【原创】从Rest到Graphql
引言
开局两张图,内容全靠编~


区别分离和半分离的标志在于Controller层由不由前端控制,Controller在前端手里,前端手里握着组装数据的逻辑,那就是前后端分离!否则就是半分离!
那么,半分离和分离的架构是长下面这样的
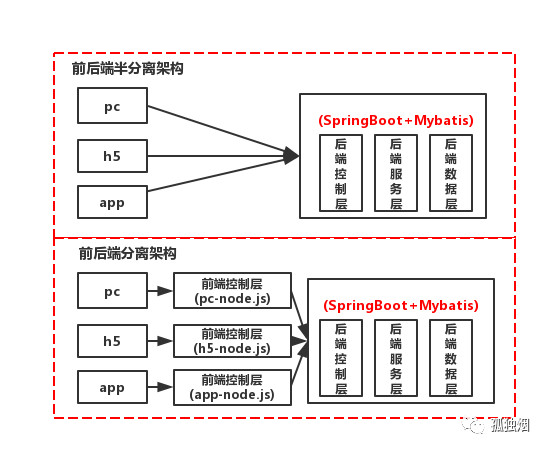
ps:中小型公司慎重,不要玩前后端分离架构!前端工作量贼大!
那么用上了前后端分离架构后,后端的API一般会按照Restful风格来设计!ResultFul推荐每个URL能操作具体的资源,而且能准确描述服务器对资源的处理动作,通常服务器对资源支持get/post/put/delete/等,用来实现资源的增删改查。前后端分离的架构下,这些api-url是对接的桥梁,采用ResultFul接口地址含义才更清晰、见名知意。
那么,在实践RestFul风格的API的有一个致命的缺陷,是神马类?嗯,带着你的疑惑开始本文
正文
RestFul的缺陷
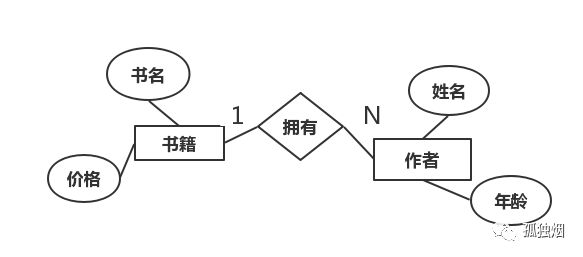
假设,此时我们有两个资源分别是Book和Author,这两个资源对应的ER图如下
相应的API有
POST /books
GET /books/{id}
POST /authors
GET /authors/{id}
我们有一个需求,需要查询id=1的图书信息!
那我们的请求地址是这样的
GET /books/1
返回结果是这样的
[{
"id": 1,
"bookname": Harry Potter,
"price": 56.00,
"author_id": 2
}]
这时候前端MM拿到这个结果后,傻了眼!这里怎么能直接返回author_id呢,难道直接把author_id显示在界面上么?不可能啊,界面上要显示的是author_name才行!
OK,那么在这种情况下,有两种方式可以解决问题!
(1) 跟后端沟通,让他增加一个接口
嗯,我们复习一下什么是VO对象。
VO(View Object):视图对象,用于展示层,它的作用是把某个指定页面(或组件)的所有数据封装起来。
那可以让后端封装一个接口,后端帮你把数据拼装好,提供API如下
GET /bookVOs/1
这样直接返回的结果就是
[{
"id": 1,
"bookname": Harry Potter,
"price": 56.00,
"author_name": J. K. Rowling
}]
当然,因为你这是临时让后端加接口,可能会有如下情形产生

OK,回到正题,这样做的缺点主要有两个
- 前后端强耦合在一起,前端界面发生变动,后端VO对象跟着一起变
- 如果BookVO对象在手机端、PC端、APP端的显示内容都不一样,你可能在项目中会有BookPcVO类、BookH5VO类、BookAppVO类,VO类大大膨胀!
(2) 自己做适配
这个也很简单,前端获得结果后,取出author_id: 2这条记录,然后再去调用地址
GET /authors/2
得到结果,然后进行组装显示!
当然,这个时候会有如下情形产生(这就是我注孤生的原因!)

