


ICTCLAS分词系统简介2
在所有内容中,词典库的读取是最基本的功能。ICTCLAS中词典存放在Data目录中,常用的词典包括coreDict.dct(词典库)、BigramDict.dct(词与词间的关联库)、nr.dct(人名库)、ns.dct(地名库)、tr.dct(翻译人名库),它们的文件格式是完全相同的,都使用CDictionary类进行解析。如果想深入了解ICTCLAS词典结构,可以参考sinboy的《ICTCLAS分词系统研究(二)--词典结构》一文,详细介绍了词典结构。我这里只给出SharpICTCLAS中的实现。
首先是对基本元素的定义。在SharpICTCLAS中,对原有命名进行了部分调整,使得更具有实际意义并适合C#的习惯。代码如下:

using System.Collections.Generic;
using System.Text;
namespace SharpICTCLAS
{
//==================================================
// Original predefined in DynamicArray.h file
//==================================================
public class ArrayChainItem
{
public int col, row;//row and column
public double value;//The value of the array
public int nPOS;
public int nWordLen;
public string sWord;
//The possible POS of the word related to the segmentation graph
public ArrayChainItem next;
}
public class WordResult
{
//The word
public string sWord;
//the POS of the word
public int nPOS;
//The -log(frequency/MAX)
public double dValue;
}
//--------------------------------------------------
// data structure for word item
//--------------------------------------------------
public class WordItem
{
public int nWordLen;
//The word
public string sWord;
//the process or information handle of the word
public int nPOS;
//The count which it appear
public int nFrequency;
}
//--------------------------------------------------
//data structure for dictionary index table item
//--------------------------------------------------
public class IndexTableItem
{
//The count number of words which initial letter is sInit
public int nCount;
//The head of word items
public WordItem[] WordItems;
}
//--------------------------------------------------
//data structure for word item chain
//--------------------------------------------------
public class WordChain
{
public WordItem data;
public WordChain next;
}
//--------------------------------------------------
//data structure for dictionary index table item
//--------------------------------------------------
public class ModifyTableItem
{
//The count number of words which initial letter is sInit
public int nCount;
//The number of deleted items in the index table
public int nDelete;
//The head of word items
public WordChain pWordItemHead;
}
}
其中ModifyTableItem用于组成ModifyTable,但在实际分词时,词库往往处于“只读”状态,因此用于修改词库的ModifyTable实际上起的作用并不大。因此在后面我将ModifyTable的代码暂时省略。
有了基本元素的定义后,就该定义“词典”类了。原有C++代码中所有类名均以大写的“C”打头,词典类名为CDictionary,在SharpICTCLAS中,我去掉了开头的“C”,并且为了防止和系统的Dictionary类重名,特起名为“WordDictionary”类。该类主要负责完成词典库的读、写以及检索操作。让我们看看如何读取词典库:
{
public bool bReleased = true;
public IndexTableItem[] indexTable;
public ModifyTableItem[] modifyTable;
public bool Load(string sFilename)
{
return Load(sFilename, false);
}
public bool Load(string sFilename, bool bReset)
{
int frequency, wordLength, pos; //频率、词长、读取词性
bool isSuccess = true;
FileStream fileStream = null;
BinaryReader binReader = null;
try
{
fileStream = new FileStream(sFilename, FileMode.Open, FileAccess.Read);
if (fileStream == null)
return false;
binReader = new BinaryReader(fileStream, Encoding.GetEncoding("gb2312"));
indexTable = new IndexTableItem[Predefine.CC_NUM];
bReleased = false;
for (int i = 0; i < Predefine.CC_NUM; i++)
{
//读取以该汉字打头的词有多少个
indexTable[i] = new IndexTableItem();
indexTable[i].nCount = binReader.ReadInt32();
if (indexTable[i].nCount <= 0)
continue;
indexTable[i].WordItems = new WordItem[indexTable[i].nCount];
for (int j = 0; j < indexTable[i].nCount; j++)
{
indexTable[i].WordItems[j] = new WordItem();
frequency = binReader.ReadInt32(); //读取频率
wordLength = binReader.ReadInt32(); //读取词长
pos = binReader.ReadInt32(); //读取词性
if (wordLength > 0)
indexTable[i].WordItems[j].sWord = Utility.ByteArray2String(binReader.ReadBytes(wordLength));
else
indexTable[i].WordItems[j].sWord = "";
//Reset the frequency
if (bReset)
indexTable[i].WordItems[j].nFrequency = 0;
else
indexTable[i].WordItems[j].nFrequency = frequency;
indexTable[i].WordItems[j].nWordLen = wordLength;
indexTable[i].WordItems[j].nPOS = pos;
}
}
}
catch (Exception e)
{
Console.WriteLine(e.Message);
isSuccess = false;
}
finally
{
if (binReader != null)
binReader.Close();
if (fileStream != null)
fileStream.Close();
}
return isSuccess;
}
//......
