
k8s docker集群搭建
一、Kubernetes系列之介绍篇
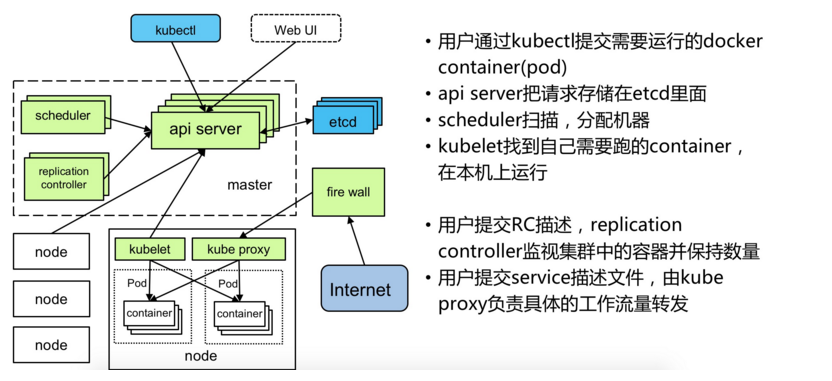
- 拥有一个唯一指定的名字
- 拥有一个虚拟IP(Cluster IP、Service IP、或VIP)和端口号
- 能够体统某种远程服务能力
- 被映射到了提供这种服务能力的一组容器应用上
- 目标Pod的定义
- 目标Pod需要运行的副本数量(Replicas)
- 要监控的目标Pod标签(Label)
- 每个Node节点都运行着以下一组关键进程
- kubelet:负责对Pod对于的容器的创建、启停等任务
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件
- Docker Engine(Docker):Docker引擎,负责本机容器的创建和管理工作
- Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址
- Cluster IP无法被ping,他没有一个“实体网络对象”来响应
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。
- 版本标签:"release":"stable","release":"canary"......
- 环境标签:"environment":"dev","environment":"qa","environment":"production"
- 架构标签:"tier":"frontend","tier":"backend","tier":"middleware"
- 分区标签:"partition":"customerA","partition":"customerB"
- 质量管控标签:"track":"daily","track":"weekly"
-
- kube-Controller进程通过资源对象RC上定义Label Selector来筛选要监控的Pod副本的数量,从而实现副本数量始终符合预期设定的全自动控制流程
- kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service岛对应Pod的请求转发路由表,从而实现Service的智能负载均衡
- 通过对某些Node定义特定的Label,并且在Pod定义文件中使用Nodeselector这种标签调度策略,kuber-scheduler进程可以实现Pod”定向调度“的特性
二、基于kubernetes构建Docker集群环境实战
|
1
2
|
#setenforce 0#sed -i '/^SELINUX=/cSELINUX=disabled' /etc/sysconfig/selinux |
|
1
|
# yum -y install etcd kubernetes |
配置etcd。确保列出的这些项都配置正确并且没有被注释掉,下面的配置都是如此
|
1
2
3
4
5
6
|
#vim /etc/etcd/etcd.conf ETCD_NAME=defaultETCD_DATA_DIR="/var/lib/etcd/default.etcd"ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379" |
配置kubernetes
|
1
2
3
4
5
6
7
8
|
vim /etc/kubernetes/apiserver KUBE_API_ADDRESS="--address=0.0.0.0"KUBE_API_PORT="--port=8080"KUBELET_PORT="--kubelet_port=10250"KUBE_ETCD_SERVERS="--etcd_servers=http://127.0.0.1:2379"KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"KUBE_ADMISSION_CONTROL="--admission_control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ResourceQuota"KUBE_API_ARGS="" |
|
1
|
# for SERVICES in etcd kube-apiserver kube-controller-manager kube-scheduler; do systemctl restart $SERVICES systemctl enable $SERVICES systemctl status $SERVICES donesystemctl restart etcd; systemctl enable etcd; systemctl status etcd; |
3.设置etcd网络
#ifconfig
flannel0: flags=4305<UP,POINTOPOINT,RUNNING,NOARP,MULTICAST> mtu 1472
inet 10.1.94.0 netmask 255.255.0.0 destination 10.1.94.0
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
如果没有出现网关 flannel0 , 那么执行下面的命令后,再次查看 ifconfig :
[~]# etcdctl mkdir /atomic.io/network
[~]# etcdctl mk /atomic.io/network/config '{"Network":"10.1.0.0/16"}'
|
1
|
# kubectl get nodes NAME LABELS STATUS |
|
1
|
# yum -y install flannel kubernetes |
配置kubernetes连接的服务端IP
|
1
2
3
|
#vim /etc/kubernetes/configKUBE_MASTER="--master=http://10.0.0.81:8080"KUBE_ETCD_SERVERS="--etcd_servers=http://10.0.0.81:2379" |
配置kubernetes ,(请使用每台minion自己的IP地址比如10.0.0.81:代替下面的$LOCALIP)
|
1
2
3
4
5
|
#vim /etc/kubernetes/kubelet<br>KUBELET_ADDRESS="--address=0.0.0.0"KUBELET_PORT="--port=10250"# change the hostname to this host’s IP address KUBELET_HOSTNAME="--hostname_override=$LOCALIP"KUBELET_API_SERVER="--api_servers=http://10.0.0.81:8080"KUBELET_ARGS="" |
|
1
2
3
4
5
|
# ifconfig docker0Link encap:Ethernet HWaddr 02:42:B2:75:2E:67 inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0 UPBROADCAST MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0RX bytes:0 (0.0 B) TX bytes:0 (0.0 B) |
warning:在运行过docker的机器上可以看到有docker0,这里在启动服务之前需要删掉docker0配置,在命令行运行:sudo ip link delete docker0
3.配置flannel网络
|
1
2
3
|
