kaggle—first play—Titanic
玩了很久总算是又静下心来好好看书,经过一段时间的学习,打算稍微检验一下知识的掌握程度,所以去kaggle参加了久闻的泰坦尼克生还预测,以下是正文。
-----------------------------------------------------------------------------------------
1、观察数据
拿到数据集后,先来了解数据的大致情况。
data.info()
data_des = data.describe()
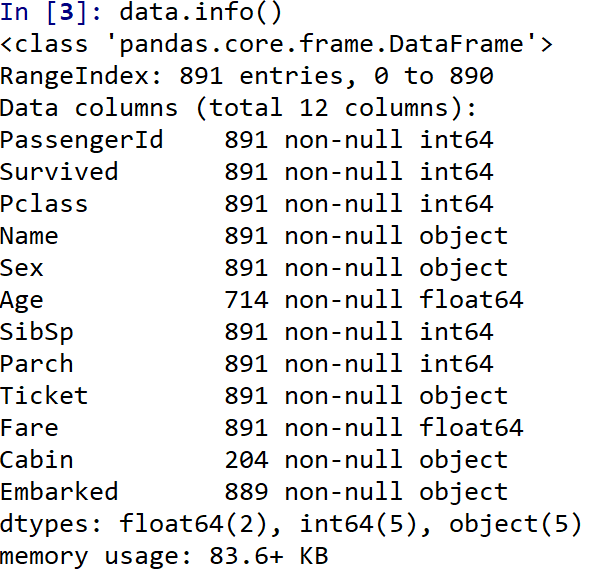

可以得知数据集有12列,891行,其中'Age'、'Cabin'、'Embarked'列存在缺失值,所有样本的平均生还率未0.383838;2等3等舱的人数比1等舱多;平均年龄为29.6991岁等等。
同时明确了需要预测的结果,即'Survived'的预测,是个明显的二分类问题,优先考虑逻辑回归、决策树、神经网络等算法。
以下为各列的含义:
passengerid_乘客ID survived_是否获救(目标) pclass_乘客等级
name_姓名 sex_性别 age_年龄(缺失) sibsp_堂兄弟/妹个数 parch_父母/小孩个数
ticket_船票信息 fare_票价 cabin_客舱号(缺失) embarked_登船港口(缺失)
对数据分组对比,先观察乘客等级、年龄、性别、登船港口与是否生还的关系:
#性别生还率:女性生还率74.2%,男性生还率18.9% sex_survived = data.groupby(by=['Sex'])['Survived'].agg({'总人数':np.size, '生还人数':np.sum}) sex_survived['未生还人数'] = sex_survived['总人数'] - sex_survived['生还人数'] sex_survived['生还率'] = sex_survived['生还人数'] / sex_survived['总人数'] #乘客等级生还率:1级乘客生还率最高 pclass_survived = data.groupby(by=['Pclass'])['Survived'].agg({'总人数':np.size, '生还人数':np.sum}) pclass_survived['未生还人数'] = pclass_survived['总人数'] - pclass_survived['生还人数'] pclass_survived['生还率'] = pclass_survived['生还人数'] / pclass_survived['总人数'] #各年龄段生还率:0-10岁生还率最高,60岁以上生还率最低 bins = [0,10,20,30,40,50,60,70,80] data['age_cut'] = pd.cut(data['Age'],bins,right=False) age_survived = data.groupby(by=['age_cut'])['Survived'].agg({'总人数':np.size, '生还人数':np.sum}) age_survived['未生还人数'] = age_survived['总人数'] - age_survived['生还人数'] age_survived['生还率'] = age_survived['生还人数'] / age_survived['总人数'] #各登船港口生还率:C港生还率最高,S港人数最多、生还率最低 embarked_survived = data.groupby(by=['Embarked'])['Survived'].agg({'总人数':np.size, '生还人数':np.sum}) embarked_survived['未生还人数'] = embarked_survived['总人数'] - embarked_survived['生还人数'] embarked_survived['生还率'] = embarked_survived['生还人数'] / embarked_survived['总人数'] ###可视化 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] =False