}
下面内容节选自词库中CCID为2、3、4、5的单元, CCID的取值范围自1~6768,对应6768个汉字,所有与该汉字可以组成的词均记录在相应的单元内。词库中记录的词是没有首汉字的(我用带括号的字补上了),其首汉字就是该单元对应的汉字。词库中记录了词的词长、频率、词性以及词。
另外特别需要注意的是在一个单元内,词是按照CCID大小排序的!这对我们后面的分析至关重要。
词长 频率 词性 词
0 128 h (埃)
0 0 j (埃)
2 4 n (埃)镑
2 28 ns (埃)镑
4 4 n (埃)菲尔
2 511 ns (埃)及
4 4 ns (埃)克森
6 2 ns (埃)拉特湾
4 4 nr (埃)里温
6 2 nz (埃)默鲁市
2 27 n (埃)塞
8 64 ns (埃)塞俄比亚
22 2 ns (埃)塞俄比亚联邦民主共和国
4 3 ns (埃)塞萨
4 4 ns (埃)舍德
6 2 nr (埃)斯特角
4 2 ns (埃)松省
4 3 nr (埃)特纳
6 2 nz (埃)因霍温
====================================
汉字:挨, ID :3
词长 频率 词性 词
0 56 h (挨)
2 1 j (挨)次
2 19 n (挨)打
2 3 ns (挨)冻
2 1 n (挨)斗
2 9 ns (挨)饿
2 4 ns (挨)个
4 2 ns (挨)个儿
6 17 nr (挨)家挨户
2 1 nz (挨)近
2 0 n (挨)骂
6 1 ns (挨)门挨户
2 1 ns (挨)批
2 0 ns (挨)整
2 12 ns (挨)着
2 0 nr (挨)揍
====================================
汉字:哎, ID :4
词长 频率 词性 词
0 10 h (哎)
2 3 j (哎)呀
2 2 n (哎)哟
====================================
汉字:唉, ID :5
词长 频率 词性 词
0 9 h (唉)
6 4 j (唉)声叹气
在这里还应当注意的是,一个词可能有多个词性,因此一个词可能在词典中出现多次,但词性不同。若想从词典中唯一定位一个词的话,必须同时指明词与词性。
另外在WordDictionary类中用到得比较多的就是词的检索,这由FindInOriginalTable方法实现。原ICTCLAS代码中该方法的实现结构比较复杂,同时考虑了多种检索需求,因此代码也相对复杂一些。在SharpICTCLAS中,我对该方法进行了重载,针对不同检索目的设计了不同的FindInOriginalTable方法,简化了程序接口和代码复杂度。其中一个FindInOriginalTable方法代码如下,实现了判断某一词性的一词是否存在功能。
{
WordItem[] pItems = indexTable[nInnerCode].WordItems;
int nStart = 0, nEnd = indexTable[nInnerCode].nCount - 1;
int nMid = (nStart + nEnd) / 2, nCmpValue;
//Binary search
while (nStart <= nEnd)
{
nCmpValue = Utility.CCStringCompare(pItems[nMid].sWord, sWord);
if (nCmpValue == 0 && (pItems[nMid].nPOS == nPOS || nPOS == -1))
return true;//find it
else if (nCmpValue < 0 || (nCmpValue == 0 && pItems[nMid].nPOS < nPOS && nPOS != -1))
nStart = nMid + 1;
else if (nCmpValue > 0 || (nCmpValue == 0 && pItems[nMid].nPOS > nPOS && nPOS != -1))
nEnd = nMid - 1;
nMid = (nStart + nEnd) / 2;
}
return false;
}
其它功能在这里就不再介绍了。
- 小结
1、WordDictionary类实现了对字典的读取、写入、更改、检索等功能。
2、词典中记录了以6768个汉字打头的词、词性、出现频率的信息,具体结构需要了解。
ICTCLAS初步分词包括:1)原子切分;2)找出原子之间所有可能的组词方案;3)N-最短路径中文词语粗分三步。
例如:“他说的确实在理”这句话。
1)原子切分的目的是完成单个汉字的切分。经过原子切分后变成“始##始/他/说/的/确/实/在/理/末##末”。
2)然后根据“词库字典”找出所有原子之间所有可能的组词方案。经过词库检索后,该句话变为“始##始/他/说/的/的确/确/确实/实/实在/在/在理/末##末”。
3)N-最短路径中文词语粗分。下面的过程就比较复杂了,首先我们要找出这些词之间所有可能的两两组合的距离(这需要检索BigramDict.dct词典库)。对于上面的案例而言,得到的BiGraph结果如下:
