序列化和反序列化
序列化
- 将内存中对象存储下来,把他变成一个个字节
反序列化
- 将文件的一个个字节恢复成内存对象
pickle库
- dumps 对象序列化为bytes对象
- dump 对象序列化到文件对象,存入文件
- loads 从bytes对象反序列化
- load 对象反序列化,从文件读取数据
示例:
import pickle filename = 'test.txt' d = {'a':1,'b':'qwe','c':[1,2,3]} l = list('123') i = 99 with open(filename,'wb') as f: #序列化 pickle.dump(d,f) pickle.dump(l,f) pickle.dump(i,f) with open(filename,'rb') as f: #反序列化 print(f.read(),f.seek(0)) for _ in range(3): x = pickle.load(f) print(type(x),x)
输出为:
b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01K\x01X\x01\x00\x00\x00bq\x02X\x03\x00\x00\x00qweq\x03X\x01\x00\x00\x00cq\x04]q\x05(K\x01K\x02K\x03eu.\x80\x03]q\x00(X\x01\x00\x00\x001q\x01X\x01\x00\x00\x002q\x02X\x01\x00\x00\x003q\x03e.\x80\x03Kc.' 0 <class 'dict'> {'a': 1, 'b': 'qwe', 'c': [1, 2, 3]} <class 'list'> ['1', '2', '3'] <class 'int'> 99
示例:
import pickle class AA: tttt = 'abc' def show(self): print('def') a1 = AA() sr = pickle.dumps(a1) print('sr={}'.format(sr)) #AA a2 = pickle.loads(sr) print(a2.tttt) a2.show()
输出为:
sr=b'\x80\x03c__main__\nAA\nq\x00)\x81q\x01.' abc def
以上只序列化了一个AA类名,反序列化的时候找到类就可以恢复一个对象
序列化应用
本地序列化的情况应用较少,大多场景应用在网络传输中
将数据序列化后通过网络传输到远程节点,远程服务器上的服务奖接收到的数据反序列化后就可以使用
需要注意,远程接收端,反序列化时必须有对应的数据类型,否则会报错,尤其是自定义类,必须远程有一致定义
现在大多数项目需要通过网络将数据传送到其他节点,这就需要大量的序列化,反序列化过程
python程序之间可以使用pickle解决序列化,反序列化,如果跨平台,跨语言,跨协议pickle就不适用了
不同的协议,效率不同,适用场景不同,要根据不同情况分析选择
json
json是一个轻量级的数据交换格式,他基于ecmascript的一个子集,采用完全独立于变成语言的文本格式来存储和表示数据
示例:
{ "person":[ { "name":"tom", "aeg":18 }, { "name": "jerry", "aeg": 18 } ], "total": 2 }
json模块
python与json
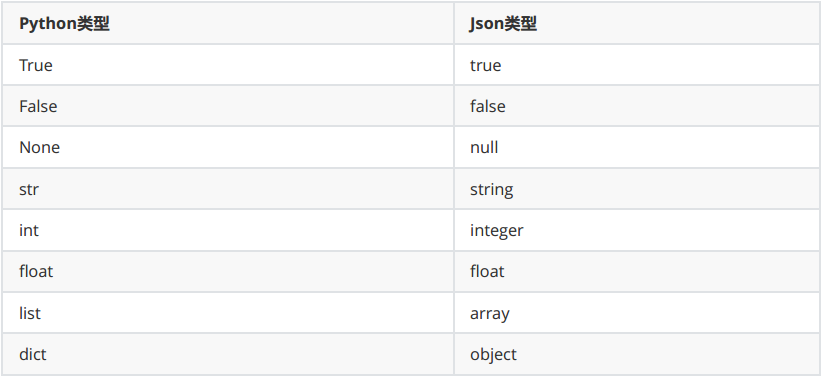
常用方法

示例:
import json d = {'name':'tom','age':20,'interest':['music','movie']} j = json.dumps(d) print(j,type(j)) d1 = json.loads(j) print(d1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号