#vim /etc/sysconfig/flanneldFLANNEL_ETCD_ENDPOINTS="http://10.0.0.81:2379"FLANNEL_ETCD_PREFIX="/atomic.io/network" |
|
1
|
# for SERVICES in flanneld kube-proxy kubelet docker; do systemctl restart $SERVICES systemctl enable $SERVICES systemctl status $SERVICES donesystemctl restart kube-proxy; systemctl enable kube-proxy; systemctl status kube-proxy; |
|
1
2
3
4
|
# kubectl get nodesNAME STATUS AGE10.0.0.82 Ready 1m10.0.0.83 Ready 1m |
可以看到配置的两台minion已经在master的node列表中了。如果想要更多的node,只需要按照minion的配置,配置更多的机器就可以了。
三、Kubernetes之深入了解Pod
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
# yaml格式的pod定义文件完整内容:apiVersion: v1 #必选,版本号,例如v1kind: Pod #必选,Podmetadata: #必选,元数据 name: string #必选,Pod名称 namespace: string #必选,Pod所属的命名空间 labels: #自定义标签 - name: string #自定义标签名字 annotations: #自定义注释列表 - name: stringspec: #必选,Pod中容器的详细定义 containers: #必选,Pod中容器列表 - name: string #必选,容器名称 image: string #必选,容器的镜像名称 imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像 command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令 args: [string] #容器的启动命令参数列表 workingDir: string #容器的工作目录 volumeMounts: #挂载到容器内部的存储卷配置 - name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名 mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符 readOnly: boolean #是否为只读模式 ports: #需要暴露的端口库号列表 - name: string #端口号名称 containerPort: int #容器需要监听的端口号 hostPort: int #容器所在主机需要监听的端口号,默认与Container相同 protocol: string #端口协议,支持TCP和UDP,默认TCP env: #容器运行前需设置的环境变量列表 - name: string #环境变量名称 value: string #环境变量的值 resources: #资源限制和请求的设置 limits: #资源限制的设置 cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数 memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数 requests: #资源请求的设置 cpu: string #Cpu请求,容器启动的初始可用数量 memory: string #内存清楚,容器启动的初始可用数量 livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可 exec: #对Pod容器内检查方式设置为exec方式 command: [string] #exec方式需要制定的命令或脚本 httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port path: string port: number host: string scheme: string HttpHeaders: - name: string value: string tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式 port: number initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒 timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒 periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次 successThreshold: 0 failureThreshold: 0 securityContext: privileged:false restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定 imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定 - name: string hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络 volumes: #在该pod上定义共享存储卷列表 - name: string #共享存储卷名称 (volumes类型有很多种) emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值 hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录 path: string #Pod所在宿主机的目录,将被用于同期中mount的目录 secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部 scretname: string items: - key: string path: string configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部 name: string items: - key: string path: string |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
apiVersion:v1kind: Podmetadata: name: redis-php label: name: redis-phpspec: containers: - name: frontend image: kubeguide/guestbook-php-frontend:localredis ports: - containersPort: 80 - name: redis-php image:kubeguide/redis-master ports: - containersPort: 6379 |
|
1
2
3
|
#kubectl get godsNAME READY STATUS RESTATS AGEredis-php 2/2Running 0 10m |
可以看到READY信息为2/2,表示Pod中的两个容器都成功运行了.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