row: 1, col: 2, eWeight: 2.25, nPOS: 0, sWord:他@说
row: 2, col: 3, eWeight: 4.05, nPOS: 0, sWord:说@的
row: 2, col: 4, eWeight: 7.11, nPOS: 0, sWord:说@的确
row: 3, col: 5, eWeight: 4.10, nPOS: 0, sWord:的@确
row: 3, col: 6, eWeight: 4.10, nPOS: 0, sWord:的@确实
row: 4, col: 7, eWeight: 11.49, nPOS: 25600, sWord:的确@实
row: 5, col: 7, eWeight: 11.63, nPOS: 0, sWord:确@实
row: 4, col: 8, eWeight: 11.49, nPOS: 25600, sWord:的确@实在
row: 5, col: 8, eWeight: 11.63, nPOS: 0, sWord:确@实在
row: 6, col: 9, eWeight: 3.92, nPOS: 0, sWord:确实@在
row: 7, col: 9, eWeight: 10.98, nPOS: 0, sWord:实@在
row: 6, col: 10, eWeight: 10.97, nPOS: 0, sWord:确实@在理
row: 7, col: 10, eWeight: 10.98, nPOS: 0, sWord:实@在理
row: 8, col: 11, eWeight: 11.17, nPOS: 0, sWord:实在@理
row: 9, col: 11, eWeight: 5.62, nPOS: 0, sWord:在@理
row: 10, col: 12, eWeight: 14.30, nPOS: 24832, sWord:在理@末##末
row: 11, col: 12, eWeight: 11.95, nPOS: 0, sWord:理@末##末
可以从上表中可以看出“的@确实”的距离为4.10,而“的确@实”间的距离为11.49,这说明“的@确实”的组合可能性要大一些。不过这只是一面之词,究竟如何组词需要放到整句话的环境下通盘考虑,达到整体最优。这就是N最短路径需要完成的工作。
在求最短路径前我们需要将上表换一个角度观察,其实上表可以等价的表述成如下图所示的“有向图”:
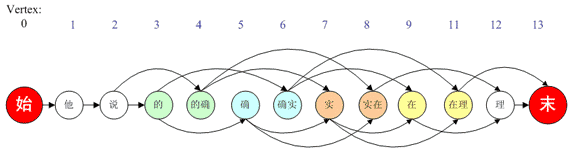
上表中词与词的组合(例如“的@确实”)在该图中对应一条边(由节点“的”到节点“确实”),其路径长度就是上表中的eWeight值。这样一来,求最优分词方案就成了求整体最短路径。
由于是初次切分,为了提高后续优化质量,这里求的是N最短路径,即路径长度由小到大排序后的前N种长度的所有路径。对于上面案例,我们假设N=2,那么求解得到的路径有2条(注意也可能比两条多,关于这点我 将在后续专门介绍NShortPath时再说):
路径(1):
0, 1, 2, 3, 6, 9, 11, 12, 13
始##始 / 他 / 说 / 的 / 确实 / 在 / 理 / 末##末
路径(2):
0, 1, 2, 3, 6, 10, 12, 13
始##始 / 他 / 说 / 的 / 确实 / 在理 / 末##末
如果要想真正搞清楚上述过程,必须对下面的数据结构以及它的几种不同的表述方式有个透彻的了解。
- DynamicArray
DynamicArray是什么?其实它的本质是一个经过排序的链表。为了表达的更明白些,我们不妨看下面这张图:

(图一)
上面这张图是一个按照index值进行了排序的链表,当插入新结点时必须确保index值的有序性。DynamicArray类完成的功能基本上与上面这个链表差不多,只是排序规则不是index,而是row和col两个数据,如下图:

(图二)
大家可以看到,这个有序链表的排序规则是先按row排序,row相同的按照col排序。当然排序规则是可以改变的,如果先按col排,再按row排,则上面的链表必须表述成:

(图三)
原有ICTCLAS实现时,在一个类里面综合考虑了row先排序和col先排序的两种情况,这在SharpICTCLAS中做了很大调整,将DynamicArray类作为父类提供一些基础操作,同时设计了RowFirstDynamicArray和ColumnFirstDynamicArray类作为子类提供专门的方法,这使得代码变得清晰多了(有关DynamicArray的实现我在下一篇文章中再做介绍)。
在本文最前面给出的案例中,根据“词库字典”找出所有原子字间的组词方案,其结果为“始##始/他/说/的/的确/确/确实/实/实在/在/在理/末##末”,而内容就是靠一个RowFirstDynamicArray存储的,如下:
row: 1, col: 2, eWeight: 19823.00, nPOS: 0, sWord:他
row: 2, col: 3, eWeight: 17649.00, nPOS: 0, sWord:说
