重新认识mapreduce
写这篇文章,是因为最近遇到了mapreduce的二次排序问题。以前的理解不完全正确。首先看一下mapreduce的过程

相信这张图熟悉MR的人都应该见过,再来一张图

wordcount也不细说了,hadoop里面的hello,world
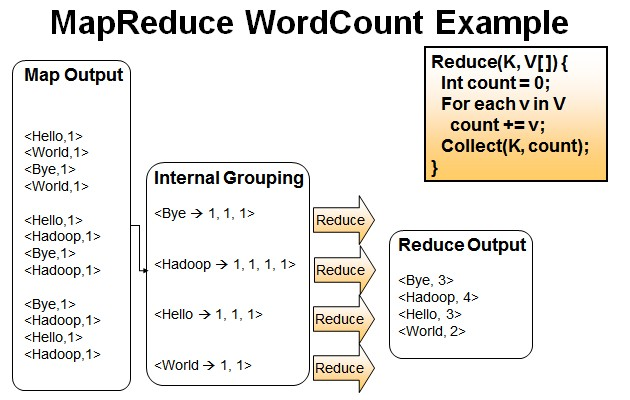
之前我的理解是map过来的<k,v>会形成(k,<v1,v2,v3...>)的格式,并且按照这种思路写出来不少的mapreduce程序,而且没有错。
后来自定义Writable对象,封装一组值作为key,也没有什么问题,而且一直认为key只要在compareTo中重写 了方法就万事大吉,而且compareTo返回0的会作为相同的key。误区就在这里,之前一直认为key相同的value会合并到一个"list"中-。这句话就有错,key是key,value是value,根本不会将key对应的value合并在一起,真实情况是默认将key相同(compareTo返回0的)的合并成了一组,在组相同的里面去foreach里面的value,如果是自定义key的话你可以将key打印一下,或发现key并不相同。
上代码:
public class Entry implements WritableComparable<Entry> { private String yearMonth; private int count; public Entry() { } @Override public int compareTo(Entry entry) { int result = this.yearMonth.compareTo(entry.getYearMonth()); if (result == 0) { result = Integer.compare(count, entry.getCount()); } return result; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(yearMonth); dataOutput.writeInt(count); } @Override public void readFields(DataInput dataInput) throws IOException { this.yearMonth = dataInput.readUTF(); this.count = dataInput.readInt(); } public String getYearMonth() { return yearMonth; } public void setYearMonth(String yearMonth) { this.yearMonth = yearMonth; } public int getCount() { return count; } public void setCount(int count) { this.count = count; } @Override public String toString() { return yearMonth; } }
自定义分区 EntryPartitioner.java
public class EntryPartitioner extends Partitioner<Entry, Text> { @Override public int getPartition(Entry entry, Text paramVALUE, int numberPartitions) { return Math.abs((entry.getYearMonth().hashCode() % numberPartitions)); } }
自定义分组
public class EntryGroupingComparator extends WritableComparator { public EntryGroupingComparator() { super(Entry.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { Entry a1 = (Entry) a; Entry b1 = (Entry) b; return a1.getYearMonth().compareTo(b1.getYearMonth()); } }
mapper类
public class SecondarySortMapper extends Mapper<LongWritable, Text, Entry, Text> { private Entry entry = new Entry(); private Text value = new Text(); @Override protected void map(LongWritable key, Text lines, Context context) throws IOException, InterruptedException { String line = lines.toString(); String[] tokens = line.split(","); String yearMonth = tokens[0] + "-" + tokens[1]; int count = Integer.parseInt(tokens[2]); entry.setYearMonth(yearMonth); entry.setCount(count); value.set(tokens[2]); context.write(entry, value); } }
reducer类
public class SecondarySortReducer extends Reducer<Entry, Text, Entry, Text> { @Override protected void reduce(Entry key, Iterable<Text> values, Context context) throws IOException, InterruptedException { System.out.println("-----------------华丽的分割线-----------------"); StringBuilder builder = new StringBuilder(); for (Text value : values) { System.out.println(key+"==>"+value); builder.append(value.toString()); builder.append(","); } context.write(key, new Text(builder.toString())); } }
reducer中打印出来的跟原来想的不一样,一组的值除了自定义分组的属性相同外,其他的属性有不同的。看来以前是自己理解不够深入啊,特此写出,以示警戒

 浙公网安备 33010602011771号
浙公网安备 33010602011771号