[root@kubernetes-master ~]# kubectl describe redis-phpthe server doesn't have a resourcetype "redis-php"[root@kubernetes-master ~]# kubectl describe pod redis-phpName: redis-phpNamespace: defaultNode: kubernetes-minion/10.0.0.23Start Time: Wed, 12 Apr 2017 09:14:58 +0800Labels: name=redis-phpStatus: RunningIP: 10.1.24.2Controllers: <none>Containers:nginx:Container ID: docker://d05b743c200dff7cf3b60b7373a45666be2ebb48b7b8b31ce0ece9be4546ce77Image: nginxImage ID: docker-pullable://docker.io/nginx@sha256:e6693c20186f837fc393390135d8a598a96a833917917789d63766cab6c59582Port: 80/TCPState: RunningStarted: Wed, 12 Apr 2017 09:19:31 +0800 |
|
1
2
3
4
5
|
#kubetctl delete pod static-web-node1pod "static-web-node1"deleted#kubectl get podsNAME READY STATUS RESTARTS AGEstatic-web-node1 0/1Pending 0 1s |
|
1
2
|
#rm -f /etc/kubelet.d/static-web.yaml#docker ps |

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
apiVersion:v1kind: Podmetadata: name: redis-php label: name: volume-podspec: containers: - name: tomcat image: tomcat ports: - containersPort: 8080 volumeMounts: - name: app-logs mountPath:/usr/local/tomcat/logs - name: busybox image:busybox command: ["sh","-C","tail -f /logs/catalina*.log"] volumes: - name: app-logs emptyDir:{} |
|
1
|
#kubectl logs volume-pod -c busybox |
|
1
|
#kubectl exec -ti volume-pod -c tomcat -- ls /usr/local/tomcat/logs |
|
1
2
3
4
5
6
7
8
|
# vim cm-appvars.yamlapiVersion: v1kind: ConfigMapmetadata: name: cm-appvarsdata: apploglevel: info appdatadir:/var/data |
|
1
2
|
#kubectl create -f cm-appvars.yamlconfigmap "cm-appvars.yaml"created |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#kubectl get configmapNAME DATA AGEcm-appvars 2 3s[root@kubernetes-master ~]# kubectl describe configmap cm-appvarsName: cm-appvarsNamespace: defaultLabels: <none>Annotations: <none> Data====appdatadir: 9 bytesapploglevel: 4 bytes[root@kubernetes-master ~]# kubectl get configmap cm-appvars -o yamlapiVersion: v1data:appdatadir: /var/dataapploglevel: infokind: ConfigMapmetadata:creationTimestamp: 2017-04-14T06:03:36Zname: cm-appvarsnamespace: defaultresourceVersion:"571221"selfLink: /api/v1/namespaces/default/configmaps/cm-appvarsuid: 190323cb-20d8-11e7-94ec-000c29ac8d83 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
apiVersion: v1kind: ConfigMapmetadata: name: cm-appvarsdata: key-serverxml: <?xml Version='1.0'encoding='utf-8'?> <Server port="8005"shutdown="SHUTDOWN"> ..... </service> </Server> key-loggingproperties: "handlers=lcatalina.org.apache.juli.FileHandler, ...." |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#vim cm-test-app.yamlapiVersion: v1kind: Podmetadata: name: cm-test-appspec: containers: - name: cm-test-app image: tomcat-app:v1 ports: - containerPort: 8080 volumeMounts: - name: serverxml #引用volume名 mountPath:/configfiles #挂载到容器内部目录 configMap: name: cm-test-appconfigfile #使用configmap定义的的cm-appconfigfile items: - key: key-serverxml #将key=key-serverxml path: server.xml #value将server.xml文件名进行挂载 - key: key-loggingproperties #将key=key-loggingproperties path: logging.properties #value将logging.properties文件名进行挂载 |
|
1
2
|
#kubectl create -f cm-test-app.yamlPod "cm-test-app"created |
|
1
2
3
|
#kubectl exec -ti cm-test-app -- bashroot@cm-rest-app:/# cat /configfiles/server.xmlroot@cm-rest-app:/# cat /configfiles/logging.properties |
-
- configmap必须在pod之间创建
- configmap也可以定义为属于某个Namespace,只有处于相同namespaces中的pod可以引用