row: 3, col: 4, eWeight: 358156.00, nPOS: 0, sWord:的
row: 3, col: 5, eWeight: 210.00, nPOS: 25600, sWord:的确
row: 4, col: 5, eWeight: 181.00, nPOS: 0, sWord:确
row: 4, col: 6, eWeight: 361.00, nPOS: 0, sWord:确实
row: 5, col: 6, eWeight: 357.00, nPOS: 0, sWord:实
row: 5, col: 7, eWeight: 295.00, nPOS: 0, sWord:实在
row: 6, col: 7, eWeight: 78484.00, nPOS: 0, sWord:在
row: 6, col: 8, eWeight: 3.00, nPOS: 24832, sWord:在理
row: 7, col: 8, eWeight: 129.00, nPOS: 0, sWord:理
row: 8, col: 9, eWeight:2079997.00, nPOS: 4, sWord:末##末
- DynamicArray的二维图表表示
如果根据RowFirstDynamicArray中row和col的坐标信息将DynamicArray放到一个二维表格中的话,我们就得到了DynamicArray的二维图表表示。如下图所示:

(图四)
在这张图中,行和列有一个非常有意思的关系:col为 n 的列中所有词可以与row为 n 的所有行中的词进行组合。例如“的确”这个词,它的col = 5,需要和它计算平滑值的有两个,分别是row = 5的两个词:“实”和“实在”。
如果将所有行与列之间词与词之间的关系找到,我们就可以得到另外一个ColumnFirstDynamicArray,如本文第一张表中内容所示。将该ColumnFirstDynamicArray的内容放到另外一个二维表中就得到如下图所示内容:
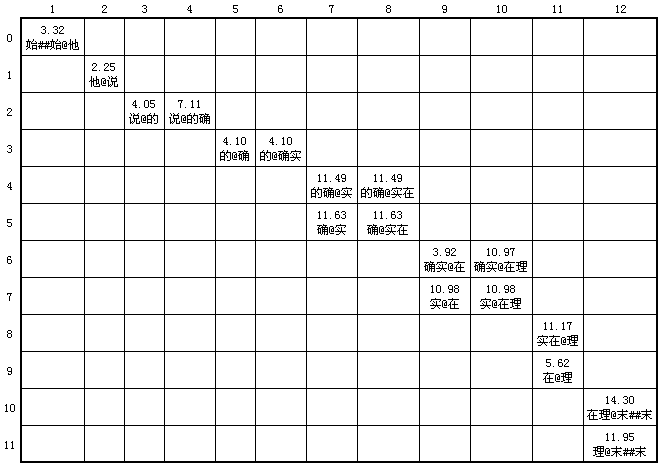
(图五)
- ColumnFirstDynamicArray的有向图表示
上面这张表可以和一张有向图所对应,就如前文所说,词与词的组合(例如“的@确实”)在该图中对应一条边(由节点“的”到节点“确实”),其路径长度就是上表中的eWeight值,如下图所示:
剩下的事情就是针对该图求解N最短路径了,这将在后续文章中介绍。
- 小结
ICTCLAS的初步分词是一个比较复杂的过程,涉及的数据结构、数据表示以及相关算法都颇有难度。在SharpICTCLAS中,对原有C++代码做了比较多的更改,重新设计了DynamicArray类与NShortPath方法,在牺牲有限性能的同时力争大幅度简化代码的复杂度,提高可读性。
有关SharpICTCLAS中DynamicArray类的实现以及在代码可读性与性能之间的权衡将在下一篇文章中加以介绍。
从前文可以看出,ICTCLAS中DynamicArray类在初步分词过程中起到了至关重要的所用,而ICTCLAS中DynamicArray类的实现比较复杂,可以说是包罗万象,在一个GetElement方法就综合考虑了1)row优先排序的链表;2)col优先排序的链表;3)当nRow为-1时的行为;4)当nCol为-1时的行为;5)当nRow与nCol都不为-1时的行为 (可以参考本人的《天书般的ICTCLAS分词系统代码(一)》一文)。
为了简化编程接口,并将纠缠不清的代码逻辑剥离开来,我重新设计了DynamicArray类,利用三个类实现原有一个类的功能。具体改造包括:1) 将DynamicArray类做成一个抽象父类,实现一些公共功能;2)设计了RowFirstDynamicArray类与ColumnFirstDynaimcArray类作为DynamicArray的子类,分别实现row优先排序和col优先排序的DynamicArray。2) 在牺牲有限性能的同时力争大幅度简化代码的复杂度,提高可读性。
具体实现如下:
1、DynamicArray链表结点的定义
为了使得DynamicArray更具有通用性,使用了范型方式定义了链表的结点,代码如下:
{
public int row;
public int col;
public T Content;
public ChainItem<T> next;
}
2、DynamicArray类
DynamicArray类是一个抽象类,主要为RowFirstDynamicArray类与ColumnFirstDynaimcArray类提供公共的基础功能,例如查找行、列值为nRow, nCol的结点等。同时,该类将插入一新结点的方法设计成抽象方法,需要具体类根据row优先排序还是col优先排序自行决定具体实现。DynamicArray类的代码实现如下(应当说非常简单):
{
protected ChainItem<T> pHead; //The head pointer of array chain
public int ColumnCount, RowCount; //The row and col of the array
