

文章概览:
机器规划和预配置
| 主机/进程 | NN | DN | RM | NM | ZK(QP) | ZKFC | JN |
| nna | √ | √ | √ | √ | |||
| nns | √ | √ | √ | √ | |||
| dn1 | √ | √ | √ | √ | |||
| dn2 | √ | √ | √ | ||||
| dn3 | √ | √ | √ |





export JAVA_HOME=/home/xiaolong/jdk1.8.0_40
export PATH=.:$JAVA_HOME/bin:$PATH
[xiaolong@nna jdk1.8.0_40]$ source /etc/profile
[xiaolong@nna jdk1.8.0_40]$ java -version
java version "1.8.0_40"
Java(TM) SE Runtime Environment (build 1.8.0_40-b26)
Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode)
[xiaolong@nna jdk1.8.0_40]$
⑥ Zookeeper安装
export JAVA_HOME=/home/xiaolong/jdk1.8.0_40 export ZK_HOME=/home/xiaolong/zookeeper-3.4.6 export PATH=.:$JAVA_HOME/bin:$ZK_HOME/bin:$PATH
⑦ 安装Hadoop
export JAVA_HOME=/home/xiaolong/jdk1.8.0_40 export ZK_HOME=/home/xiaolong/zookeeper-3.4.6 export HADOOP_HOME=/home/xiaolong/hadoop-2.6.0 export PATH=.:$JAVA_HOME/bin:$ZK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[xiaolong@nna hadoop-2.6.0]$ source /etc/profile [xiaolong@nna hadoop-2.6.0]$ hadoop version Hadoop 2.6.0 Subversion Unknown -r Unknown Compiled by root on 2014-12-09T11:15Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/xiaolong/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar
集群文件配置
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/xiaolong/zookeeper-3.4.6/data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=192.168.137.101:2888:3888 server.2=192.168.137.102:2888:3888 server.3=192.168.137.103:2888:3888
依据dataDir创建文件夹data,创建文件 myid,值对应server.*中“*”。
echo "1" > myid
echo "2" > myid
echo "3" > myid
vi /home/hadoop/hadoop-2.6.0/etc/hadoop/slavers
dn1
dn2
dn3
vi /home/hadoop/hadoop-2.6.0/etc/hadoop/hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. #export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/home/hadoop/jdk1.8.0_40 # The jsvc implementation to use. Jsvc is required to run secure datanodes # that bind to privileged ports to provide authentication of data transfer # protocol. Jsvc is not required if SASL is configured for authentication of # data transfer protocol using non-privileged ports. #export JSVC_HOME=${JSVC_HOME} export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler. for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do if [ "$HADOOP_CLASSPATH" ]; then export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f else export HADOOP_CLASSPATH=$f fi done # The maximum amount of heap to use, in MB. Default is 1000. #export HADOOP_HEAPSIZE= #export HADOOP_NAMENODE_INIT_HEAPSIZE="" # Extra Java runtime options. Empty by default. export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" # Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS" export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS" export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS" #HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS" # On secure datanodes, user to run the datanode as after dropping privileges. # This **MUST** be uncommented to enable secure HDFS if using privileged ports # to provide authentication of data transfer protocol. This **MUST NOT** be # defined if SASL is configured for authentication of data transfer protocol # using non-privileged ports. export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER} # Where log files are stored. $HADOOP_HOME/logs by default. #export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER # Where log files are stored in the secure data environment. export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER} ### # HDFS Mover specific parameters ### # Specify the JVM options to be used when starting the HDFS Mover. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # export HADOOP_MOVER_OPTS="" ### # Advanced Users Only! ### # The directory where pid files are stored. /tmp by default. # NOTE: this should be set to a directory that can only be written to by # the user that will run the hadoop daemons. Otherwise there is the # potential for a symlink attack. export HADOOP_PID_DIR=${HADOOP_PID_DIR} export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR} # A string representing this instance of hadoop. $USER by default. export HADOOP_IDENT_STRING=$USER
