数据挖掘——时间序列分析
时间序列分析
一、 概念
时间序列(Time Series)
时间序列是指同一统计指标的数值按其发生的时间先后顺序排列而成的数列(是均匀时间间隔上的观测值序列)。
时间序列分析的主要目的是根据已有的历史数据对未来进行预测。
时间序列分析主要包括的内容有:趋势分析、序列分解、序列预测。
时间序列分解(Time-Series Decomposition)
时间序列按照季节性来分类,分为季节性时间序列和非季节性时间序列。
时间序列的构成要素:
- 长期趋势 T:现象在较长时期内受某种根本性因素作用而形成的总的变动趋势
- 季节变动 S:现象在一年内随着季节的变化而发生的有规律的周期性变动
- 循环趋势 C:现象以若干年为周期呈现出的波浪起伏形态的有规律的变动
- 不规则变动 I:是一种无规律可循的变动,包括严格的随机变动和不规则的突发性影响很大的变动两种类型
二、 非季节性时间序列
移动平均(MA,Moving Average)
移动平均是一种简单平滑技术,它通过在时间序列上逐项退役取一定项数的均值,来表现指标的长期变化和发展趋势
1、 简单移动平均(SMA)
简单移动平均将时间序列上前n个数值做简单的算术平均。
SMAn = ( x1 + x2 + …… + xn)/ n
2、 加权移动平均(WMA)
加权移动平均,在基于简单移动平均的基础上,对时间序列上前n期的每一期数值赋予相应的权重,即加权平均的结果
基本思想:提升近期的数据、减弱远期数据对当前预测值的影响,使预测值更贴近最近的变化趋势。
WMAn = w1x1 + w2x2 + …… + wnxn
3、 非季节性时间序列的分解
将非季节性时间序列分解为 趋势 和 不规则波动 两个部分。
#导入数据并绘制图形,得到如下的图形

简单移动平均法分解
#设置移动平均窗口为5,查看平滑后的曲线
Y = y.rolling(5).mean() plt.plot(x, y, 'k', x, Y, 'g') #移动平均后的曲线平滑向上
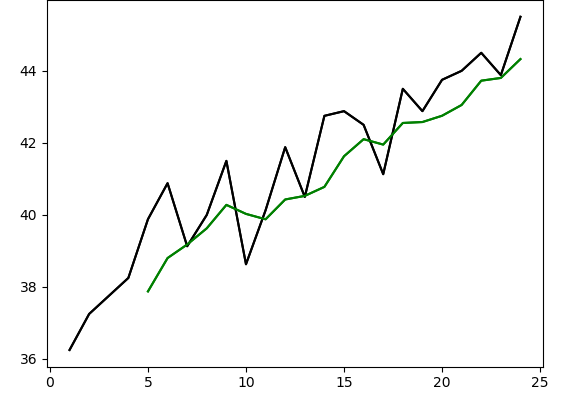
#求出不规则波动
#求出不规则变动 y_ = y - Y plt.plot(x, y, 'b', x, Y, 'g', x, y_, 'r') #不规则变动在0上下波动
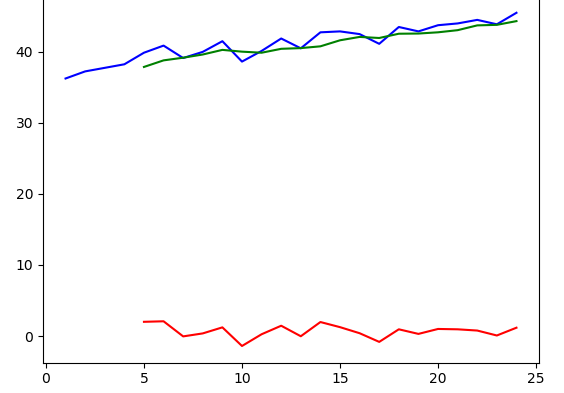
加权移动平均法分解
#设置窗口大小及权重,得到图形
w = 3 ww = np.arange(1, w+1) ww = ww / sum(ww) def wma(window): return np.sum(window * ww) Y = y.rolling(w).aggregate(wma) plt.plot(x, y, 'k', x, Y, 'g')