public DynamicArray()
{
pHead = null;
RowCount = 0;
ColumnCount = 0;
}
public int ItemCount
{
get
{
ChainItem<T> pCur = pHead;
int nCount = 0;
while (pCur != null)
{
nCount++;
pCur = pCur.next;
}
return nCount;
}
}
//====================================================================
// 查找行、列值为nRow, nCol的结点
//====================================================================
public ChainItem<T> GetElement(int nRow, int nCol)
{
ChainItem<T> pCur = pHead;
while (pCur != null && !(pCur.col == nCol && pCur.row == nRow))
pCur = pCur.next;
return pCur;
}
//====================================================================
// 设置或插入一个新的结点
//====================================================================
public abstract void SetElement(int nRow, int nCol, T content);
//====================================================================
// Return the head element of ArrayChain
//====================================================================
public ChainItem<T> GetHead()
{
return pHead;
}
//====================================================================
//Get the tail Element buffer and return the count of elements
//====================================================================
public int GetTail(out ChainItem<T> pTailRet)
{
ChainItem<T> pCur = pHead, pPrev = null;
int nCount = 0;
while (pCur != null)
{
nCount++;
pPrev = pCur;
pCur = pCur.next;
}
pTailRet = pPrev;
return nCount;
}
//====================================================================
// Set Empty
//====================================================================
public void SetEmpty()
{
pHead = null;
ColumnCount = 0;
RowCount = 0;
}
public override string ToString()
{
StringBuilder sb = new StringBuilder();
ChainItem<T> pCur = pHead;
while (pCur != null)
{
sb.Append(string.Format("row:{0,3}, col:{1,3}, ", pCur.row, pCur.col));
sb.Append(pCur.Content.ToString());
sb.Append("\r\n");
pCur = pCur.next;
}
return sb.ToString();
}
}
3、RowFirstDynamicArray类的实现
RowFirstDynamicArray类主要实现了row优先排序的DynamicArray,里面包含了两个方法:GetFirstElementOfRow(获取row为nRow的第一个元素)和SetElement方法。其中GetFirstElementOfRow有两个重载版本。
