


软件需求工程与建模--搜索引擎项目--项目概述
一。Gitbub网址
韩昇范: https://github.com/hansf14/WebpageAnalysis
陈家乐: https://github.com/richardevan
金奭炫: https://github.com/sh0116
二。项目简介
这是一咱们想要自己实现的 Search Engine(搜索引擎)+ 搜索出来的网项之间的关系、网项与输入的keyword 之间的关系图可视化软件。就类似于百度和Google一样而咱们还加上了搜索结果的关系可视化。在电脑上(*或手机)上可以输入一个单词或句子,给出搜索结果并可视化。
三。选择原因
- 通过具体项目实例来了解大数据,应用大数据解决实际问题,这是我们学习的目的,我们组的组员都想借此机会学习当前最新的技术。
- 在当今创新创业时代,大数据处理技术要求越来越高,为了跟上时代的潮流,我们理应去了解、培养、训练这些技术。
四。NABCD分析
N(Need 需求)
随着技术的进步,所有的事情都可以通过谷歌或百度搜索。 但有时候结果是一篇很长而且有时候难以理解的文章。 通过这个搜索引擎,可以让搜索者更容易找到想要的结果。我们希望通过本次项目来再次巩固一下使用编程语言基础、新的算法框架、新的应用技术。
A(Approach 方法)
所有人可以通过电脑(*或者手机)上的浏览器访问网站。我们设想的实现步骤如下:
-
- 通过用 Python 编写的 Python Crawler (Python爬虫)收集几个网站上的一堆网项,将这些存储到我们的数据库里(信息累积)。
- 通过用 C++ 编写的程序(搜索引擎)将累积的网项根据已有的280,000个左右个单词组成的词库里的单词来索引,程序还需要支持 DBMS (数据管理系统)软件的一些文件管理系统的基本功能。
- 从用户输入一个单词或一个句子,将有关(包含对应keyword)的网项显示到我们要设计的一个网站上。
- 通过Python(和 Java;如果还考虑Android 手机上运行)与前端的接口对接。
- 将对应的结果中的网项之间的关系(相关度)与 keyword之间的关系, 用 d3.js 来可视化到此网项上。
B(Benefit 好处)
- 用户通过将可视化的结果来, 能够输入的(一系列构成的)一个句子中能找出来更重要keyword相关的网项,可以对教育、学习方面具有极大的参考价值。
- 通过具体项目实例来了解大数据,应用大数据解决实际问题能提高咱们的专业方面能力和眼界。
C(Competitors 竞争)
在学校里好像没有具有与此类似功能的软件。校外有较多搜索引擎,如Baidu百度和Google谷歌。可是这些搜索引擎缺少有关网项之间的可视化且用户不能按照觉得更重要的keyword来查看搜索结果。
D(Delivery 推广)
此款产品使用,应用范围首先初步锁定在为大学教育工作者, 学生。若进一步优化爬虫,索引,查找算法,并改善存储数据的方法还能为更大规模的用户提供服务, 扩展。
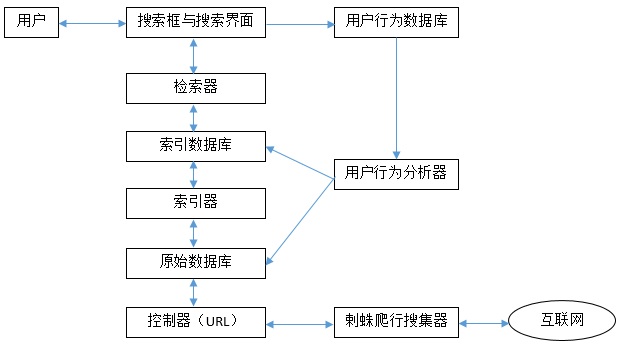
五。流程图
六。人员分工
- 韩昇范:Webpage Indexer (+Search Engine),Webpage Relation Visualization
- 陈家乐:Webpage Crawler
- 金奭炫:FrontEnd Webpage Design