vi /home/hadoop/hadoop-2.6.0/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop-2.6.0/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>nna:2181,nns:2181,dn1:2181</value> </property> </configuration>
vi /home/hadoop/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
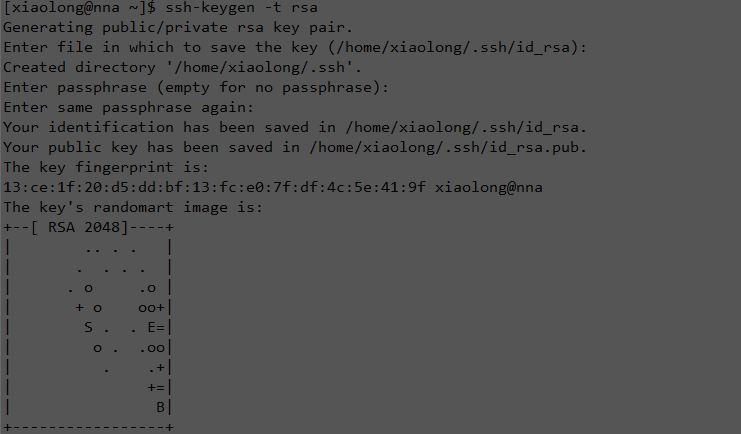
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>nna:9000</value> </property> <property> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>nns:9000</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn1</name> <value>nna:50070</value> </property> <property> <name>dfs.namenode.http-address.ns1.nn2</name> <value>nns:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://nns:8485;dn1:8485;dn2:8485/ns1</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/hadoop-2.6.0/tmp/journal</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>${hadoop.tmp.dir}/dfs/data</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>
vi /home/hadoop/hadoop-2.6.0/etc/hadoop/yarn-site.xml
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value> </property> <!--开启自动恢复功能--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>nna</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>nns</value> </property> <!--不同主机不同配置,只在RM机器配置-->
<property>
<name>yarn.resourcemanager.ha.id</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>nna:2181,nns:2181,dn1:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
vi /home/hadoop/hadoop-2.6.0/etc/hadoop/mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
启动集群
#! /bin/bash # 启动zookeeper集群 echo "启动zookeeper集群" ssh nna "/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start" &> /dev/null ssh nns "/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start" &> /dev/null ssh dn1 "/home/hadoop/zookeeper-3.4.6/bin/zkServer.sh start" &> /dev/null sleep 5s # 对zookeeper集群进行格式化 echo "对zookeeper集群进行格式化" ssh nna "/home/hadoop/hadoop-2.6.0/bin/hdfs zkfc -formatZK" # 启动journalnode元数据共享进程 echo "启动journalnode元数据共享进程" ssh nna "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemons.sh start journalnode" #ssh nns "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemon.sh start journalnode" # 启动故障恢复进程zkfc echo "启动故障恢复进程zkfc" ssh nna "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemon.sh start zkfc" ssh nns "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemon.sh start zkfc" # nna上,格式化NameNode,并开启 echo "nna上,格式化NameNode,并开启" ssh nna "/home/hadoop/hadoop-2.6.0/bin/hdfs namenode -format -clusterid ns1" sleep 10 ssh nna "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemon.sh start namenode" # nns上,同步NameNode,并开启 echo "nns上,同步NameNode,并开启" ssh nns "/home/hadoop/hadoop-2.6.0/bin/hdfs namenode -bootstrapStandby" ssh nns "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemon.sh start namenode" # 启动所有DataNodes echo "启动所有DataNodes" ssh nna "/home/hadoop/hadoop-2.6.0/sbin/hadoop-daemons.sh start datanode" # 启动yarn echo "启动yarn" ssh nna "/home/hadoop/hadoop-2.6.0/sbin/start-yarn.sh" # 在nns上,启动另一个resourcemanager echo "在nns上,启动另一个resourcemanager" ssh nns "/home/hadoop/hadoop-2.6.0/sbin/yarn-daemon.sh start resourcemanager"
HA验证
查看地址:http://192.168.137.101:50070

查看地址:http://192.168.137.102:50070

查看地址:http://192.168.137.101:8088

查看地址:http://192.168.137.102:8088

然后分别杀死Active HDFS和Active RM,可以看到Standby自动切换成Active状态,图示略。
注意事项
<property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/hadoop-2.6.0/tmp/journal</value> </property>
yarn-site.xml中,下面项为可选项,在RM服务器中需配置对应配置项
<property> <name>yarn.resourcemanager.ha.id</name> <value>rm1</value> </property>
在用hadoop-daemons.sh脚本启动zkfc,datanode,journalnode时,默认的加载的主机配置文件为slavers,也可以在slavers所在目录编写自己主机配置文件,执行命令时指定--hosts即可。
小结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号