这等价于将原有ICTCLAS中GetElement方法拆分成了三个方法,如果算上重载版本的话共五个方法,它们分别是:1)获取行、列值为nRow, nCol的结点,此方法由DynamicArray类实现;2)对于Row优先排序的链表而言,单独提供了GetFirstElementOfRow方法。3)对于Column优先排序的链表而言,单独提供了GetFirstElementOfColumn方法。
RowFirstDynamicArray类的实现如下:
{
//====================================================================
// 查找行为 nRow 的第一个结点
//====================================================================
public ChainItem<T> GetFirstElementOfRow(int nRow)
{
ChainItem<T> pCur = pHead;
while (pCur != null && pCur.row != nRow)
pCur = pCur.next;
return pCur;
}
//====================================================================
// 从 startFrom 处向后查找行为 nRow 的第一个结点
//====================================================================
public ChainItem<T> GetFirstElementOfRow(int nRow, ChainItem<T> startFrom)
{
ChainItem<T> pCur = startFrom;
while (pCur != null && pCur.row != nRow)
pCur = pCur.next;
return pCur;
}
//====================================================================
// 设置或插入一个新的结点
//====================================================================
public override void SetElement(int nRow, int nCol, T content)
{
ChainItem<T> pCur = pHead, pPre = null, pNew; //The pointer of array chain
if (nRow > RowCount)//Set the array row
RowCount = nRow;
if (nCol > ColumnCount)//Set the array col
ColumnCount = nCol;
while (pCur != null && (pCur.row < nRow || (pCur.row == nRow && pCur.col < nCol)))
{
pPre = pCur;
pCur = pCur.next;
}
if (pCur != null && pCur.row == nRow && pCur.col == nCol)//Find the same position
pCur.Content = content;//Set the value
else
{
pNew = new ChainItem<T>();//malloc a new node
pNew.col = nCol;
pNew.row = nRow;
pNew.Content = content;
pNew.next = pCur;
if (pPre == null)//link pNew after the pPre
pHead = pNew;
else
pPre.next = pNew;
}
}
}
有关ColumnFirstDynamicArray类的实现大同小异,这里就不再提供代码了。我们此时可以对比一下原有ICTCLAS中GetElement的实现:
PARRAY_CHAIN *pRet)
{
PARRAY_CHAIN pCur = pStart;
if (pStart == 0)
pCur = m_pHead;
if (pRet != 0)
*pRet = NULL;
if (nRow > (int)m_nRow || nCol > (int)m_nCol)
//Judge if the row and col is overflow
return INFINITE_VALUE;
if (m_bRowFirst)
{
while (pCur != NULL && (nRow != - 1 && (int)pCur->row < nRow || (nCol !=
- 1 && (int)pCur->row == nRow && (int)pCur->col < nCol)))
{
if (pRet != 0)
*pRet = pCur;
pCur = pCur->next;
}
}
else
{
