
数据挖掘——基于sklearn包的分类算法小结
目录
一、分类算法简介
二、KNN算法
三、贝叶斯分类算法
四、决策树算法
五、随机森林算法
六、SVM算法
一、分类算法简介
1、概念
1.1 监督学习(Supervised Learning)
从给定标注(训练集有给出明确的因变量Y)的训练数据集中学习出一个函数,根据这个函数为新数据进行标注。
1.2 无监督学习(Unsupervised Learning)
从给定无标注(训练集无明确的因变量Y)的训练数据中学习出一个函数,根据这个函数为所有数据标注。
1.3 分类 (Classification)
分类算法通过对已知类别训练数据集的分析,从中发现分类规则,以此预测新数据的类别,分类算法属于监督学习。
2、常用的分类算法
- KNN算法(K-近邻分类算法)
- 贝叶斯算法
- 决策树算法
- 随机森林算法
- SVM算法(支持向量机)
3、分类问题的验证方法
二、KNN算法
1、KNN算法简介
K近邻分类算法(k-Nearest Neighbors):从训练集中找到和新数据最接近的K条记录,然后根据他们的主要分类来决定新数据的类别。
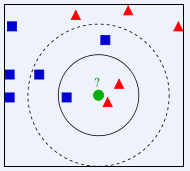
KNN算法属于最简单的机器学习算法之一,核心思想是每个样本都可以用它最接近的k个邻近值来代表,即如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。所以KNN算法的结果很大程度商取决于K的选择。
2、算法的优缺点
2.1 优点
- 简单,易于理解,易于实现,无需估计参数,无需训练
- 适合对稀有事件进行分类
- 特别适用于多分类问题(对象具有多个分类标签,比SVM表现更好)
2.2 缺点
- 当样本不平衡时(一个类样本容量很大,其他类样本容量很小),该样本的K个邻居中大容量类的样本占多数
- 计算量较大,因为对每一个待分类的文本,都要计算它到全体已知样本的距离
- 针对结果无法给出像决策树那样的规则
3、python中的实现过程
以iris数据集为例,基于python中sklearn包实现KNN分类
【iris数据集:常用的分类实验数据集,即鸢尾花卉数据集,是一个多重变量数据集,通过包含的4个属性(花萼长度、花萼宽度、花瓣长度、花瓣宽度)来预测属于三类鸢尾花中的哪一类。】
#python的sklearn包中自带了iris数据集
from sklearn import datasets iris = datasets.load_iris()
得到以下类型的数据,共有150行,包含特征属性(feature_names)、特征数据(data)、目标分类名称(target_names)、目标类别(target)
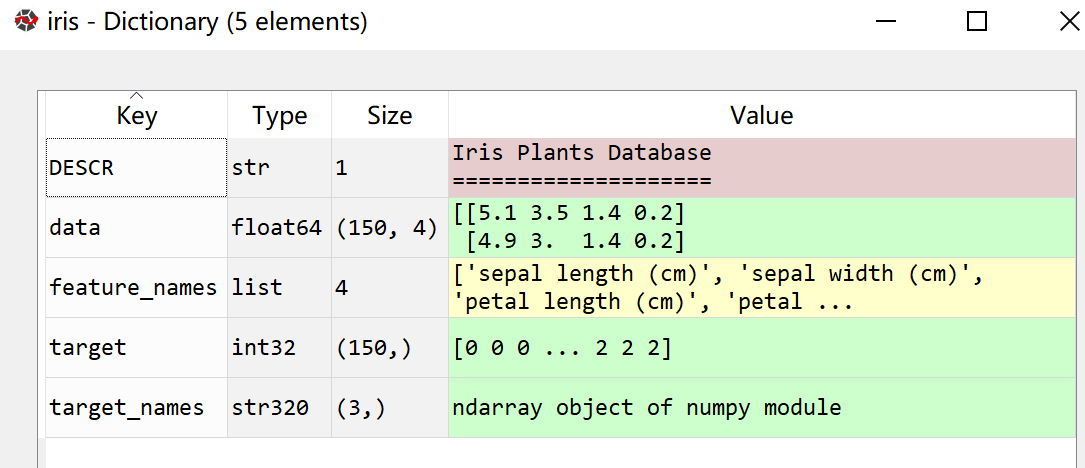
KNN分类建模的具体代码:
#切分训练集 from sklearn.model_selection import train_test_split #将数据集按7:3切分为训练集和测试集(特征变量和目标变量) data_train, data_test, target_train, target_test = train_test_split( iris.data, #特征数据 iris.target, #目标数据 test_size=0.3) #测试集占比 # KNN建模(1折交叉验证) from sklearn import neighbors knnmodel = neighbors.KNeighborsClassifier(n_neighbors=3) #n_neighbors参数为分类个数 knnmodel.fit(data_train,target_train) knnmodel.score(data_train,target_train) # 5折交叉验证 from sklearn.model_selection import cross_val_score #cross_val_score函数传入模型、特征数据、目标数据和 K值 cross_val_score(knnmodel,iris.data,iris.target,cv=5) #模型预测,得到分类结果 knnmodel.predict([[0.1,0.2,0.3,0.4]])
三、贝叶斯分类算法
1、贝叶斯分类算法简介
贝叶斯分类算法(NB):是统计学的一种分类方法,它是利用贝叶斯定理的概率统计知识,对离散型数据进行分类的算法。
朴素贝叶斯(Naive Bayes Classifier)的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
贝叶斯定理:
tips:python中sklearn包的naive_bayes模块中,有三种贝叶斯算法类型:
- GaussuanNB 高斯贝叶斯 :适用于特征值符合正态分布的数据,不需要知道具体每个样本的数值,只需知道样本符合什么样的正态分布(均值、方差)即可计算;
- BernoulliNB 伯努利贝叶斯:适用于特征值符合伯努利分布的数据,即是/否,0/1;
- MultinomialNB 多项式贝叶斯:不知道特征值符合哪种分布的时候,使用多项式贝叶斯算法计算每个特征的概率,所以需要知道每个特征值的数值大小(最常用于文本分类)。
2、算法的优缺点
2.1 优点
- 方法简单,分类准确率高
- 在接受大数据量训练和查询时速度快
2.2 缺点
- 由于贝叶斯定理假设一个属性值对给定类的影响独立于其它属性的值,而此假设在实际情况中经常是不成立的,因此其分类准确率可能会下降,即无法处理基于特征组合所产生的变化结果
3、python中的实现过程
使用多项式贝叶斯算法进行文本分类的
#建立含多篇文本的语料库,并指定文本类别——文本分词——文本向量化
#多项式贝叶斯建模
from sklearn.naive_bayes import MultinomialNB #多项式贝叶斯分类模型建立 MNBmodle = MultinomialNB() #将文本向量作为特征值传入,将分类序列作为目标序列传入 MNBmodle.fit(textVector,corpos['class']) MNBmodle.score(textVector,corpos['class'])
#传入新文本,向量化后进行分类预测
