[从动捕到动画] MMD入门资料集 (win10_x64 + openpose 1.7.0 + openMMD 1.0 生成 MikuMikuDance 可用的 vmd数据)
再:
百度云盘 http://pan.baidu.com/s/1L-TxEsgXD3zRHTAM8YQd7w
提取码:82qe
注意,按文章中的步骤,安装相应版本的包。
参照 上文 的步骤进行下列步骤。
(视频文件需要先裁剪成 定机位、单人, 且始终是该人物完整出镜,的视频片段)
(文件名、目录名中 不要带有空格!)
①①①①①
打开OpenposeVideo.bat,拖入你的视频文件或者图片,一路回车,执行完毕后会生成_json文件夹和生成的视频文件。
第一步中,执行 OpenposeVideo.bat 脚本前,将 这行注释掉

然后去 安装好的 openpose v1.7.0 对应的目录(bin\ 的上一层)下执行该脚本,
如下:

他会执行对应的 bin\OpenPoseDemo.exe 来生成 新格式的 keypoints 文件。
但是 openpose v1.7.0 生成的特征数据是 25个姿态关节点的。
打开OpenposeTo3D.bat,拖入_json文件夹,生成类似json_3d_2019xxxx_1xxxx_idx01的文件夹
Openpose的早期版本检测人体的18个姿态关节点,较新版本检测人体的25个姿态关节点,这就涉及到两种关节点的对应和转换问题。
如下图所示:

需要修改 3d-pose-baseline-vmd/src/openpose_3dpose_sandbox_vmd.py
读取 ”pose_keypoints_2d" 时,需要对 _tmp_data 做转换。
这个 .py 在上文第二步的 OpenposeTo3D.bat 中会被调用。
修改后的完整代码如下:


