信息检索 - SDU新闻网站Python全站爬取+索引构建+搜索引擎
信息检索课程设计sdu视点新闻全站Python爬虫爬取+索引构建+搜索引擎查询练习程序(1805)。
以前在gh仓库总结的内容,没想到被人转载不带出处,不如我自己来发一遍叭。
源代码:Github
爬虫功能使用Python的scrapy库实现,并用MongoDB数据库进行存储。
索引构建和搜索功能用Python的Whoosh和jieba库实现。(由于lucene是java库,所以pyLucene库的安装极其麻烦,因此选用Python原生库Whoosh实现,并使用jieba进行中文分词。)
搜索网页界面用django实现,页面模板套用BootCDN。
1 要求
以下是检索的基本要求:可以利用lucene、nutch等开源工具,利用Python、Java等编程语言,但需要分别演示并说明原理。
-
Web网页信息抽取
以山东大学新闻网为起点进行网页的循环爬取,保持爬虫在view.sdu.edu.cn之内(即只爬取这个站点的网页),爬取的网页数量越多越好。 -
索引构建
对上一步爬取到的网页进行结构化预处理,包括基于模板的信息抽取、分字段解析、分词、构建索引等。 -
检索排序
对上一步构建的索引库进行查询,对于给定的查询,给出检索结果,明白排序的原理及方法。
2 运行方式
-
运行
sduspider/run.py来进行网络爬虫,这个过程将持续十多个小时,但可以随时终止,在下次运行时继续。 -
运行
indexbuilder/index_builder.py来对数据库中的72000条数据构建索引,该过程将持续几个小时,但可以随时终止。 -
如果不熟悉Whoosh库的构建索引和query搜索功能,可以参考运行
indexbuilder/sample.py。 -
运行
indexbuilder/query.py来测试搜索功能。 -
运行
searchengine/run_server.py打开搜索网页服务器,在浏览器中打开127.0.0.1:8000进入搜索页面执行搜索。
3 所需python库
- scrapy
- requests
- pymongo
- whoosh
- jieba
- django
4 所需数据库
- MongoDB
- Mongo Management Studio 可视化工具(可选)
5 爬虫特性
爬虫代码位于sduspider/目录下。
5.1 爬取内容
爬虫爬取以 http://www.view.sdu.edu.cn/info/ 打头的所有新闻页面的内容,这些内容包括:
| Item | Item name |
|---|---|
| 标题 | newsTitle |
| 链接 | newsUrl |
| 阅读量 | newsCliek |
| 发布时间 | newsPublishTime |
| 文章内容 | newsContent |
# spider.py
# 爬取当前网页
print('start parse : ' + response.url)
self.destination_list.remove(response.url)
if response.url.startswith("http://www.view.sdu.edu.cn/info/"):
item = NewsItem()
for box in response.xpath('//div[@class="new_show clearfix"]/div[@class="le"]'):
# article title
item['newsTitle'] = box.xpath('.//div[@class="news_tit"]/h3/text()').extract()[0].strip()
# article url
item['newsUrl'] = response.url
item['newsUrlMd5'] = self.md5(response.url)
# article click time
item['newsClick'] = box.xpath('.//div[@class="news_tit"]/p/span/script/text()').extract()[0].strip()
pattern = re.compile(r'\(.*?\)')
parameters = re.search(pattern, item['newsClick']).group(0)
parameters = parameters[1:-1].split(',')
parameters[0] = re.search(re.compile(r'\".*?\"'), parameters[0]).group(0)[1:-1]
parameters[1] = parameters[1].strip()
parameters[2] = parameters[2].strip()