#传入新文本进行分类测试 newTexts = [''' 据介绍,EliteBook 840 G4是一款采用14英寸1080p屏幕的商务笔记本, 硬件配置方面,入门级的EliteBook 840 G4搭载Intel Core i3-7100处理器, 配备4GB内存和500GB机械硬盘,预装Windows 10操作系统。 高端机型可选择更大容量的内存和SSD固态硬盘。 机身四周提供了USB 3.0、USB-C、DisplayPort、15针迷你D-Sub, 支持蓝牙4.2和802.11ac Wi-Fi。 整机重1.48千克。 '''] #对新内容分词 for i in range(len(newTexts)): newTexts[i] = " ".join(jieba.cut(newTexts[i])) #新内容的文本向量 newTextVector = countVectorizer.transform(newTexts) #进行预测 MNBmodle.predict(newTextVector)
四、决策树算法
1、决策树算法简介
决策树算法(Decision Tree):通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数据进行分类预测。
决策树是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
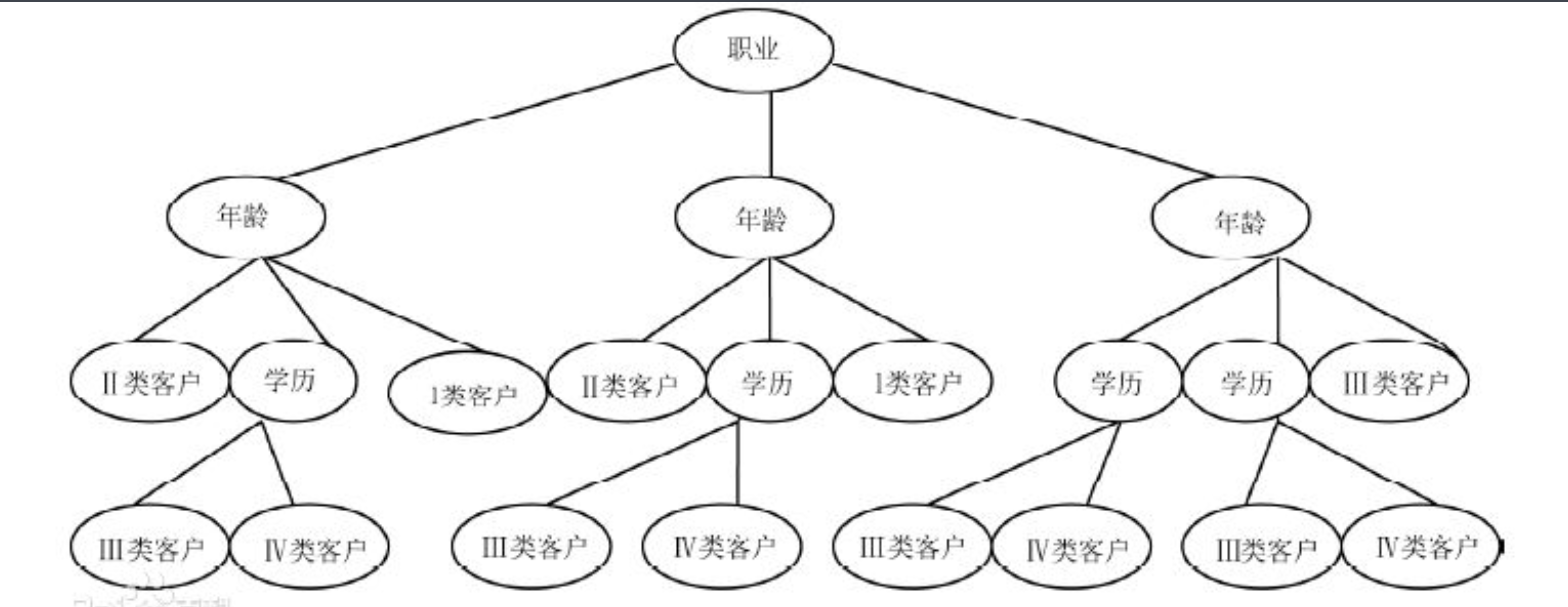
2、算法的优缺点
2.1 优点
- 易于理解和实现
- 可同时处理数值型和非数值型数据
2.2 缺点
- 对连续性的字段较难预测
- 对有时间顺序的数据,需要很多的预处理工作
- 当类别较多时,错误可能增加的比较快
3、python中的实现过程
基于sklearn包的决策树建模
#将训练集中的离散变量虚拟化
dummycolumns = ['data3','data4'] for column in dummycolumns: data[column] = data[column].astype('category') dummydata = pd.get_dummies(data, columns=dummycolumns, prefix=dummycolumns, prefix_sep='=', drop_first=True)
#构建模型
#特征变量 fdata = dummydata[['data1','data2','data3_dummy','data_dummy']] #目标变量 tdata = dummydata['target'] #构建模型 from sklearn.tree import DecisionTreeClassifier dtmodel = DecisionTreeClassifier(max_leaf_nodes=8) #最大叶数为8 #模型验证 from sklearn.model_selection import cross_val_score cross_val_score(dtmodel,fdata,tdata,cv=10) #交叉验证10次 #模型训练 dtmodel.fit(fdata,tdata)
