
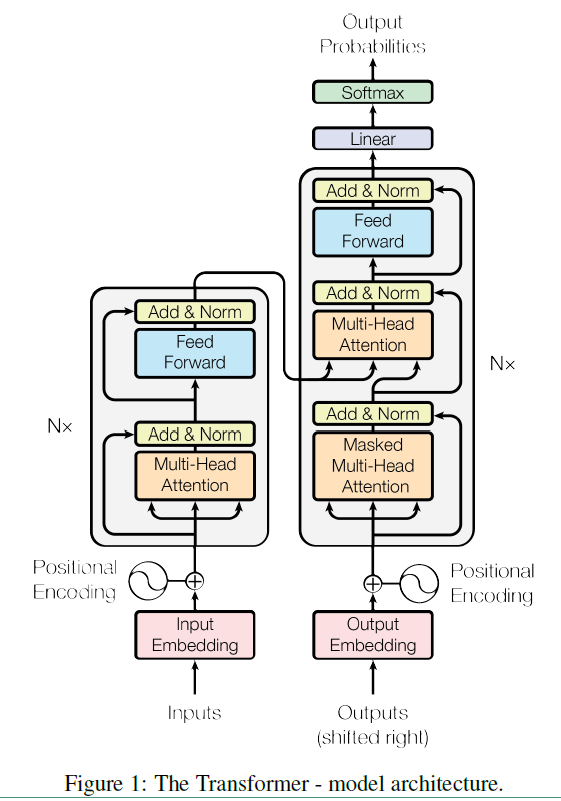
Tranformer模型学习
Word Embedding
- Word2Vec
- Glove
RNN改进与拓展
- Seq2Seq
- LSTM/GRU
- attention/self-attention
Tranformer模型学习
全部采用self-attention 层进行编码,引入三个变换矩阵,得到Q K V向量,然后利用词与词之间Q K相乘的结构进行注意力计算,将权重系数乘以V就是新的词向量表示。
位置向量
- self-attention计算并没有考虑位置信息,如果将K,V的顺序打乱,获得的Attention的结果还是一样的, 因此要引入位置嵌入
- 位置嵌入的维度和字向量的维度一致,将每个位置编号,然后每个编号对应这一向量,最后将该向量和词向量相加(注意是相加而不是拼接),这样就给每个词引入了一定的位置信息。
Multi-head Attention 计算过程
-
- 插入最新理解(不一定对)首先词向量经过变换矩阵变成\(QKV\) ,然后把QKV等分h份,然后经过不同的权重\(W_i\)变换,得到新的\(Q_i,K_i,V_i\)
-
假设现在头数是\(h\),首先将向量长度等分为\(h\)份
-
然后将等分后的数据通过不同的权重(\(W_i^Q\),\(W_i^K\),\(W_i^V\),)映射得到新的\(Q,K,W\)值,
-
将上述映射的h分数据计算相应的attention的值
-
按照之前分割的形式重新拼接起来,再映射到原始的向量维度。就可以得到Multi-head-Attention的值
其实认真来看Multi-Head Attention的机制有点类似与卷积中的多个卷积核,在卷积网络中,我们认为不同的卷积核会捕获不同的局部信息,在这里也是一样,我们认为Multi-Head Attention主要有两个作用:
1)增加了模型捕获不同位置信息的能力,如果你直接用映射前的Q, K, V计算,只能得到一个固定的权重概率分布,而这个概率分布会重点关注一个位置或个几个位置的信息,但是基于Multi-Head Attention的话,可以和更多的位置上的词关联起来。
2)因为在进行映射时不共享权值,因此映射后的子空间是不同的,认为不同的子空间涵盖的信息是不一样的,这样最后拼接的向量涵盖的信息会更广。
有实验证明,增加Mult-Head Attention的头数,是可以提高模型的长距离信息捕捉能力的。
Attention Mask
- 由于有的句子padding后部分为0,当进行\(Softmax\)计算时,0会使计算产生偏差,因此采用mask方法进行补偿 即把0的位置改成很大的负数
残差连接
- 我们在上一步得到了经过注意力矩阵加权之后的\(V\), 也就是\(Attention(Q, \ K, \ V)\), 我们对它进行一下转置, 使其和\(X_{embedding}\)的维度一致, 也就是\([batch \ size, \ sequence \ length, \ embedding \ dimension]\), 然后把他们加起来做残差连接, 直接进行元素相加, 因为他们的维度一致
layer normalization
-
作用是吧神经网络中的隐藏层归一化为标准正太分布,也就是\(i.i.d\)独立同分布 ,以起到加快训练速度,加速收敛的过程,
-
\[\mu_{i}=\frac{1}{m} \sum^{m}_{i=1}x_{ij}$$ 上式中以矩阵的行$(row)$为单位求均值 \]
(x_{ij}-\mu_{j})^{2}$$ 上式中以矩阵的行\((row)\)为单位求方差; $$LayerNorm(x)=\alpha \odot \frac{x_{ij}-\mu_{i}}
{\sqrt{\sigma^{2}_{i}+\epsilon}} + \beta \tag{eq.6}$$ 然后用每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值, \(\epsilon\)是为了防止除\(0\);
之后引入两个可训练参数\(\alpha, \ \beta\)来弥补归一化的过程中损失掉的信息, 注意\(\odot\)表示元素相乘而不是点积, 我们一般初始化\(\alpha\)为全\(1\), 而\(\beta\)为全\(0\). -
\[X_{attention} = X + X_{attention} \]
-
\[X_{attention} = LayerNorm(X_{attention}) \]
FeedForward
-
\[X_{hidden} = Activate(Linear(Linear(X_{attention}))) \tag{eq. 7}$$ 5). \]
\[X_{hidden} = X_{attention} + X_{hidden} \]\[X_{hidden} = LayerNorm(X_{hidden}) \]\[X_{hidden} \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} \]
Bert
- elmo+transformer
- 训练的时候会随机遮蔽掉某些单词 mask