#!/usr/bin/env python # -*- coding: utf-8 -*- # # openpose_3dpose_sandbox_vmd.py import numpy as np import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import tensorflow as tf import data_utils import viz import re import cameras import json import os from predict_3dpose import create_model import cv2 import imageio import logging import datetime from collections import Counter FLAGS = tf.app.flags.FLAGS order = [15, 12, 25, 26, 27, 17, 18, 19, 1, 2, 3, 6, 7, 8] logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) level = {0:logging.ERROR, 1:logging.WARNING, 2:logging.INFO, 3:logging.DEBUG} def show_anim_curves(anim_dict, _plt): val = np.array(list(anim_dict.values())) for o in range(0,36,2): x = val[:,o] y = val[:,o+1] logger.debug("x") logger.debug(x) logger.debug("y") logger.debug(y) _plt.plot(x, 'r--', linewidth=0.2) _plt.plot(y, 'g', linewidth=0.2) return _plt def read_openpose_json(now_str, idx, subdir, smooth=True, *args): # openpose output format: # [x1,y1,c1,x2,y2,c2,...] # ignore confidence score, take x and y [x1,y1,x2,y2,...] logger.info("start reading data") #load json files json_files = os.listdir(openpose_output_dir) # check for other file types json_files = sorted([filename for filename in json_files if filename.endswith(".json")]) cache = {} smoothed = {} _past_tmp_points = [] _past_tmp_data = [] _tmp_data_25 = [] # new format of openpose v1.7.0 _tmp_data_18 = [] # old format for openMMD v1.0 joint_index = [0, 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18] # map data_25[] to data_18[] ### extract x,y and ignore confidence score for file_name in json_files: logger.debug("reading {0}".format(file_name)) _file = os.path.join(openpose_output_dir, file_name) if not os.path.isfile(_file): raise Exception("No file found!!, {0}".format(_file)) data = json.load(open(_file)) # 12桁の数字文字列から、フレームINDEX取得 frame_indx = re.findall("(\d{12})", file_name) if int(frame_indx[0]) <= 0: # 最初のフレームはそのまま登録するため、INDEXをそのまま指定 _tmp_data_25 = data["people"][idx]["pose_keypoints_2d"] _tmp_data_18 = [] for j in joint_index: _tmp_data_18.append(_tmp_data_25[3*j+0]) _tmp_data_18.append(_tmp_data_25[3*j+1]) _tmp_data_18.append(_tmp_data_25[3*j+2]) else: # 前フレームと一番近い人物データを採用する past_xy = cache[int(frame_indx[0]) - 1] # データが取れていたら、そのINDEX数分配列を生成。取れてなかったら、とりあえずINDEX分確保 target_num = len(data["people"]) if len(data["people"]) >= idx + 1 else idx + 1 # 同一フレーム内の全人物データを一旦保持する _tmp_points = [[0 for i in range(target_num)] for j in range(36)] #print('_tmp_points:') #print( _tmp_points ) # logger.debug("_past_tmp_points") # logger.debug(_past_tmp_points) for _data_idx in range(idx + 1): if len(data["people"]) - 1 < _data_idx: for o in range(len(_past_tmp_points)): # 人物データが取れていない場合、とりあえず前回のをコピっとく # logger.debug("o={0}, _data_idx={1}".format(o, _data_idx)) # logger.debug(_tmp_points) # logger.debug(_tmp_points[o][_data_idx]) # logger.debug(_past_tmp_points[o][_data_idx]) _tmp_points[o][_data_idx] = _past_tmp_points[o][_data_idx] # データも前回のを引き継ぐ _tmp_data_18 = _past_tmp_data