plt.subplot(221) #将图形区域分成2行*2列,将图形设置在第1个位置 plt.bar(sex_survived.index, sex_survived['生还人数'], color='b', alpha=0.7) plt.bar(sex_survived.index, sex_survived['未生还人数'], bottom=sex_survived['生还人数'], color='lightblue') plt.title('性别获救情况') plt.ylabel('人数') plt.grid(b=True, which='major', axis='y') plt.subplot(222) plt.bar(pclass_survived.index, pclass_survived['生还人数'], color='b', alpha=0.7) plt.bar(pclass_survived.index, pclass_survived['未生还人数'], bottom=pclass_survived['生还人数'], color='lightblue') plt.xticks(pclass_survived.index) plt.title('乘客等级获救情况') plt.xlabel('乘客等级') plt.ylabel('人数') plt.grid(b=True, which='major', axis='y') plt.subplot(223) age_survived['age_index'] = age_survived.index.astype(str) plt.bar(age_survived['age_index'], age_survived['生还人数'], color='b', alpha=0.7) plt.bar(age_survived['age_index'], age_survived['未生还人数'], bottom=age_survived['生还人数'], color='lightblue') plt.xticks(age_survived['age_index']) plt.title('按年龄获救情况') plt.xlabel('年龄分布') plt.ylabel('人数') plt.grid(b=True, which='major', axis='y')
使用循环优化代码后:
#各个维度的生还率 bins = [0,10,20,30,40,50,60,70,80] data['age_cut'] = pd.cut(data['Age'],bins,right=False) dataframe = ['sex_survived', 'pclass_survived', 'age_survived' , 'embarked_survived'] columns = ['Sex', 'Pclass', 'age_cut', 'Embarked'] for name in dataframe: for i in range(0,4): dataframe[i] = data.groupby(by=[columns[i]])['Survived'].agg({'总人数':np.size, '生还人数':np.sum}) dataframe[i]['未生还人数'] = dataframe[i]['总人数'] - dataframe[i]['生还人数'] dataframe[i]['生还率'] = dataframe[i]['生还人数'] / dataframe[i]['总人数'] print(dataframe) #画图 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] =False dataframe[2]['age_index'] = dataframe[2].index.astype(str) dataframe[2] = dataframe[2].set_index(dataframe[2]['age_index']) for j in range(0,4): plt.subplot(2,2,j+1) #将图形区域分成2行*2列,将图形设置在第1个位置 plt.bar(dataframe[j].index, dataframe[j]['生还人数'], color='b', alpha=0.7) plt.bar(dataframe[j].index, dataframe[j]['未生还人数'], bottom=dataframe[j]['生还人数'], color='lightblue') plt.title(columns[j]) plt.ylabel('人数') plt.grid(b=True, which='major', axis='y')
