大数据计数原理与应用——笔记——Hadoop
Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在链家的计算机集群总。
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce。
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务。
Hadoop的特性
- 高可靠性
- 高效性
- 高拓展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
Hadoop在企业中的应用架构(推荐企业使用cloudera和星环开发的Hadoop版本,个人使用Apache版本)
数据源——大数据层(离线分析、实时查询、BI分析)——访问层(数据分析、数据实时查询、数据挖掘)
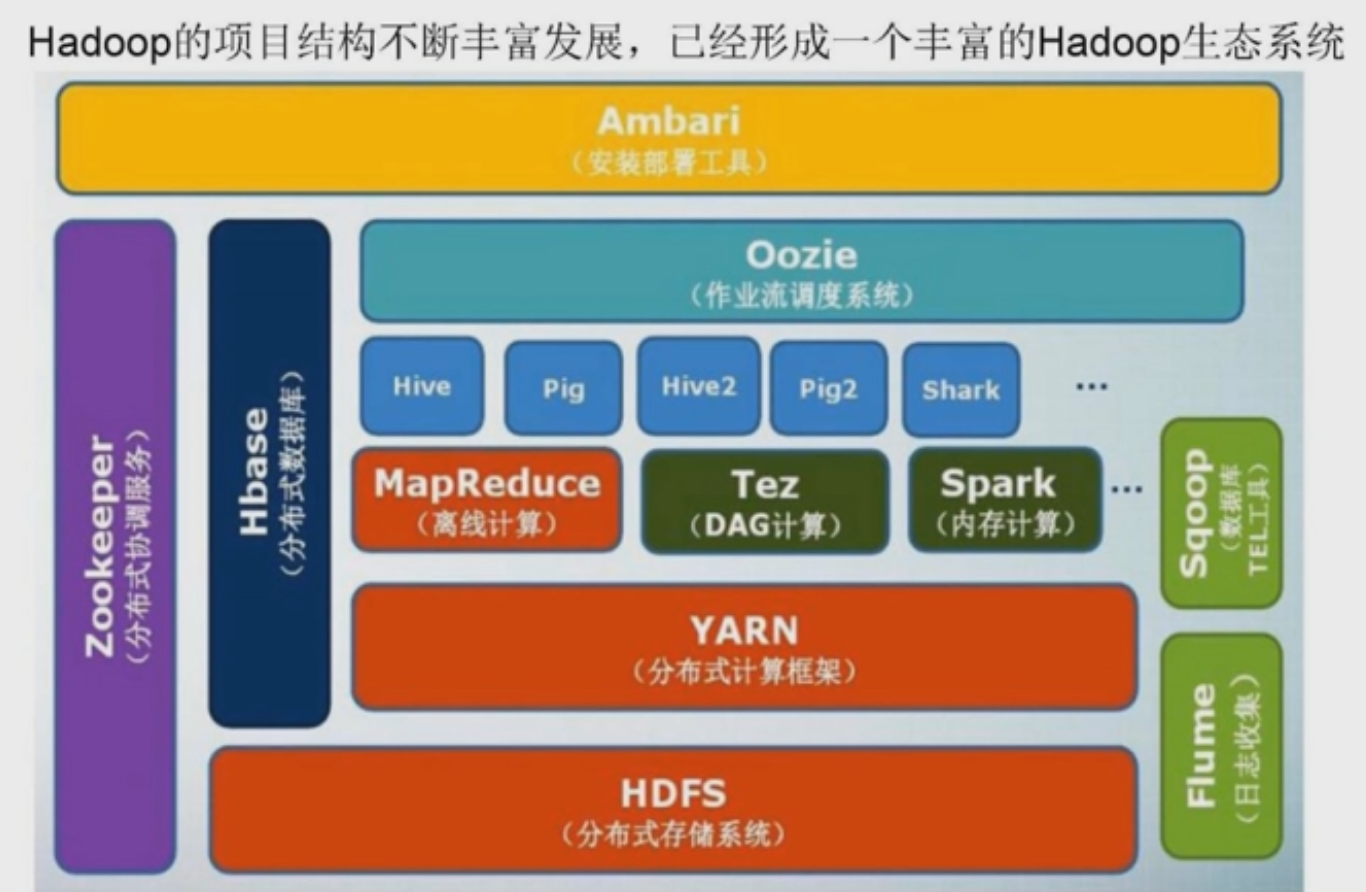
Hadoop项目结构
- HDFS 分布式存储系统 (1)
- YARN 分布式计算框架 (2)
- Tez DAG计算 (3)
- Spark 内存计算 (3)
- MapReduce 离线计算 (3)
- Hive 数据仓库 (4)
- Oozie 作业流调度系统 (5)
- Ambari 安装部署工具 (6)
![]()
Hadoop安装之前的预备知识
Linux版本:CentOS或者Ubuntu
安装方式:虚拟机安装(内存4G以上)、双系统安装(内存4G以下)
单机模式(本地模式,无需进行其他配置即可运行,单Java进程) 伪分布式模式 分布式模式(多个节点构成集群环境)
安装工具:VirtualBox虚拟机软件、Ubuntu LTS 14.04 ISO映像文件
Hadoop安装教程_单机/伪分布式配置 http://dblab.xmu.edu.cn/blog/install-hadoop/
一个基本的Hadoop集群中的节点有:
NameNode :负责协调集群中的数据存储
DataNode :存储被炒粉的数据块
JobTracker :协调数据计算任务
TaskTracker :负责执行由JobTracker指派的任务
SecondaryNameNode :帮助NameNode手机文件系统运行的状态信息(冷备份)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号