#调整窗口为5后再次绘图

#趋势更加明显,然后求出不规则波动
三、 季节性时间序列
在一个时间序列中,若经过n个时间间隔后呈现出相似性,该序列具有以n为周期的季节性特性。
季节性时间序列的分解
将季节性时间序列分解为 趋势 、周期性 和 不规则波动 三个部分。
tips:需要将时间列转换成索引列,方便计算
#将时间序列做为索引 dateparse = lambda dates: pd.datetime.strptime(dates, '%Y%m%d') data = pd.read_csv('filepath', parse_dates=['时间'], date_parser=dateparse, index_col='时间' )
#设置时间序列周期,并使用statsmodels.api包中的seasonal_decompose方法得到分解图形
import statsmodels.api as sm rd = sm.tsa.seasonal_decompose(data['总销量'].values, freq=7) resplot = rd.plot()
#得到如下的分解图形——原始数据、趋势数据、周期性数据、随机变量
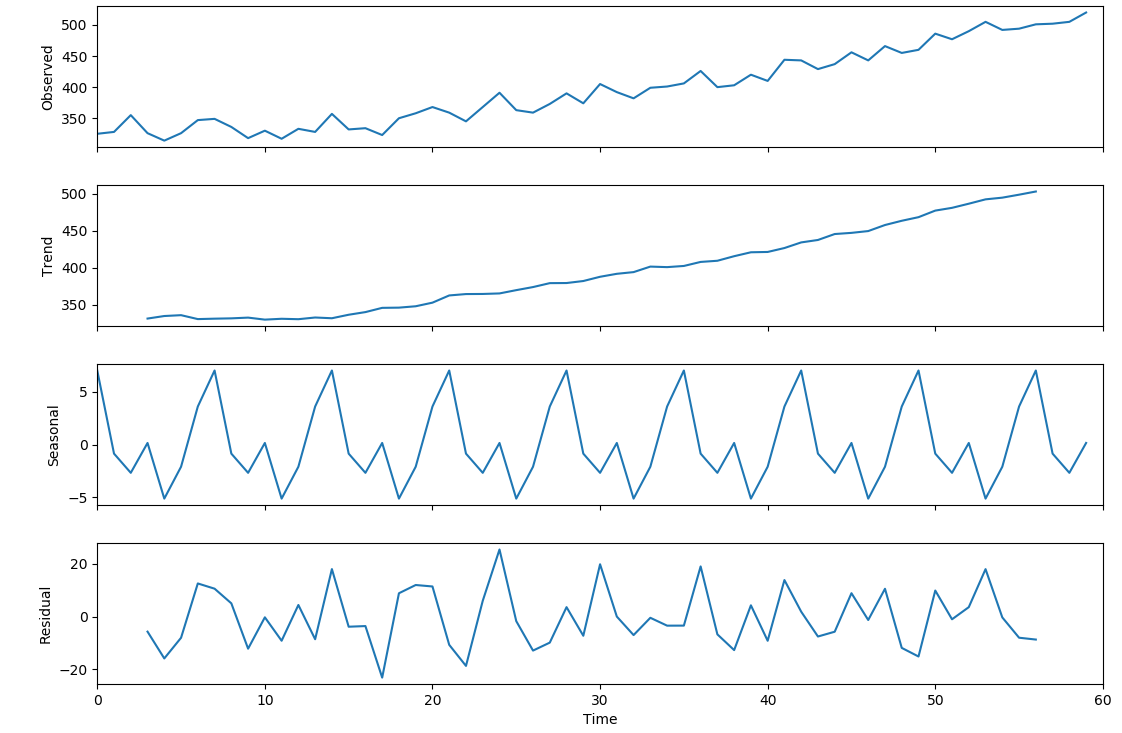
#再通过如下代码,得到分解部分的数据输出
#得到趋势、周期性、随机变量的数据输出 rd.trend rd.seasonal rd.resid
四、 序列预测
1、概念
预测(forecast)
对尚未发生或目前还不明确的事物进行预先的估计和推测,是在现时对事物将要发生的结果进行探讨和研究,简单的说就是指从已知事件预测未知事件。
时间序列预测(Time Series Forecasting
通过分析时间序列,根据时间序列所反映出来的发展过程、方向和趋势,进行类推或延申,借以预测下一段时间或以后若干时间段内可能达到的水平。
平稳型时间序列(Stationary Time Series)
平稳时间序列,其统计特征不随时间变化二变换,一般采用均值、方差或者协方差来作为统计特征。
差分(Integrated)
差分是一种让时间序列数据平稳的常用手段,异界差分的公式为: 。n阶差分,是在n-1阶差分的基础上,按照一阶差分的公式进行计算。
。n阶差分,是在n-1阶差分的基础上,按照一阶差分的公式进行计算。
常用的时间序列预测模型:
AR(p)模型(Autoregressive Model):自回归模型描述的是当前值与历史值之间的关系
MA(q)模型(Moving Average Model):移动平均模型描述的是自回归部分的误差累计
ARMA模型:所谓ARMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
python实现ARMA模型的预测
#数据索引列处理 dateparse = lambda dates: pd.datetime.strptime(dates, '%Y%m%d') data = pd.read_csv(r'filepath', parse_dates=['date'], date_parser=dateparse, index_col='date', encoding='utf-8', engine='python') #绘图观察时间序列是否平稳 plt.figure(figsize=(10, 6)) plt.plot(data, 'r', label='Raw') plt.legend(loc=0)