得到如下的图形:(宝蓝色为获救)
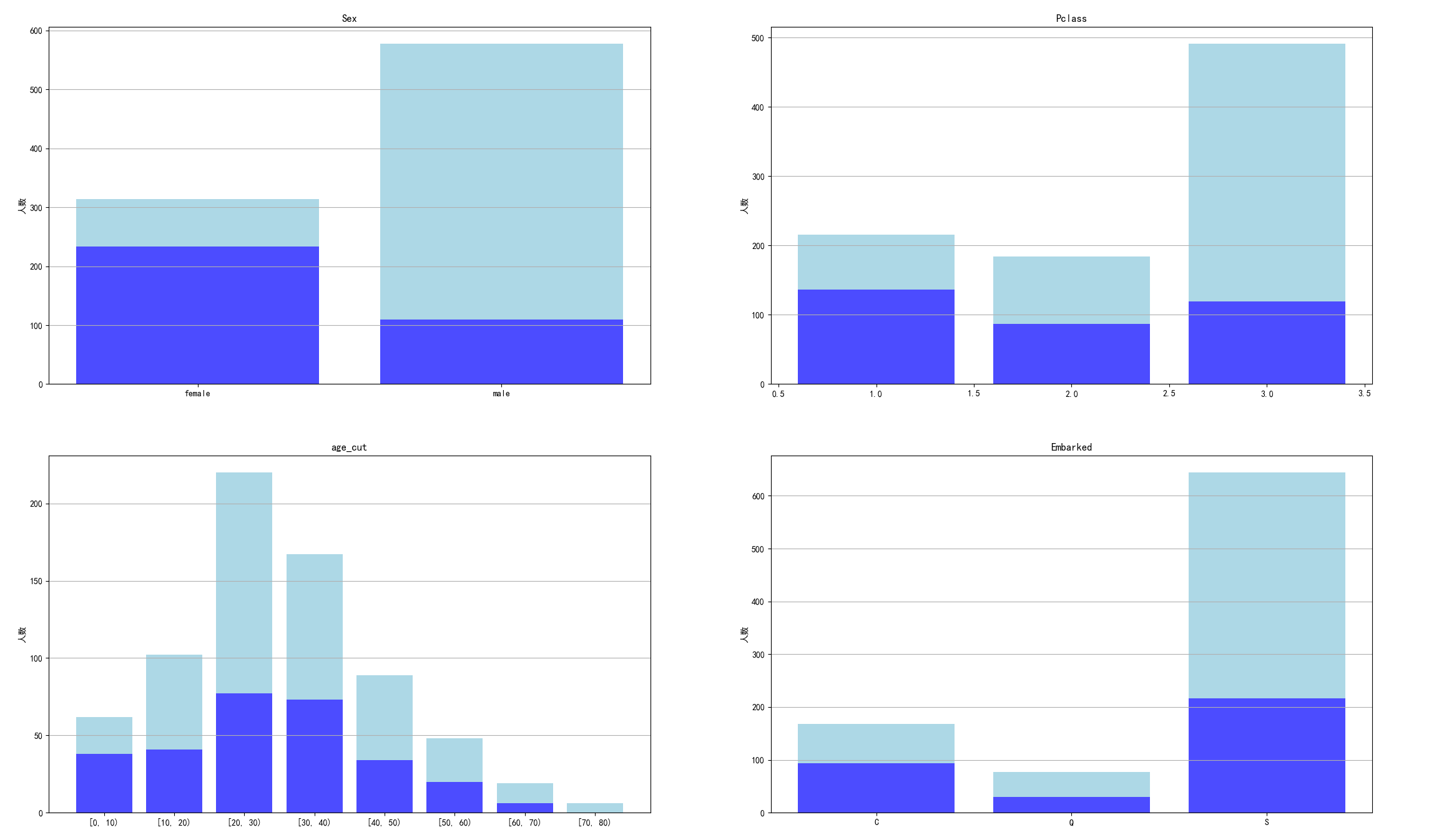
数据显示:女性生还率74.2%,男性生还率18.9%;1级乘客生还率最高;0-10岁生还率最高,60岁以上生还率最低;C港生还率最高,S港人数最多、生还率最低
得到结论:性别、年龄、乘客等级、登船港口都对是否获救有较大影响。
另:船票价格与乘客等级相关较强,但与生还率的关系不明显;堂兄弟、父母/小孩数量对生还结果没有明显影响。
2、数据处理
1)年龄的缺失项
由于年龄对于是否生还的影响还是比较明显,且缺失较多(缺失177个,接近20%),所以不能直接忽略缺失项或对缺失项做简单的均值、中位数等替换。
这里考虑使用随机森林对年龄进行预测填补:
https://scikit-learn.org/dev/modules/generated/sklearn.ensemble.RandomForestRegressor.html(随机森林官方文档)
#对年龄缺失项做随机森林进行填补 age_data = data[['Age','Fare', 'Parch', 'SibSp', 'Pclass']] fcolumns = ['Fare', 'Parch', 'SibSp', 'Pclass'] tcolumns = ['Age'] age_data_known = age_data[age_data.Age.notnull()] age_data_unknown = age_data[age_data.Age.isnull()] fdata = age_data_known[fcolumns]#特征变量 tdata = age_data_known[tcolumns]#目标变量 from sklearn.ensemble import RandomForestRegressor rfrmodel = RandomForestRegressor(n_jobs=-1) rfrmodel.fit(fdata, tdata ) predictedAges = rfrmodel.predict(age_data_unknown[fcolumns]) data.loc[data['Age'].isnull(), 'Age'] = predictedAges
#对登船港口的2个缺失项用众数进行填补
data.loc[data['Embarked'].isnull(), 'Embarked'] = 'S'
2)非数值型特征的虚拟化
由于性别、登船港口还都是字符型数据,所以需要对这两个特征做虚拟变换
#设置训练集及虚拟变量 data_train = pd.DataFrame([]) data_train[['ID', 'age', 'pclass', 'sibsp', 'parch', 'fare', 'survived']] = data[['PassengerId', 'Age','Pclass','SibSp','Parch','Fare','Survived']] #性别 data_train[['sex_female','sex_male']] = pd.get_dummies(data['Sex']) #登船港口 data_train[['embarked_C','embarked_Q','embarked_S']] = pd.get_dummies(data['Embarked']) data_train = data_train.set_index('ID')
3)数值特征标准化
由于年龄、船票价格两个特征跨度很大,所以对这两个特征做标准化处理
import sklearn.preprocessing as preprocessing scaler = preprocessing.MinMaxScaler() data_train['age'] = scaler.fit_transform(np.array(data_train['age']).reshape(891,-891)) data_train['fare'] = scaler.fit_transform(np.array(data_train['fare']).reshape(891,-891))
