Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders学习笔记
关系抽取学习笔记
Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders
使用序列表编码器联合提取实体和实体关系
设计2个不同的编码器来补货实体识别和关系抽取这2中不同类型的信息。
提出“表序列编码器”,包含2中不同的编码器:1 表编码器 2 序列编码器
在本文中,我们提出了一种新的方法来解决上述局限性。我们不是用单一的表示来预测实体和关系,而是专注于学习两种表示,分别用于NER和RE的序列表示和表表示。一方面,这两种不同的表示可以用于捕获特定于任务的信息。另一方面,我们设计了一种机制来允许它们彼此交互,以便利用NER和RE任务背后的内在关联。此外,我们采用神经网络架构,可以更好地捕捉二维表表示中的结构信息。我们将看到,这种结构信息(特别是表中相邻条目的上下文)对于获得更好的性能是至关重要的。
使用BERT 的注意力权值来表(Table)表示
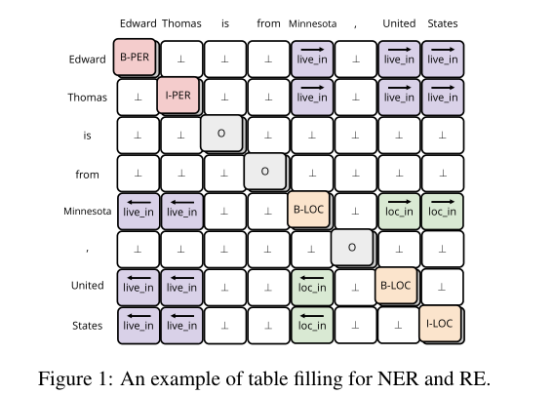
NER还是用序列标记问题(BIO),放在对角线。⊥表示没有关系。矩阵对称(?)
TEXT EMBEDDING:
对于每一个词,定义xw,词嵌入。定义xc,字符嵌入,通过LSTM计算,定义xl,带有上下文的词嵌入(来自BERT)。
把 xc xw xl拼接起来,并用线性投影来形成初始序列。 每个词被表示为一个H维的向量。
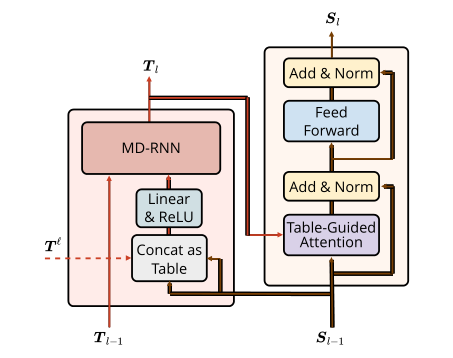
TABLE ENCODER
N*N的 向量表。
构建一个上下文无关的表,接着是一个全连接层来使得隐藏层减半。第L层,有XL的规模是N*N*H。XLij=ReLU(Linear(SL-1,i,SL-1,j))
接下来是MD-RNN 多维RNN。
上一层的同位置 传递数据,同层的四周4个也传递数据给当前cell。
迭代计算每个cell的隐藏状态,形成上下文有关的表:Tl
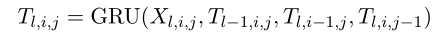
GRU多维适应。
4个方向的RNN
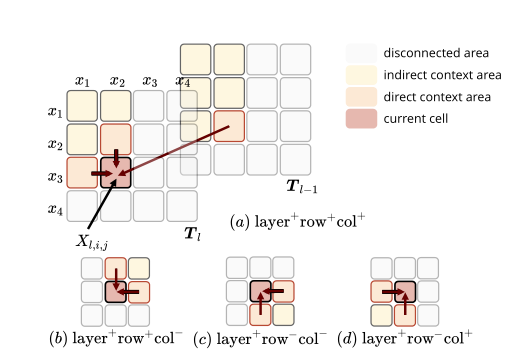
根据经验,我们发现,仅考虑图4中的情形(a)和(c)的情况,其效果并不比同时考虑四种情形的情况差。因此,为了减少计算量,我们使用这样的设置作为默认值。最终的表表示法是将两个rnn的隐藏状态串联起来:
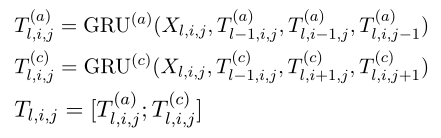
SEQUENCE ENCODER
用表引导的注意力、
表格引导注意力可以扩展为多个头(V aswani et al., 2017),其中每个头都是具有独立参数的注意力。我们将它们的输出串联起来,并使用一个完全连接的层来获得最终的注意力输出。
其余部分与变压器类似。对于层l,我们使用自注意后的位置前馈神经网络(FFNN),用残差连接(He et al., 2016)和层归一化(Ba et al., 2016)将注意力和FFNN包起来,得到输出序列表示
Exploit Pre-trained Attention Weights(利用预先训练好的注意力权重) 上图中的虚线就是了。
从本质上说,是从预训练模型(BERT)中,以注意力权重的形式利用信息。
把所有头和所有层的注意力值叠加。
L是层 A 是头

用SL 和TL来预测实体和关系标签的概率分布
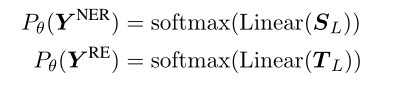
目标是最小化 LossNER+LossRE 这个损失。
在评价过程中,关系的预测依赖实体的预测。首先实体预测,查关系概率表看实体之间是否存在有效的关系。
选择最大概率 来预测每个词的实体标签
将实体上的关系映射为在实体的单词上概率最高的关系类。考虑2个方向的实体标签
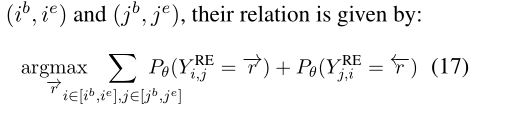
B=begin E=end
标签矩阵对称但是方向相反。
实验
关系不对称,两个实体的顺序很重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号