#观察到序列随时间呈上升趋势,非平稳
#时间序列平稳性检验模块
#时间序列平稳性检验模块 def tagADF(t): result = pd.DataFrame(index=[ "Test Statistic Value", "p-value", "Lags Used", "Number of Observations Used", "Critical Value(1%)", "Critical Value(5%)", "Critical Value(10%)" ], columns=['value']) result['value']['Test Statistic Value'] = t[0] result['value']['p-value'] = t[1] result['value']['Lags Used'] = t[2] result['value']['Number of Observations Used'] = t[3] result['value']['Critical Value(1%)'] = t[4]['1%'] result['value']['Critical Value(5%)'] = t[4]['5%'] result['value']['Critical Value(10%)'] = t[4]['10%'] return result
#检测方法 adf_Data = ts.adfuller(data.iloc[:,0]) #基于时间序列不平稳的假设而进行平稳性检验 tagADF(adf_Data)
#得到如下结果,P值0.69,表示69%的可能性该序列非平稳

#查看检验结果中的p值可以判断序列是否平稳,若不平稳则需要进行差分
#一阶差分处理 diff = data.diff(1).dropna() #对一阶差分后的数据进行绘图 plt.figure(figsize=(10, 6)) plt.plot(diff, 'r', label='Diff') plt.legend(loc=0)
#差分处理后的图形如下,勉强分辨出差分后的序列沿0上下波动

#对差分后的数据再次进行平稳性检验 adfdiff = ts.adfuller(diff.iloc[:,0]) tagADF(adfdiff)
#p值非常小,认为该差分后的序列平稳

#若差分后的序列平稳,则进行ARMR模型中p值和q值的确定
#通过传入限定的最大值,得到最佳的p值和q值(耗时较长) ic = sm.tsa.arma_order_select_ic(diff, max_ar=20, max_ma=20, ic='aic')
#构建模型
#得到最佳p值和q值 order = (15, 9) #ARMA模型建模和训练 ARMAmodel = sm.tsa.ARMA(diff, order).fit() #得到模型评分 delta = ARMAmodel.fittedvalues - diff.iloc[:0] score = 1- delta.var() / diff.var() #绘图得到拟合曲线 plt.figure(figsize=(10, 6)) plt.plot(diff, 'r', label='Raw') plt.plot(ARMAmodel.fittedvalues, 'g', label='ARMAmodel') plt.legend()
#观察图形,模型曲线与一阶差分曲线拟合性较好
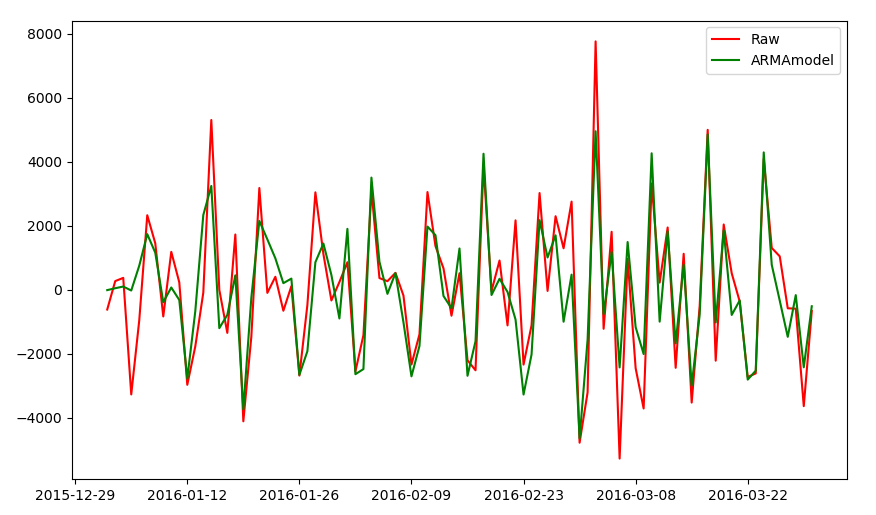
#数据预测
#输入起始时间和结束时间,进行数据预测(差分后的值,需要进行还原) p = ARMAmodel.predict(start='2016-03-31', end='2016-04-10')
#得到如下结果

#将预测得到的差分值进行还原
#将差分值进行还原 def revert(diffValues, *lastValue): for i in range(len(lastValue)): result = [] lv = lastValue[i] for dv in diffValues: lv = dv + lv result.append(lv) diffValues = result return diffValues #需要输入序列的最后一个值 r = revert(p, 10395)
#得到还原后的结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号