request_url = 'http://www.view.sdu.edu.cn/system/resource/code/news/click/dynclicks.jsp'
request_data = {'clicktype': parameters[0], 'owner': parameters[1], 'clickid': parameters[2]}
request_get = requests.get(request_url, params=request_data)
item['newsClick'] = request_get.text
# article publish time
item['newsPublishTime'] = box.xpath('.//div[@class="news_tit"]/p[not(@style)]/text()').extract()[0].strip()[5:]
# article content
item['newsContent'] = box.xpath('.//div[@class="news_content"]').extract()[0].strip()
regexp = re.compile(r'<[^>]+>', re.S)
item['newsContent'] = regexp.sub('',item['newsContent']) # delete templates <>
# 索引构建flag
item['indexed'] = 'False'
# yield it
yield item
5.2 宽度优先搜索爬取
爬虫基于宽度优先搜索,对http://www.view.sdu.edu.cn/区段的网址进行爬取,并将http://www.view.sdu.edu.cn/info/区段的新闻内容提取出来。
# settings.py
# 先进先出,广度优先
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
5.3 二分法去重
所有已经爬取过的网址都会以MD5特征的形式顺序存储在list中,当获取新的url时,通过二分法查找list中是否存在该url的特征值,以达到去重的目的。
Scrapy库自带了查重去重的功能,但为了保证效率,自行编写了二分法去重,但并未关闭scrapy库自带的去重功能。
# spider.py
# md5 check
md5_url = self.md5(real_url)
if self.binary_md5_url_search(md5_url) > -1: # 二分法查找存在当前MD5
pass
else:
self.binary_md5_url_insert(md5_url) # 二分法插入当前MD5
self.destination_list.append(real_url) # 插入爬虫等待序列
yield scrapy.Request(real_url, callback=self.parse, errback=self.errback_httpbin)
5.4 断点续爬
每爬取一定次数后都会将当前爬虫状态存储在pause文件夹下,重新运行爬虫时会继续上一次保存的断点进行爬取。Scrapy有自带的断点续爬功能(在settings.py中设置),但貌似在Pycharm中行不通。
# spider.py
# counter++,并在合适的时候保存断点
def counter_plus(self):
print('待爬取网址数:' + (str)(len(self.destination_list)))
# 断点续爬功能之保存断点
if self.counter % self.save_frequency == 0: # 爬虫经过save_frequency次爬取后
print('Rayiooo:正在保存爬虫断点....')
f = open('./pause/response.seen', 'wb')
pickle.dump(self.url_md5_seen, f)
f.close()
f = open('./pause/response.dest', 'wb')
pickle.dump(self.destination_list, f)
f.close()
self.counter = self.save_frequency
self.counter += 1 # 计数器+1
5.5 数据存入MongoDB
关系类数据库不适用于爬虫数据存储,因此使用非关系类数据库MongoDB。数据库可以用可视化工具方便查看,例如Mongo Management Studio。
# pipelines.py
class MongoDBPipeline(object):
def __init__(self):