else: # ちゃんと取れている場合、データ展開 _tmp_data_25 = data["people"][_data_idx]["pose_keypoints_2d"] _tmp_data_18 = [] for j in joint_index: _tmp_data_18.append(_tmp_data_25[3*j+0]) _tmp_data_18.append(_tmp_data_25[3*j+1]) _tmp_data_18.append(_tmp_data_25[3*j+2]) n = 0 # print(' len of _tmp_data_18 = %d' % len(_tmp_data_18) ) # print( _tmp_data_18 ) for o in range(0,len(_tmp_data_18),3): # logger.debug("o: {0}".format(o)) # logger.debug("len(_tmp_points): {0}".format(len(_tmp_points))) # logger.debug("len(_tmp_points[o]): {0}".format(len(_tmp_points[n]))) # logger.debug("_tmp_data_18[o]") # logger.debug(_tmp_data_18[o]) # print(' n=%d _data_idx=%d o=%d' % (n, _data_idx, o) ) # if o == joint_index[j]: _tmp_points[n][_data_idx] = _tmp_data_18[o] n += 1 _tmp_points[n][_data_idx] = _tmp_data_18[o+1] n += 1 # とりあえず前回のを保持 _past_tmp_data = _tmp_data_18 _past_tmp_points = _tmp_points # logger.debug("_tmp_points") # logger.debug(_tmp_points) # 各INDEXの前回と最も近い値を持つINDEXを取得 nearest_idx_list = [] for n, plist in enumerate(_tmp_points): nearest_idx_list.append(get_nearest_idx(plist, past_xy[n])) most_common_idx = Counter(nearest_idx_list).most_common(1) # 最も多くヒットしたINDEXを処理対象とする target_idx = most_common_idx[0][0] logger.debug("target_idx={0}".format(target_idx)) _data = _tmp_data_18 xy = [] #ignore confidence score for o in range(0,len(_data),3): xy.append(_data[o]) xy.append(_data[o+1]) logger.debug("found {0} for frame {1}".format(xy, str(int(frame_indx[0])))) #add xy to frame cache[int(frame_indx[0])] = xy plt.figure(1) drop_curves_plot = show_anim_curves(cache, plt) pngName = '{0}/dirty_plot.png'.format(subdir) drop_curves_plot.savefig(pngName) # exit if no smoothing if not smooth: # return frames cache incl. 18 joints (x,y) return cache if len(json_files) == 1: logger.info("found single json file") # return frames cache incl. 18 joints (x,y) on single image\json return cache if len(json_files) <= 8: raise Exception("need more frames, min 9 frames/json files for smoothing!!!") logger.info("start smoothing") # create frame blocks first_frame_block = [int(re.findall("(\d{12})", o)[0]) for o in json_files[:4]] last_frame_block = [int(re.findall("(\d{12})", o)[0]) for o in json_files[-4:]] ### smooth by median value, n frames for frame, xy in cache.items(): # create neighbor array based on frame index forward, back = ([] for _ in range(2)) # joints x,y array _len = len(xy) # 36 # create array of parallel frames (-3<n>3) for neighbor in range(1,4): # first n frames, get value of xy in postive lookahead frames(current frame + 3) if frame in first_frame_block: # print ("first_frame_block: len(cache)={0}, frame={1}, neighbor={2}".format(len(cache), frame, neighbor)) forward += cache[frame+neighbor] # last n frames, get value of xy in negative lookahead frames(current frame - 3) elif frame in last_frame_block: # print ("last_frame_block: len(cache)={0}, frame={1}, neighbor={2}".format(len(cache), frame, neighbor)) back += cache[frame-neighbor] else: # between frames, get value of xy in bi-directional frames(current frame -+ 3) forward += cache[frame+neighbor] back += cache[frame-neighbor] # build frame range vector frames_joint_median = [0 for i in range(_len)] # more info about mapping in src/data_utils.py # for each 18joints*x,y (x1,y1,x2,y2,...)