#绘制决策树图(需要下载安装graphviz软件 并 安装pydot包,可参考http://wenda.chinahadoop.cn/question/5518)
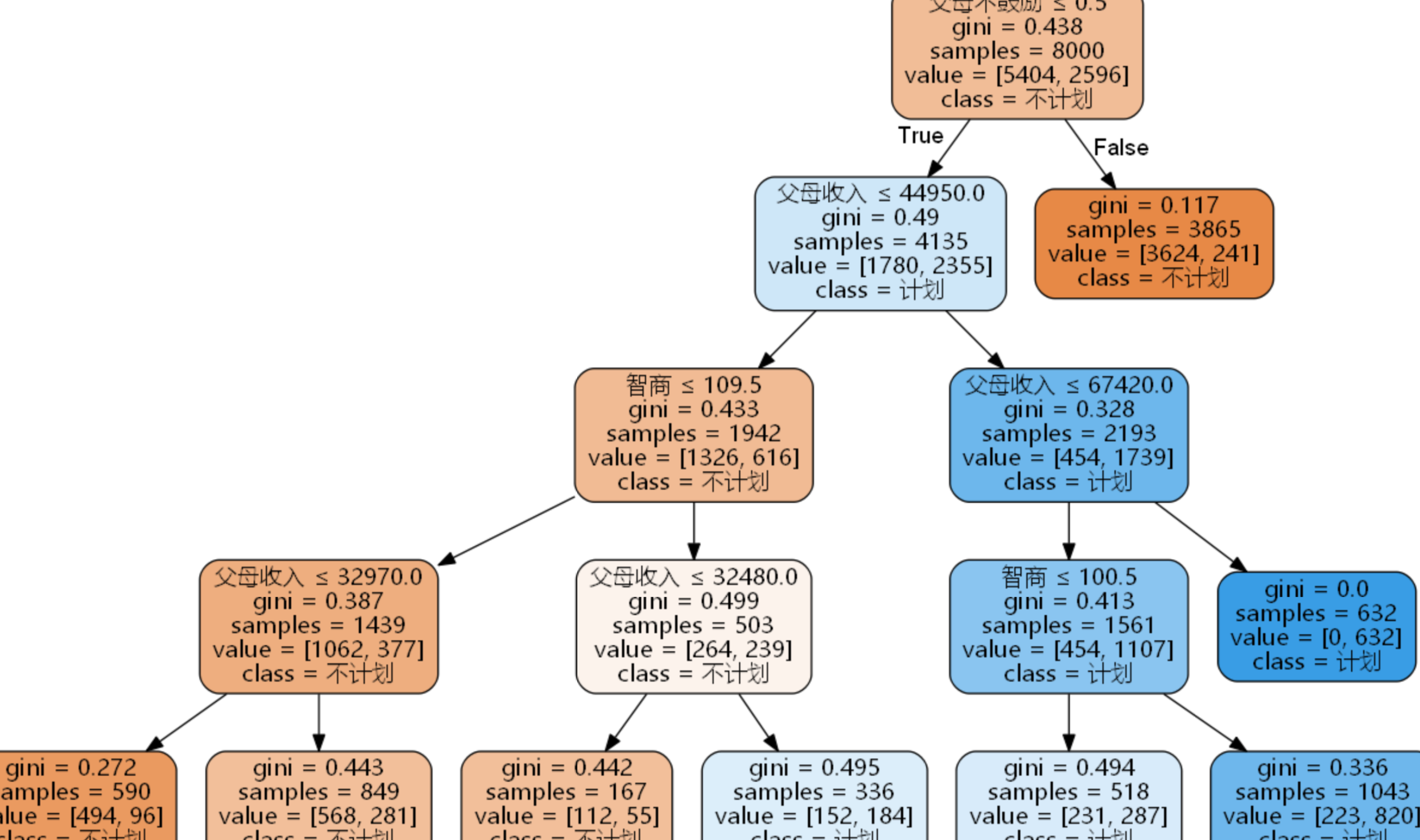
from sklearn.tree import export_graphviz with open(r'D:\...\data.dot','w') as f: f = export_graphviz(dtmodel, out_file=f) import pydot from sklearn.externals.six import StringIO dot_data = StringIO() export_graphviz( dtmodel, #模型名称 out_file=dot_data, #图形数据的输出路径 class_names=['A','B'], #目标属性的名称 feature_names=['a','b','c','d'], #特征属性的名称 filled=True, #是否使用颜色填充 rounded=True, #边框是否圆角 special_characters=True) #是否有特殊字符(含中文就算) graph = pydot.graph_from_dot_data(dot_data.getvalue()) graph.get_node('node')[0].set_fontname('Microsoft YaHei') graph.write_png(r'D:\...\决策树.png') #输出图形
最终得到如下图的决策树:
五、随机森林算法
1、随机森林算法简介
随机森林(RandomForest):是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林几乎能预测任何数据类型的问题,它是一个相对较新的机器学习方法。
2、算法的优缺点
2.1 优点
- 适合离散型和连续型的属性数据
- 对海量数据,尽量避免了过度拟合的问题
- 对高纬度数据(文本或语音类型的数据),不会出现特征选择困难的问题
- 实现简单,训练速度快,适合进行分布式计算
2.2 缺点
-
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟
-
对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
3、python中的实现过程
#由于随机森林基于决策树算法,所以数据处理步骤与决策树算法相同
#模型构建
#模型构建 from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score #比较决策树模型和随机森林模型的评分好坏 dtmodel = DecisionTreeClassifier() dtscroe = cross_val_score(dtmodel,fdata,tdata,cv=10) dtscroe.mean() rfcmodel = RandomForestClassifier() rfcscore = cross_val_score(rfcmodel,fdata,tdata,cv=10) rfcscore.mean() #评分优于决策树算法