3、模型建立
首先使用逻辑回归模型
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html(逻辑回归官方文档)
from sklearn import linear_model lrModel = linear_model.LogisticRegression(penalty='l1') inputcolumns = ['age', 'pclass', 'sibsp', 'parch', 'fare', 'sex_female', 'sex_male', 'embarked_C', 'embarked_Q', 'embarked_S'] outpucolumns = ['survived'] lrModel.fit(data_train[inputcolumns], data_train[outpucolumns]) lrModel.score(data_train[inputcolumns], data_train[outpucolumns])#模型评分0.8
4、测试集处理
data2 = pd.read_csv(r'D:\kaggle\datafile\titanic\test.csv') data2.info()#年龄缺失,船票价格存在一个缺失项 data2.loc[data2['Fare'].isnull(), 'Fare'] = data2['Fare'].mean() #年龄缺失项处理 age_data2 = data2[['Age','Fare', 'Parch', 'SibSp', 'Pclass']] age_data2_known = age_data2[age_data2.Age.notnull()] age_data2_unknown = age_data2[age_data2.Age.isnull()] fdata2 = age_data2_known[fcolumns]#特征变量 tdata2 = age_data2_known[tcolumns]#目标变量 rfrmodel.fit(fdata2, tdata2) predictedAges2 = rfrmodel.predict(age_data2_unknown[fcolumns]) data2.loc[data2['Age'].isnull(), 'Age'] = predictedAges2
#构建训练集 data_test = pd.DataFrame([]) data_test[['ID', 'age', 'pclass', 'sibsp', 'parch', 'fare']] = data2[['PassengerId', 'Age','Pclass','SibSp','Parch','Fare']] #虚拟变量 data_test[['sex_female','sex_male']] = pd.get_dummies(data2['Sex'])#性别 data_test[['embarked_C','embarked_Q','embarked_S']] = pd.get_dummies(data2['Embarked'])#登船港口 #数值标准化 data_test['age'] = scaler.fit_transform(np.array(data_test['age']).reshape(418,-418)) data_test['fare'] = scaler.fit_transform(np.array(data_test['fare']).reshape(418,-418)) #得到测试集预测结果 predictions = lrModel.predict(data_test[inputcolumns]) result = pd.DataFrame({'PassengerId':data_test['PassengerId'], 'Survived':predictions})
如此就能够得到初步预测的结果了,后续会更新后面的优化等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号