~36 for x in range(0,_len,2): # set x and y y = x+1 if frame in first_frame_block: # get vector of n frames forward for x and y, incl. current frame x_v = [xy[x], forward[x], forward[x+_len], forward[x+_len*2]] y_v = [xy[y], forward[y], forward[y+_len], forward[y+_len*2]] elif frame in last_frame_block: # get vector of n frames back for x and y, incl. current frame x_v =[xy[x], back[x], back[x+_len], back[x+_len*2]] y_v =[xy[y], back[y], back[y+_len], back[y+_len*2]] else: # get vector of n frames forward/back for x and y, incl. current frame # median value calc: find neighbor frames joint value and sorted them, use numpy median module # frame[x1,y1,[x2,y2],..]frame[x1,y1,[x2,y2],...], frame[x1,y1,[x2,y2],..] # ^---------------------|-------------------------^ x_v =[xy[x], forward[x], forward[x+_len], forward[x+_len*2], back[x], back[x+_len], back[x+_len*2]] y_v =[xy[y], forward[y], forward[y+_len], forward[y+_len*2], back[y], back[y+_len], back[y+_len*2]] # get median of vector x_med = np.median(sorted(x_v)) y_med = np.median(sorted(y_v)) # holding frame drops for joint if not x_med: # allow fix from first frame if frame: # get x from last frame x_med = smoothed[frame-1][x] # if joint is hidden y if not y_med: # allow fix from first frame if frame: # get y from last frame y_med = smoothed[frame-1][y] logger.debug("old X {0} sorted neighbor {1} new X {2}".format(xy[x],sorted(x_v), x_med)) logger.debug("old Y {0} sorted neighbor {1} new Y {2}".format(xy[y],sorted(y_v), y_med)) # build new array of joint x and y value frames_joint_median[x] = x_med frames_joint_median[x+1] = y_med smoothed[frame] = frames_joint_median # return frames cache incl. smooth 18 joints (x,y) return smoothed def get_nearest_idx(target_list, num): """ 概要: リストからある値に最も近い値のINDEXを返却する関数 @param target_list: データ配列 @param num: 対象値 @return 対象値に最も近い値のINDEX """ # logger.debug(target_list) # logger.debug(num) # リスト要素と対象値の差分を計算し最小値のインデックスを取得 idx = np.abs(np.asarray(target_list) - num).argmin() return idx def main(_): # 出力用日付 now_str = "{0:%Y%m%d_%H%M%S}".format(datetime.datetime.now()) logger.debug("FLAGS.person_idx={0}".format(FLAGS.person_idx)) # 日付+indexディレクトリ作成 subdir = '{0}/{1}_3d_{2}_idx{3:02d}'.format(os.path.dirname(openpose_output_dir), os.path.basename(openpose_output_dir), now_str, FLAGS.person_idx) os.makedirs(subdir) frame3d_dir = "{0}/frame3d".format(subdir) os.makedirs(frame3d_dir) #関節位置情報ファイル posf = open(subdir +'/pos.txt', 'w') #正規化済みOpenpose位置情報ファイル smoothedf = open(subdir +'/smoothed.txt', 'w') idx = FLAGS.person_idx - 1 smoothed = read_openpose_json(now_str, idx, subdir) logger.info("reading and smoothing done. start feeding 3d-pose-baseline") logger.debug(smoothed) plt.figure(2) smooth_curves_plot = show_anim_curves(smoothed, plt) pngName = subdir + '/smooth_plot.png' smooth_curves_plot.savefig(pngName) enc_in = np.zeros((1, 64)) enc_in[0] = [0 for i in range(64)] actions = data_utils.define_actions(FLAGS.action) SUBJECT_IDS = [1, 5, 6, 7, 8, 9, 11] rcams = cameras.load_cameras(FLAGS.cameras_path, SUBJECT_IDS) train_set_2d, test_set_2d, data_mean_2d, data_std_2d, dim_to_ignore_2d, dim_to_use_2d = data_utils.read_2d_predictions( actions, FLAGS.data_dir) train_set_3d, test_set_3d, data_mean_3d, data_std_3d, dim_to_ignore_3d, dim_to_use_3d, train_root_positions, test_root_positions = data_utils.read_3d_data( actions, FLAGS.data_dir, FLAGS.camera_frame, rcams, FLAGS.predict_14) before_pose = None device_count = {"GPU": 1} png_lib = [] with tf.Session(config=tf.ConfigProto( device_count=device_count, allow_soft_placement=True)) as sess: #plt.figure(3) batch_size = 128 model = create_model(sess, actions, batch_size) for n, (frame, xy) in enumerate(smoothed.items()): logger.info("calc idx {0}, frame {1}".format(idx, frame)) # map list into np array joints_array = np.zeros((1, 36)) joints_array[0] = [0 for i in range(36)] for o in range(len(joints_array[0])): #feed array with xy array joints_array[0][o] = xy[o] _data = joints_array[0] smoothedf.write(' '.join(map(str, _data))) smoothedf.write("\n") # mapping all body parts or 3d-pose-baseline format for i in range(len(order)): for j in range(2): # create encoder input enc_in[0][order[i] * 2 + j] = _data[i * 2 + j] for j in range(2): # Hip enc_in[0][0 * 2 + j] = (enc_in[0][1 * 2 + j] + enc_in[0][6 * 2 + j]) / 2 # Neck/Nose enc_in[0][14 * 2 + j] = (enc_in[0][15 * 2 + j] + enc_in[0][12 * 2 + j]) / 2 # Thorax enc_in[0][13 * 2 + j] = 2 * enc_in[0][12 * 2 + j] - enc_in[0][14 * 2 + j] # set spine spine_x = enc_in[0][24] spine_y = enc_in[0][25] # logger.debug("enc_in - 1") # logger.debug(enc_in) enc_in = enc_in[:, dim_to_use_2d] mu = data_mean_2d[dim_to_use_2d] stddev = data_std_2d[dim_to_use_2d] enc_in = np.divide((enc_in - mu), stddev) dp = 1.0 dec_out = np.zeros((1, 48)) dec_out[0] = [0 for i in range(48)] _, _, poses3d = model.step(sess, enc_in, dec_out, dp, isTraining=False) all_poses_3d = [] enc_in = data_utils.unNormalizeData(enc_in, data_mean_2d, data_std_2d, dim_to_ignore_2d) poses3d = data_utils.unNormalizeData(poses3d, data_mean_3d, data_std_3d, dim_to_ignore_3d) gs1 = gridspec.GridSpec(1, 1) gs1.update(wspace=-0.00, hspace=0.05) # set the spacing between axes. plt.axis('off') all_poses_3d.append( poses3d ) enc_in, poses3d = map( np.vstack, [enc_in, all_poses_3d] ) subplot_idx, exidx = 1, 1 max = 0 min = 10000 # logger.debug("enc_in - 2") # logger.debug(enc_in) for i in range(poses3d.shape[0]): for j in range(32): tmp = poses3d[i][j * 3 + 2] poses3d[i][j * 3 + 2] = poses3d[i][j * 3 + 1] poses3d[i][j * 3 + 1] = tmp if poses3d[i][j * 3 + 2] > max: max = poses3d[i][j * 3 + 2] if poses3d[i][j * 3 + 2] < min: min = poses3d[i][j * 3 + 2] for i in range(poses3d.shape[0]): for j in range(32): poses3d[i][j * 3 + 2] = max - poses3d[i][j * 3 + 2] + min poses3d[i][j * 3] += (spine_x - 630) poses3d[i][j * 3 + 2] += (500 - spine_y) # Plot 3d predictions ax = plt.subplot(gs1[subplot_idx - 1], projection='3d') ax.view_init(18, 280) logger.debug(np.min(poses3d)) if np.min(poses3d) < -1000 and before_pose is not None: poses3d = before_pose p3d = poses3d # logger.debug("poses3d") # logger.debug(poses3d) if level[FLAGS.verbose] == logging.INFO: viz.show3Dpose(p3d, ax, lcolor="#9b59b6", rcolor="#2ecc71") # 各フレームの単一視点からのはINFO時のみ pngName = frame3d_dir + '/tmp_{0:012d}.png'.format(frame) plt.savefig(pngName) png_lib.append(imageio.imread(pngName)) before_pose = poses3d # 各フレームの角度別出力はデバッグ時のみ if level[FLAGS.verbose] == logging.DEBUG: for azim in [0, 45, 90, 135, 180, 225, 270, 315, 360]: ax2 = plt.subplot(gs1[subplot_idx - 1], projection='3d') ax2.view_init(18, azim) viz.show3Dpose(p3d, ax2, lcolor="#FF0000", rcolor="#0000FF", add_labels=True) pngName2 = frame3d_dir + '/tmp_{0:012d}_{1:03d}.png'.format(frame, azim) plt.savefig(pngName2) #関節位置情報の出力 write_pos_data(poses3d, ax, posf) posf.close() # INFO時は、アニメーションGIF生成 if level[FLAGS.verbose] == logging.INFO: logger.info("creating Gif {0}/movie_smoothing.gif, please Wait!".format(subdir)) imageio.mimsave('{0}/movie_smoothing.gif'.format(subdir), png_lib, fps=FLAGS.gif_fps) logger.info("Done!".format(pngName)) def write_pos_data(channels, ax, posf): assert channels.size == len(data_utils.H36M_NAMES)*3, "channels should have 96 entries, it has %d instead" % channels.size vals = np.reshape( channels, (len(data_utils.H36M_NAMES), -1) ) I = np.array([1,2,3,1,7,8,1, 13,14,15,14,18,19,14,26,27])-1 # start points J = np.array([2,3,4,7,8,9,13,14,15,16,18,19,20,26,27,28])-1 # end points # LR = np.array([1,1,1,0,0,0,0, 0, 0, 0, 0, 0, 0, 1, 1, 1], dtype=bool) #出力済みINDEX outputed = [] # Make connection matrix for i in np.arange( len(I) ): x, y, z = [np.array( [vals[I[i], j], vals[J[i], j]] ) for j in range(3)] # for j in range(3): # logger.debug("i={0}, j={1}, [vals[I[i], j]={2}, vals[J[i], j]]={3}".format(str(i), str(j), str(vals[I[i], j]), str(vals[J[i], j]))) # 始点がまだ出力されていない場合、出力 if I[i] not in outputed: # 0: index, 1: x軸, 2:Y軸, 3:Z軸 logger.debug("I -> x={0}, y={1}, z={2}".format(x[0], y[0], z[0])) posf.write(str(I[i]) + " "+ str(x[0]) +" "+ str(y[0]) +" "+ str(z[0]) + ", ") outputed.append(I[i]) # 終点がまだ出力されていない場合、出力 if J[i] not in outputed: logger.debug("J -> x={0}, y={1}, z={2}".format(x[1], y[1], z[1])) posf.write(str(J[i]) + " "+ str(x[1]) +" "+ str(y[1]) +" "+ str(z[1]) + ", ") outputed.append(J[i]) # xyz.append([x, y, z]) # lines = ax.plot(x, y, z) # logger.debug("lines") # logger.debug(dir(lines)) # for l in lines: # logger.debug("l.get_data: ") # logger.debug(l.get_data()) # logger.debug("l.get_data orig: ") # logger.debug(l.get_data(True)) # logger.debug("l.get_path: ") # logger.debug(l.get_path()) #終わったら改行 posf.write("\n") if __name__ == "__main__": openpose_output_dir = FLAGS.openpose logger.setLevel(level[FLAGS.verbose]) tf.app.run()
修改后,骨骼数据正常,如下:

修改前,生成的骨骼数据是类似这样的:

腿部明显错误。
上文第二部中生成的 movie_smoothing.gif 如下,看起比较正常。

③③③③③
打开VideoToDepth.bat,拖入生成好的视频文件和json_3d_2019xxxx_1xxxx_idx01文件夹,一路回车。
FCRN-DepthPrediction-vmd\ 下
执行 VideoToDepth.bat

在步骤2生成的子目录中,生成 depth 数据,movie_depth.gif如下:
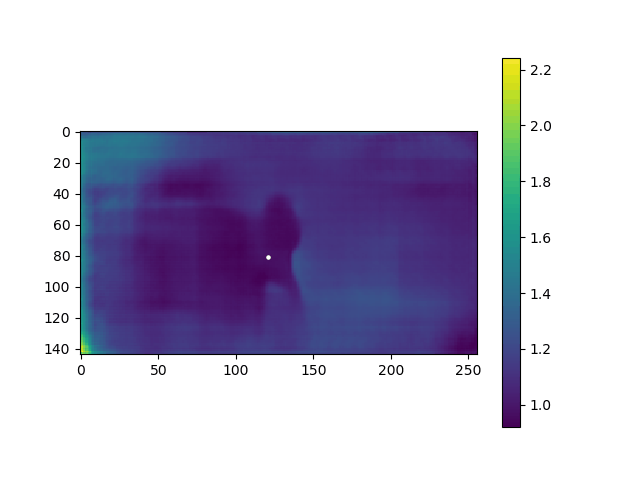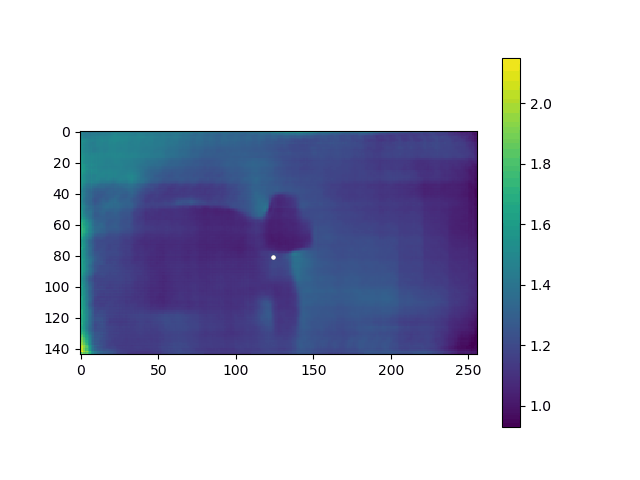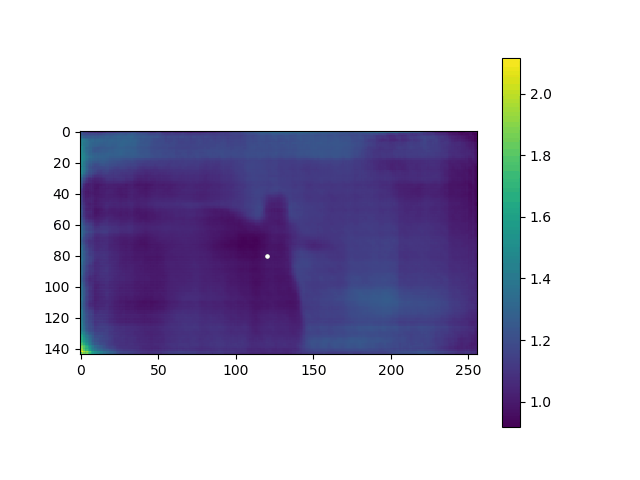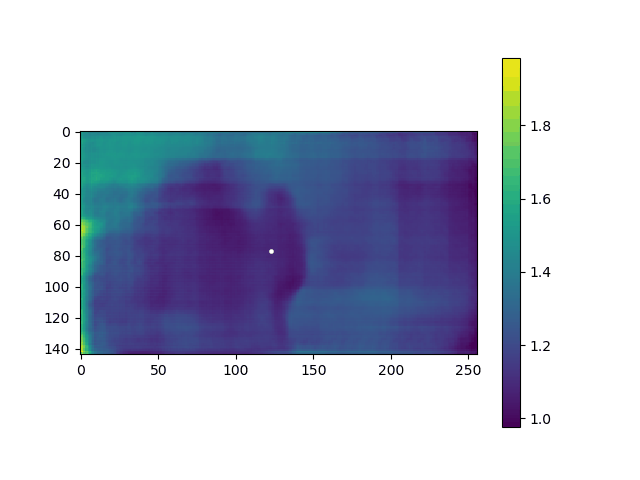
④④④④④
打开3DToVmd.bat,先拖入json_3d_2019xxxx_1xxxx_idx01文件夹,接着找到born文件夹里的あにまさ式ミクボーン.csv拖入,不拖入的话会出现编码错误,一路回车。
如果出现unrecognized arguments: -s 1错误,就删掉3DToVmd.bat文件最后一行里的’-s %SMOOTH_TIMES%’
VMD-3d-pose-baseline-mult\ 下,

最后,在步骤②的目录下,生成 output_*****.vmd 文件
⑤⑤⑤⑤⑤
最后, openMMD 自带的 MikuMikuDance 无法在win10下运行。
先安装目录下的 Visual C++ 2008 和 Visual C++ 2010
再次运行时,提示:

360安全卫士提示 需要做 directX 修复:

“检测并修复” 后,
之后即可启动 MikuMikuDance.exe

如上图,依次:
载入模型
导入动作数据
播放
即可看到成果 :D
人物如果转身的话,最后MMD里的动作会胡乱地转来转去!太糟糕了。
人物衣物、皮肤 如果色差不明显的话,识别效果也堪忧, 甚至左右 手、腿 都会识别错误。
OpenPose and MMD are only the "entrance" and "exit" of the application box. There are three intermediate pre-trained Deep Learning Models in the box to process and convert formatted data. They are stated in the Features section below.

OpenMMD represents the OpenPose-Based Deep-Learning project that can directly convert real-person videos to the motion of animation models (i.e. Miku, Anmicius). OpenMMD can be referred as OpenPose + MikuMikuDance (MMD).
基于视频的动作捕捉方案一览

 浙公网安备 33010602011771号
浙公网安备 33010602011771号