数据挖掘 - 用户问答精准邀请挖掘
Data Mining Project Report
摘要
每天都有数以十万计的新问题以及 UGC 内容产生在知乎网站,如何高效的将这些用户新提出的问题邀请其他用户进行解答,以及挖掘用户有能力且感兴趣的问题进行邀请下发,优化邀请回答的准确率,提高问题解答率以及回答生产数,是亟待解决的一个问题。智源-看山杯专家发现算法大赛2019是解决该问题的竞赛,旨在精准邀请用户来提供优质回答。我在此竞赛中尽可能多地挖掘了用户、问题的信息以及用户和问题之间的关联信息,选择了具有弱分类效果的决策树作为学习模型,达到了较好的学习效果,能够比较精准地预测用户有意愿接受回答邀请的概率。
1 Introduction
本次比赛是 智源 2019 人工智能大赛 的任务之一。
知识分享服务已经成为目前全球互联网的重要、最受欢迎的应用类型之一。在知识分享或问答社区中,问题数远远超过有质量的回复数。因此,如何连接知识、专家和用户,增加专家的回答意愿,成为了此类服务的中心课题。
知乎是中文互联网知名的综合性社区平台,是一个拥有 2.2 亿用户,每天有数以十万计的新问题以及 UGC 内容产生的网站。其中,如何高效的将这些用户新提出的问题邀请其他用户进行解答,以及挖掘用户有能力且感兴趣的问题进行邀请下发,优化邀请回答的准确率,提高问题解答率以及回答生产数,成为知乎最重要的课题之一。
比赛提供了知乎的问题信息、用户画像、用户回答记录,以及用户接受邀请的记录,要求参加者预测这个用户是否会接受某个新问题的邀请。比赛使用 AUC 对参赛者提交的数据与真实数据进行衡量评估。
2 Overview
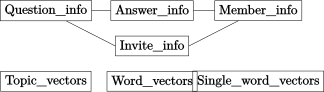
比赛给出的数据集包含邀请信息、用户信息、问题信息、回答信息,以及主题、分词、单字的64维向量数据,如上图,需要输出的值就是用户对于某回答邀请,其接受邀请的概率。由于本人对词向量等信息的处理与挖掘不太熟悉,因此排除掉了主题、分词、单字的向量数据,仅从其他信息中寻找有用信息进行挖掘。
根据邀请信息,我们可以绘制出图所示的关系图:每一条邀请包含一个被邀请用户和他所需要回答的一个问题,用户有一些历史回答,该问题下也有一些已有的回答。根据该关系图,尽可能多地寻找出图中的有用信息就是我们要做的事情。因此,我从该邀请较合适、该用户喜欢回答问题、该问题足够吸引人回答、该用户与该问题的契合度很高这四个大方向,对数据进行了挖掘。

经过挖掘的多维数据,可通过常用的决策树分类器进行训练学习,最终达到精准预测用户接受回答概率的目的。
3 The Proposed Method
3.1 🏃 Invite Feature Mining
训练集的邀请数据(invite_info)中包含4维数据:问题ID、用户ID、邀请创建时间、是否回答。其中“是否回答”项用作数据集的标签,其余三个维度都是值得挖掘的项。
不同用户以及不同问题都有着个体之间的差异性,因此问题ID和用户ID都可以作为分类的特征。邀请在周几、几点发出,都会影响用户回答的欲望,因此邀请小时数、邀请星期数可以作为有区分度的特征。另外,被邀请人被邀请次数和该问题发出邀请的次数也都是有用特征。
综上,邀请信息中,选出问题ID编码、用户ID编码、邀请小时数、邀请星期数、被邀请人出现重复度、被邀请问题出现重复度这6维数据。
3.2 🤡 User Feature Mining
每个邀请对应的用户均有其个性特征,在用户特征表(member_info)中可以得到这些特征。因此,选用该邀请对应的用户的性别、访问频率、二分类特征A-E、多分类特征A-E、盐值分数作为重要特征,其中存在较多的离散的、非数值的数据,我们将其转换成整数型数据。另外,每个人的性别、访问频率、多分类特征在所有用户中出现的重复度也值得挖掘。
综上,在用户信息中选取出以上提到的20维数据进行利用。
3.3 🙋 Question's Answers Feature Mining
每个邀请对应的问题下有许多的回答,这些回答的数量、点赞数等特征都从某一方面反应了问题的火爆程度以及该问题的吸引力程度,因此,从回答信息表(answer_info)中找出该问题下所属的回答,进行一些数据的挖掘是必要的。这些数据包括:问题回答距离提问的天数、问题的优秀、推荐、加入圆桌、有图片、有视频、字数、点赞、取赞、评论、收藏、感谢、举报、没有帮助、反对、邀请数,以上各数据的计数、最大值、最小值、均值、标准差、加和值这6维计算数据,再加上问题的回答数。
从以上的挖掘中,我们选取出了97维数据。
3.4 🙋♂ User's Answers Feature Mining