当然,这种做法的缺点也很明显
- 返回了一堆前端并不需要的数据
- 徒增前后端的交互次数
ok,通过上面的描述,大家应该能体会到Rest的缺点:REST接口时返回的数据格式、数据类型都是后端预先定义好的,如果返回的数据格式并不是调用者所期望的,调用者在处理上比较麻烦!
那么,有没有办法让前端自定灵活的使用查询语句,自己想捞什么数据就捞什么数据呢?
有的,那就是Graphql!
Graphql的出现
Graphql其实要这样理解
Graphql=grap(图)+query+lanage
是一种基于图的查询语言!那么,这张图长什么样?
OK,首先你要声明一下,你的图结构,嗯,用的就是Graphql的语法啦,像下面这样
type Book {
id: Int
bookname: String
authors: [Author]
}
type Author {
id: Int
name: String
age: String
}
type Query {
getBook(id: Int): Book
}
schema {
query: Query
}
对上面的语句进行一下解释。这里一共声明了三个类Book、Author、Query!其实,Book和Author大家都可以猜都出来是指啥,需要注意的一点是authors: [Author]这个地方,用了一个[]的语法,这代表Author是一个数组!
唯一需要说明的是,Query是什么鬼?
Query在这儿表明了该类型是这张图的入口,也就是根节点!我们的查询必须从根节点里的属性开始!这里我为了便于说明,只列了一个属性,也就是getBook,该属性是入口,必须从入口开始查!
那么,生成的图是长下面这样的
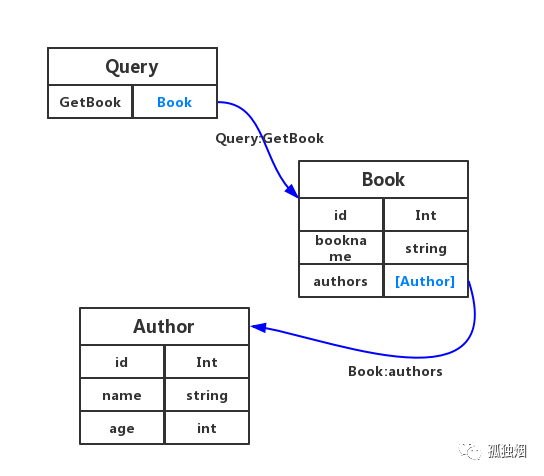
这里还有一个Resolver的概念,就是说,GragphQL解析到getBook方法的时候,方法体内容是啥?是在Resovler中定义的,我这里就不贴配置了,感兴趣的可以自己去官网阅读!
OK,接下来就是第二个问题,怎么查?
根据上面我说的,只能从根开始,根是getBook,那语句怎么写呢?如下所示
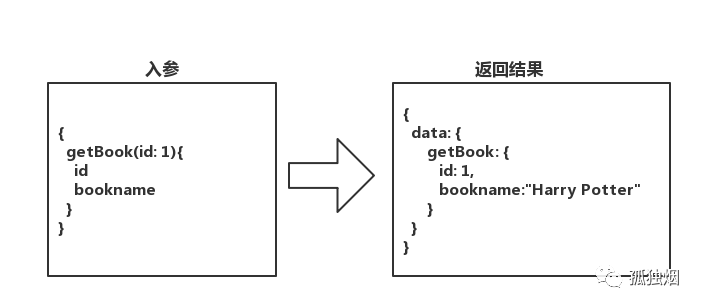
那你想加个字段,显示作者名字呢?直接像下面这么写
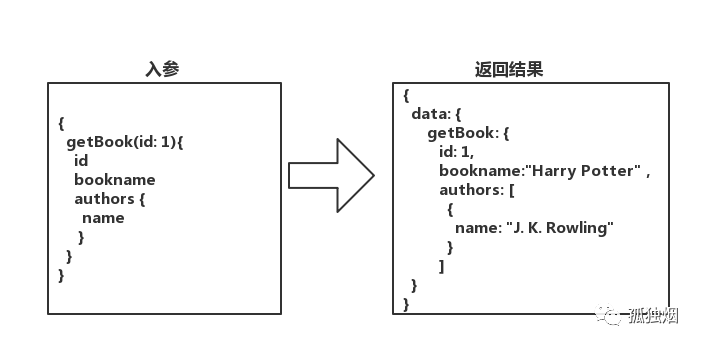
采用这种语法结构,后端的数据模型就变成了一张图,前端可以定制化自己的输出结构,同时可以减少前后端的沟通成本,提高灵活性!
一些疑问
(1)java语言中,对Graphql的支持如何?
在java中,有个jar包为graphql-java-tools提供了对Java的支持。
另外,考虑到现在大多是springboot项目,有大神封装好了starter包,供你们的springboot项目使用!
只需在项目中引入
<!-- graphql -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java-tools</artifactId>
<version>4.3.0</version>
</dependency>
即可让你的springboot项目拥有graphql的功能,非常方便!
(2)这样做不会加重前后端工作量么?
说句实在话,摸着良心说,前期确实加重了前后端的工作量!
对前端而言:需要去了解Graphql的语法!
对后端而言:不仅需要了解Graphql的语法,还需要去编写Schema和Resovler!
所以短期内,确实增加了工作量!但是从长远来看,同时降低了前后端的工作量!第一,前端不用了解后端的数据结构,GraphQL自己生成可交互式的接口文档,前端可以自己测试调用
第二,后端不用在编写什么接口文档,GrapQL自动帮你生成,用起来非常舒心!
总结
本文介绍了Rest的缺点,以及Graphql的基本知识,希望大家有所收获!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人