host = settings["MONGODB_HOST"]
port = settings["MONGODB_PORT"]
dbname = settings["MONGODB_DBNAME"]
sheetname = settings["MONGODB_SHEETNAME"]
# 创建MONGODB数据库链接
client = pymongo.MongoClient(host=host, port=port)
# 指定数据库
mydb = client[dbname]
# 存放数据的数据库表名
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
# self.post.insert(data) # 直接插入的方式有可能导致数据重复
# 更新数据库中的数据,如果upsert为Ture,那么当没有找到指定的数据时就直接插入,反之不执行插入
self.post.update({'newsUrlMd5': item['newsUrlMd5']}, data, upsert=True)
return item

6 索引构建特性
索引构建代码位于indexbuilder/目录下。
6.1 断点续构
构建倒排索引的过程比较缓慢,每小时只能构建10000条新闻的索引,因此在索引构建时及时存储新构建的索引,以保证能够断点续构。
6.2 中文分词
Whoosh自带的Analyzer分词仅针对英文文章,而不适用于中文。从jieba库中引用的ChineseAnalyzer保证了能够对Documents进行中文分词。同样,ChineseAnalyzer在search时也能够对中文查询query提取关键字并进行搜索。
# index_builder.py
from jieba.analyse import ChineseAnalyzer
analyzer = ChineseAnalyzer()
# 创建索引模板
schema = Schema(
newsId=ID(stored=True),
newsTitle=TEXT(stored=True, analyzer=analyzer),
newsUrl=ID(stored=True),
newsClick=NUMERIC(stored=True, sortable=True),
newsPublishTime=TEXT(stored=True),
newsContent=TEXT(stored=False, analyzer=analyzer), # 文章内容太长了,不存
)
6.3 Query类提供搜索API
Query类自动执行了从index索引文件夹中取倒排索引来执行搜索,并返回一个结果数组。
# query.py
if __name__ == '__main__':
q = Query()
q.standard_search('软件园校区')
7 搜索引擎特性
搜索引擎代码位于searchengine/目录下。
7.1 Django搭建Web界面
Django适合Web快速开发。result页面继承了main页面,搜索结果可以按照result中的指示显示在页面中。在django模板继承下,改变main.html中的页面布局,result.html的布局也会相应改变而不必使用Ctrl+c、Ctrl+v的方式改变。
# view.py
def search(request):
res = None
if 'q' in request.GET and request.GET['q']:
res = q.standard_search(request.GET['q']) # 获取搜索结果
c = {
'query': request.GET['q'],
'resAmount': len(res),
'results': res,
}
else:
return render_to_response('main.html')
return render_to_response('result.html', c) # 展示搜索结果
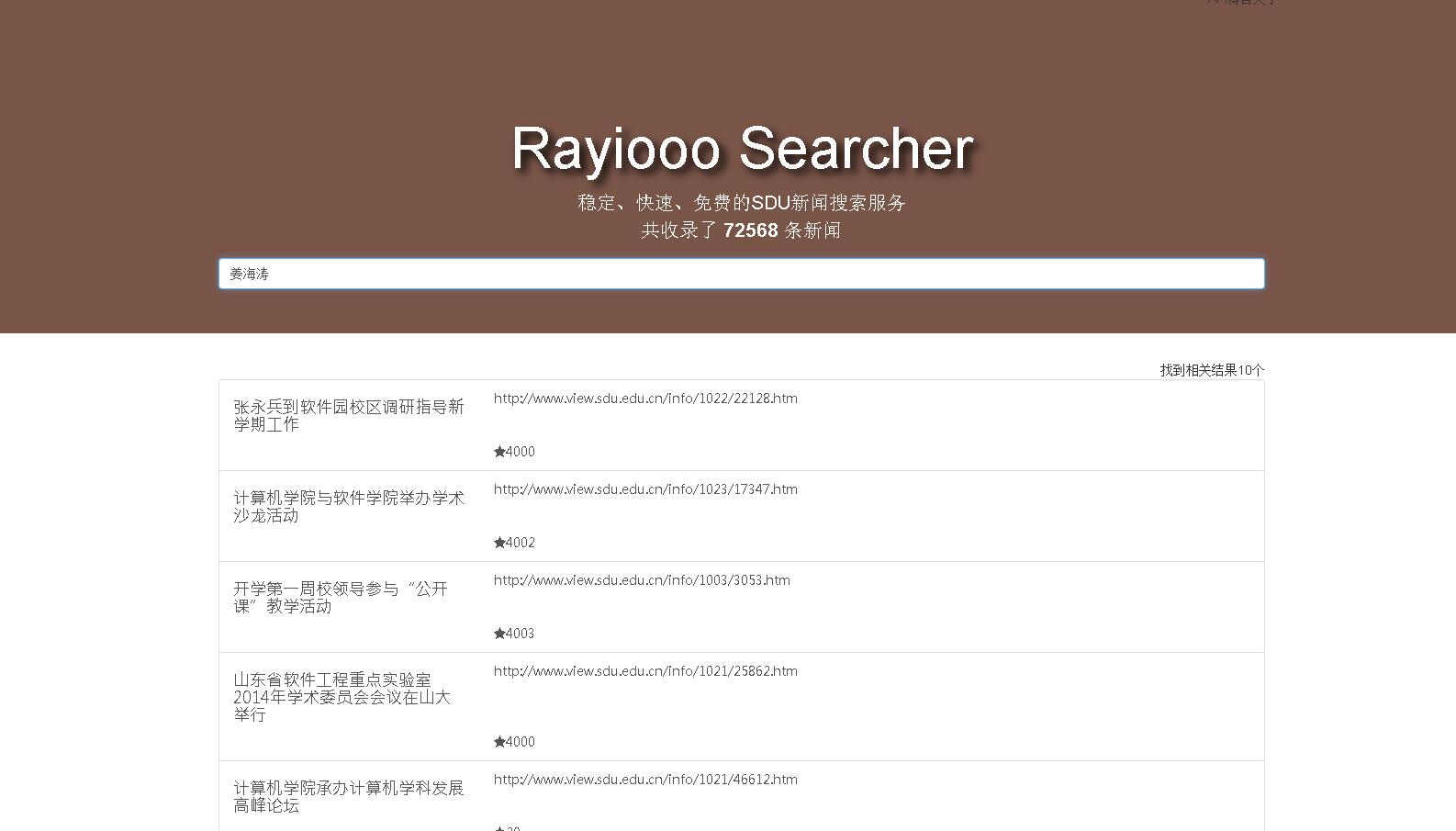
7.2 搜索迅速
第一次搜索时,可能因为倒排索引index的取出时间较长而搜索缓慢,但一旦index取出,对于70000余条新闻的搜索将非常迅速,秒出结果。
参考资料
[1]scrapy爬虫框架入门实例
[2]笔记:scrapy爬取的数据存入MySQL,MongoDB
[3]搜索那些事 - 用Golang写一个搜索引擎(0x00) --- 从零开始(分享自知乎网)
[4]Whoosh + jieba 中文检索
[5]利用whoosh对mongoDB的中文文档建立全文检索
[6]Django 创建第一个项目
[7]Django模板系统(非常详细)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号