每个被邀请的用户有许多历史回答,这些历史回答的数据也可以代表该用户对回答问题的热衷程度。同上一个特征挖掘一样,由用户的历史回答,同样可以挖掘出97维数据。
3.5 👯 Question - User Relationship Mining
用户历史上回答过的问题,也从侧面反映出了该用户对当前问题的感兴趣程度。试想,如果用户曾经回答的问题与当前问题有一定相似度,则他应该有更大概率接受这次回答邀请。
将该用户历史回答过的问题列举出来,把这些问题与当前邀请问题的主题、标题分词、问题描述分词进行对比,可以挖掘这三种属性下两问题的以下数据:
a. 两者交集集合的项数
b. a占当前问题该属性的比例
c. a占历史问题该属性的比例
d. a中项在历史问题该属性中出现总次数
e. d占历史问题该属性的比例
综上,可挖掘出3个属性各5维对比特征,总计15维特征。
3.6 Model
经过以上特征挖掘,总共得到了235维度的数值特征,这些特征各自都具有一些弱分类能力,因此选用 python 的 LightGBM 库中的决策树分类器(LightGBMClassifier)作为学习模型,该模型能够对一些弱分类特征进行集成,形成性能较强的分类器。
4 Experiments
4.1 🕧 Parameters Optimization
对模型的每项参数都使用交叉验证进行调参比较费时费力,因此我选用了 hyperopt 包进行自动化调参。
首先应该确定,有哪些参数需要进行调整。LightGBM分类器中,有以下几项常用参数:max_depth, num_leaves, min_child_samples, min_child_weight, feature_fraction, reg_alpha, reg_lambda。
在这里,我们给定以下固定参数的取值:boosting_type='dart', learning_rate=0.5, n_estimators=200。
hyperopt 自动化调参工具需要指定一个 loss 函数作为最小化的目标函数,我们给定该 loss 函数:
最小化该函数,就是最大化交叉验证的最终验证准确率。
经过 6 轮不断缩小范围的调参,得到了表所示参数优化过程表。
| Param Name | Epoch 1 | Epoch 2 | Epoch 3 | Epoch 4 | Epoch 5 | Final |
|---|---|---|---|---|---|---|
| max_depth | 20 | 24 | 22 | 20 | 20 | 20 |
| num_leaves | 200 | 200 | 180 | 180 | 190 | 190 |
| min_child_samples | 220 | 160 | 220 | 210 | 210 | 210 |
| min_child_weight | 0.056 | 0.045 | 0.045 | 0.055 | 0.055 | 0.055 |
| feature_fraction | 0.7 | 0.7 | 0.65 | 0.6 | 0.6 | 0.7 |
| reg_alpha | 0.001 | 0.029 | 0.001 | 0.009 | 0.005 | 0.005 |
| reg_lambda | 13.5 | 15.5 | 15. | 16 | 18 | 21 |
| loss | 0.16209 | 0.16205 | 0.16217 | 0.16195 | 0.16196 | 0.16187 |
我们可以对比使用了优化后的参数的学习器与未使用这些参数的优化器在训练过程中的准确率差异。取经过200轮训练的交叉验证准确率数据,可绘制下图所示折线图。由折线图可得知,使用调参后的参数比不使用参数有了明显的提升效果。

4.2 🀄️ Result
日常验证提交结果和最终验证提交结果分别如表所示。
| Result | Rank | Score |
|---|---|---|
| Test | 115 | 0.80985 |
| Final Validation | 79 | 0.81110 |
5 Conclusion
本次比赛解决了在知识分享和问答社区进行精准邀请的问题,使得更高精准度的邀请投放成为可能。在该工作中,尽可能多地从已知的数据中挖掘出有用数据并进行利用是提升投放精准度的关键点,再配合模型参数的调整,最终达到了以较高精准度发送问答邀请的结果。
本次比赛的代码已托管在 https://github.com/rayiooo/python_datamining_rayiooo。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号