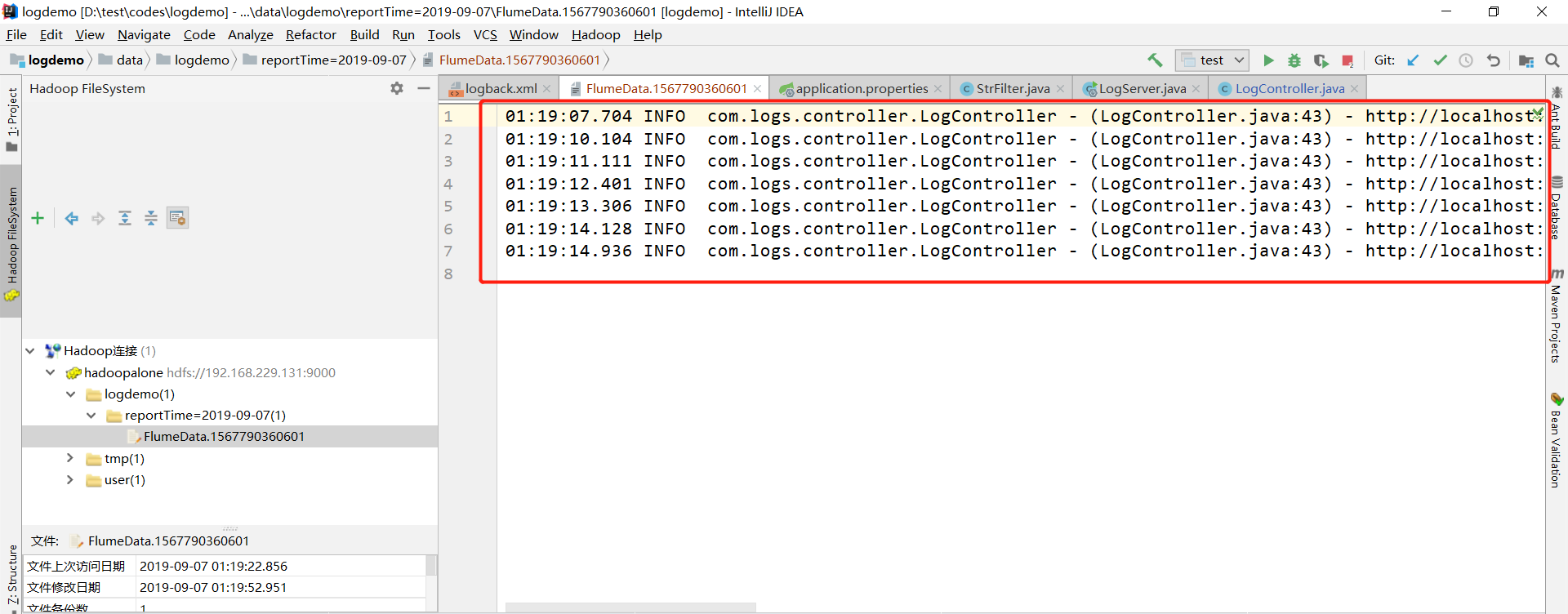
四、遇到的问题
(1)找不到Hadoop jar包,flume中的hdfs sink需要hadoop相关jar包的支持:
要么手动将hadoop相关jar包放置到flume的lib目录下;
要么在本机中解压hadoop并将hadoop路径配置为HADOOP_HOME环境变量,使flume可以自动找到这些jar。
(2)产生大量小的文件
hdfs sink的滚动条件设置不合理。修改即可
a1.sinks.k1.hdfs.rollInterval = 30
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
(3)文件内容为乱码(序列化文件无法直接查看)
hdfs sink默认产生SequenceFile文件,无法直接查看,修改即可
a1.sinks.k1.hdfs.fileType = DataStream
(4)按日期分目录存储
为了支持hive的分区处理,hdfs sink在将日志写入到hdfs的过程中,希望按照日期分目录存储。
a1.sinks.k1.hdfs.path = hdfs://ns/flux/reportTime=%Y-%m-%d
并且通过拦截器在日志头中增加timestamp头
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.serializers = s1
a1.sources.r1.interceptors.i1.regex = ^(?:[^\\|]*\\|){14}\\d+_\\d+_(\\d+)\\|.*$
a1.sources.r1.interceptors.i1.serializers.s1.name = timestamp
(5)生成的目录时间不正确
配置hdfs采用的时区
a1.sinks.k1.hdfs.timeZone = GMT+8
五、总结
至此,完成了日志的收集,并落地至HDFS(落地至Kafka后续加),以供下节离线分析的数据来源,数据清洗处理之离线分析:网站日志流量分析系统之数据清洗处理(离线分析)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号