#随机森林模型评分存在阈值,当决策树算法经过参数调优后,模型评分可以达到该阈值
#进行参数调优 dtmodel = DecisionTreeClassifier(max_leaf_nodes=8) dtscroe = cross_val_score(dtmodel,fdata,tdata,cv=10) dtscroe.mean() #评分明显提高 rfcmodel = RandomForestClassifier(max_leaf_nodes=8) rfcscore = cross_val_score(rfcmodel,fdata,tdata,cv=10) rfcscore.mean() #基本与决策树一致
六、SVM算法
1、SVM算法简介
支持向量机(Support Vector Machine,即SVM):是一种二分类算法,属于一般化线性分类器,这类分类器的特点是能够同时最小化经验误差与最大化几何边缘区,因此SVM也被称为最大边缘区分类器。
其主要思想为找到空间中的一个能够将所有数据样本划开的超平面,并且使得样本集中所有数据到这个超平面的距离最短
它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中
2、算法的优缺点
2.1 优点
- SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”
- 少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本
- 对小样本、非线性及高维模式识别中表现出许多特有的优势
2.2 缺点
-
SVM算法对大规模训练样本难以实施
-
用SVM解决多分类问题存在困难
3、python中的实现过程
python中SVM模型可以分为三种:svm.LinearSVC、svm.NuSVC、svm.SVC
#根据数据构建简单SVM模型(无参数调优)
from sklearn import svm from sklearn import cross_validation #根据三种方式分别建模,得到模型评分 svmmodel1 = svm.SVC() cross_validation.cross_val_score(svmmodel1,fdata,tdata,cv=3) svmmodel2 = svm.NuSVC() cross_validation.cross_val_score(svmmodel2,fdata,tdata,cv=3) svmmodel3 = svm.LinearSVC() cross_validation.cross_val_score(svmmodel3,fdata,tdata,cv=3) #LinearSVC 评分最好,所以使用该方法建模 svmmodel = svm.LinearSVC() svmmodel.fit(fdata,tdata) svmmodel.score(fdata,tdata)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号