数据挖掘——相似文章推荐
相似文章推荐:在用户阅读某篇文章时,为用户推荐更多的与在读文章内容相类似的文章
相关概念:
推荐(Recommended):指介绍好的人或事物,希望被任用或接受。数据挖掘领域,推荐包括相似推荐和协同过滤推荐。
相似推荐(Similar Recommended): 指当用户表现出对某人或者某物的兴趣时,为他推荐与之相类似的人或者物,核心定理:人以群分,物以类聚。
协同过滤推荐(Collaborative Filtering Recommendation):指利用已有用户群过去的行为或意见,预测当前用户最可能喜欢哪些东西或对哪些东西感兴趣
相关文章推荐主要基于余弦相似度的计算原理。
余弦相似度(Cosine Similarity):用向量空间中两个向量夹角的余弦值作为衡量两个个体见差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这个特征叫做余弦相似性。

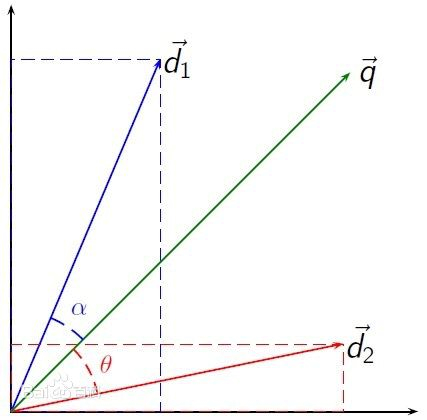
文章的余弦相似度:
素材:文章A、文章B
#对两篇文章进行分词, 得到 [A] 、 [B] 两个分词列表
#根据分词结果构建分词语料库,得到 [C] = [A] | [B]
#根据语料库分别统计A、B的词频(向量化,需要严格按照分词语料库单词的顺序)
#计算余弦值
具体实现:在构建语料库/中文分词/文档向量化之后
#计算余弦相似度 from sklearn.metrics import pairwise_distances #计算每行之间的距离,得到距离矩阵 distance_matrix = pairwise_distances(textVector,metric='cosine') #排序得到距离第2-6名的矩阵元素 sort = np.argsort(distance_matrix,axis=1)[:,1:6] similar5 = pd.Index(filepath)[sort].values #得到相似度前5的文章路径数据框 similarDF = pd.DataFrame({ 'filepath':corpos.filePath, 's1':similar5[:,0], 's2':similar5[:,1], 's3':similar5[:,2], 's4':similar5[:,3], 's5':similar5[:,4],})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号