while (pCur != NULL && (nCol != - 1 && (int)pCur->col < nCol || ((int)pCur
->col == nCol && nRow != - 1 && (int)pCur->row < nRow)))
{
if (pRet != 0)
*pRet = pCur;
pCur = pCur->next;
}
}
if (pCur != NULL && ((int)pCur->row == nRow || nRow == - 1) && ((int)pCur
->col == nCol || nCol == - 1))
//Find the same position
{
//Find it and return the value
if (pRet != 0)
*pRet = pCur;
return pCur->value;
}
return INFINITE_VALUE;
}
可以看出,将原有GetElement方法拆分成3个方法后,代码得到大大简化,而且逻辑更为清晰了。
3、性能与代码可读性的权衡
DynamicArray类为了确保代码的清晰可读,在某些地方做了些调整,让我们对比一下SharpICTCLAS与ICTCLAS中在这方面的不同考虑。下面的代码演示了GetFirstElementOfRow方法在两者之间的不同之处(我特意对ICTCLAS代码做了逻辑上的简化):
// SharpICTCLAS 中的查找行为 nRow 的第一个结点
//====================================================================
public ChainItem<T> GetFirstElementOfRow(int nRow)
{
ChainItem<T> pCur = pHead;
while (pCur != null && pCur.row != nRow)
pCur = pCur.next;
return pCur;
}
//====================================================================
// ICTCLAS 中的查找行为 nRow 的第一个结点
//====================================================================
... GetElement(int nRow, int nCol, PARRAY_CHAIN pStart, PARRAY_CHAIN *pRet)
{
PARRAY_CHAIN pCur = pStart;
while (pCur != NULL && (pCur->row < nRow || (pCur->row == nRow && pCur->col < nCol)))
{
if (pRet != 0)
*pRet = pCur;
pCur = pCur->next;
}
if (pCur != NULL && pCur->row == nRow && pCur->col == nCol)
{
if (pRet != 0)
*pRet = pCur;
return pCur->value;
}
//......
}
从上面代码中可以看出,原有ICTCLAS代码充分考虑到DynamicArray是一个排序链表,因此仅仅在pCur->row < nRow与pCur->col < nCol范围内检索,如果找到了“pCur->row == nRow && pCur->col == nCol”,那么再去做该做的事情。
而SharpICTCLAS中,判断条件仅为“pCur != null && pCur.row != nRow”,这意味着如果你要找的nRow不再该链表中,则会来个“完全遍历”,搜索范围似乎太大了。
不过出于以下几点考虑我还是采用了这种表示方式:
1)汉语中的一句话不会太长,这意味着链表长度不会很长,即使来个“完全遍历”也不会牺牲多少时间。
2)毕竟要找的nRow不在该链表中的可能性不大,出现“完全遍历”的机会也不多。
3)原有ICTCLAS虽然在搜索范围内下了翻功夫,但为了确保pRet变量得到赋值,循环体内部多次执行了“if (pRet != 0)”的判断,这从性能角度上说得不偿失。
4)原有ICTCLAS为了缩小搜索范围确增加了条件判断次数“pCur != NULL && (pCur->row < nRow || (pCur->row == nRow && pCur->col < nCol))”,而由此带来的性能损失不得不考虑一下。
正因为以上几点考虑,所以在SharpICTCLAS中采用了这种简单而且并不见得低效的方式取代原有的GetElement方法。
- 小结
SharpICTCLAS重新设计了DynamicArray类,力争简化原有设计中复杂的代码逻辑,应当说效果比较明显。即便有性能损失,那也是微不足道的,权衡利弊,我选择了走简单的代码这条路。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)