- configmap中配额管理还未能实现
- kubelet只支持被api server管理的pod使用configmap,静态pod无法引用
- 在pod对configmap进行挂载操作时,容器内部职能挂载为目录,无法挂载文件。

-
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行
- Job:OnFailure或Nerver,确保容器执行完成后不再重启
- kubelet:在Pod失效时重启他,不论RestartPolicy设置什么值,并且也不会对Pod进行健康检查
-
- LivenessProbe探针:用于判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,则kubelet杀掉该容器,并根据容器的重启策略做响应处理
- ReadinessProbe探针:用于判断容器是否启动完成(ready状态),可以接受请求。如果ReadinessProbe探针探测失败,则Pod的状态被修改。Endpoint Controller将从service的Endpoint中删除包含该容器所在的Pod的Endpoint。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
apiVersion:v1kind: Podmetadata: name: liveness-exec label: name: livenessspec: containers: - name: tomcat image: grc.io/google_containers/tomcat args: -/bin/sh - -c -echo ok >/tmp.health;sleep10; rm -fr /tmp/health;sleep600 livenessProbe: exec: command: -cat -/tmp/health initianDelaySeconds:15 timeoutSeconds:1 |
|
1
2
3
4
5
6
7
8
9
10
11
12
|
kind: Podmetadata: name: pod-with-healthcheckspec: containers: - name: nginx image: nginx livenessProbe: tcpSocket: port: 80 initianDelaySeconds:30 timeoutSeconds:1 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
apiVersion:v1kind: Podmetadata: name: pod-with-healthcheckspec: containers: - name: nginx image: nginx livenessProbe: httpGet: path:/_status/healthz port: 80 initianDelaySeconds:30 timeoutSeconds:1 |
- initialDelaySeconds:启动容器后首次监控检查的等待时间,单位秒
- timeouSeconds:健康检查发送请求后等待响应的超时时间,单位秒。当发生超时就被认为容器无法提供服务无,该容器将被重启
|
1
|
#kubectllabel nodes k8s-node-1 zonenorth |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
apiVersion:v1kind: Podmetadata: name: redis-master label: name: redis-masterspec: replicas: 1 selector: name: redis-master template: metadata: labels: name: redis-master spec: containers: - name: redis-master images: kubeguide/redis-master ports: - containerPort: 6379 nodeSelector: zone: north |

- 在每个Node上运行个以GlusterFS存储或者ceph存储的daemon进程
- 在每个Node上运行一个日志采集程序,例如fluentd或者logstach
- 在每个Node上运行一个健康程序,采集Node的性能数据。
|
1
2
3
4
5
6
7
|
#kubectl scale rc redis-slave --replicas=3ReplicationController"redis-slave" scaled#kubectl get podsNAME READY STATUS RESTARTS AGEredis-slave-1sf23 1/1Running 0 1hredis-slave-54wfk 1/1Running 0 1hredis-slave-3da5y 1/1Running 0 1h |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
apiVersion: v1kind: replicationControllermetadata: name: redis-master-v2 labels: name: redis-master Version: v2spec: replicas: 1 selector: name: redis-master Version: v2 template: labels: name: redis-master Version: v2 spec: containers: - name: master images: kubeguide/redis-master:2.0 ports: - containerPort: 6379 |
需要注意的点:
|
1
|
#kubectl rolling-update redis-master -f redis-master-controller-v2.yaml |
|
1
|
#kubectl rolling-update redis-master --image=redis-master:2.0 |
解决pod创建成功但未正常启动的问题:pod-infrastructure镜像下载失败
https://blog.csdn.net/a632189007/article/details/78730903
https://blog.csdn.net/a632189007/article/details/78738732
解决kubectl get pods时 No resources found.问题
执行kubectl get pods,显示no resources found.
解决方法:
1、$ vi /etc/kubernetes/apiserver
2、找到这一行 "KUBE_ADMISSION_CONTROL="--admission_control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota",去掉ServiceAccount,保存退出。
3、重新启动kube-apiserver服务即可
发现错误open /etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt: no such file or directory,网上找的方法:
posted on 2018-06-18 17:05 clearriver 阅读(438) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号