OpenCV二维Mat数组(二级指针)在CUDA中的使用
CUDA用于并行计算非常方便,但是GPU与CPU之间的交互,比如传递参数等相对麻烦一些。在写CUDA核函数的时候形参往往会有很多个,动辄达到10-20个,如果能够在CPU中提前把数据组织好,比如使用二维数组,这样能够省去很多参数,在核函数中可以使用二维数组那样去取数据简化代码结构。当然使用二维数据会增加GPU内存的访问次数,不可避免会影响效率,这个不是今天讨论的重点了。
举两个代码栗子来说明二维数组在CUDA中的使用(亲测可用):
1. 普通二维数组示例:
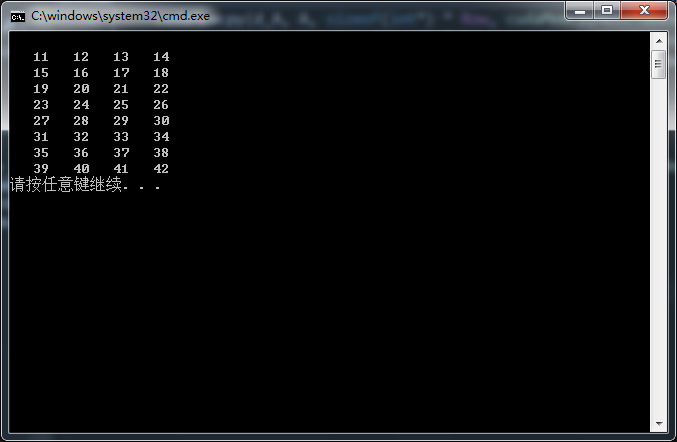
输入:二维数组A(8行4列)
输出:二维数组C(8行4列)
函数功能:将数组A中的每一个元素加上10,并保存到C中对应位置。
这个是一个简单的示例,以一级指针和二级指针开访问二维数组中的数据,主要步骤如下:
(1)为二级指针A、C和一级指针dataA、dataC分配CPU内存。二级指针指向的内存中保存的是一级指针的地址。一级指针指向的内存中保存的是输入、输出数据。
(2)在设备端(GPU)上同样建立二级指针d_A、d_C和一级指针d_dataA、d_dataC,并分配GPU内存,原理同上,不过指向的内存都是GPU中的内存。
(3)通过主机端一级指针dataA将输入数据保存到CPU中的二维数组中。
(4)关键一步:将设备端一级指针的地址,保存到主机端二级指针指向的CPU内存中。
(5)关键一步:使用cudaMemcpy()函数,将主机端二级指针中的数据(设备端一级指针的地址)拷贝到设备端二级指针指向的GPU内存中。这样在设备端就可以使用二级指针来访问一级指针的地址,然后利用一级指针访问输入数据。也就是A[][]、C[][]的用法。
(6)使用cudaMemcpy()函数将主机端一级指针指向的CPU内存空间中的输入数据,拷贝到设备端一级指针指向的GPU内存中,这样输入数据就算上传到设备端了。
(7)在核函数addKernel()中就可以使用二维数组的方法进行数据的读取、运算和写入。
(8)最后将设备端一级指针指向的GPU内存中的输出数据拷贝到主机端一级指针指向的CPU内存中,打印显示即可。
#include <cuda_runtime.h> #include <device_launch_parameters.h> #include <opencv2\opencv.hpp> #include <iostream> #include <string> using namespace cv; using namespace std; #define Row 8 #define Col 4 __global__ void addKernel(int **C, int **A) { int idx = threadIdx.x + blockDim.x * blockIdx.x; int idy = threadIdx.y + blockDim.y * blockIdx.y; if (idx < Col && idy < Row) { C[idy][idx] = A[idy][idx] + 10; } } int main() { int **A = (int **)malloc(sizeof(int*) * Row); int **C = (int **)malloc(sizeof(int*) * Row); int *dataA = (int *)malloc(sizeof(int) * Row * Col); int *dataC = (int *)malloc(sizeof(int) * Row * Col); int **d_A; int **d_C; int *d_dataA; int *d_dataC; //malloc device memory cudaMalloc((void**)&d_A, sizeof(int **) * Row); cudaMalloc((void**)&d_C, sizeof(int **) * Row); cudaMalloc((void**)&d_dataA, sizeof(int) *Row*Col); cudaMalloc((void**)&d_dataC, sizeof(int) *Row*Col); //set value for (int i = 0; i < Row*Col; i++) { dataA[i] = i+1; } //将主机指针A指向设备数据位置,目的是让设备二级指针能够指向设备数据一级指针 //A 和 dataA 都传到了设备上,但是二者还没有建立对应关系 for (int i = 0; i < Row; i++) { A[i] = d_dataA + Col * i; C[i] = d_dataC + Col * i; } cudaMemcpy(d_A, A, sizeof(int*) * Row, cudaMemcpyHostToDevice); cudaMemcpy(d_C, C, sizeof(int*) * Row, cudaMemcpyHostToDevice); cudaMemcpy(d_dataA, dataA, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); dim3 block(4, 4); dim3 grid( (Col + block.x - 1)/ block.x, (Row + block.y - 1) / block.y ); addKernel << <grid, block >> > (d_C, d_A); //拷贝计算数据-一级数据指针 cudaMemcpy(dataC, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost); for (int i = 0; i < Row*Col; i++) { if (i%Col == 0) { printf("\n"); } printf("%5d", dataC[i]); } printf("\n"); }
2.OpenCV中Mat数组示例
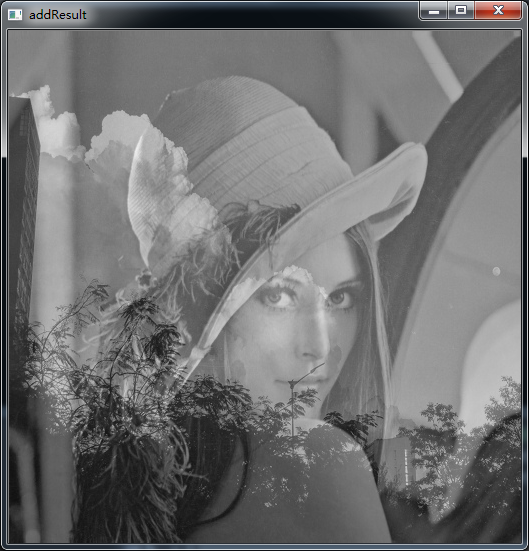
输入:图像Lena.jpg
输出:图像moon.jpg
函数功能:求两幅图像加权和
原理和上面一样,流程上的差别就是输入的二维数据是下面两幅图像数据,然后在CUDA中进行加权求和。


效果如下:
代码在此,以供参考
#include <cuda_runtime.h> #include <device_launch_parameters.h> #include <opencv2\opencv.hpp> #include <iostream> #include <string> using namespace cv; using namespace std; __global__ void addKernel(uchar **pSrcImg, uchar* pDstImg, int imgW, int imgH) { int tidx = threadIdx.x + blockDim.x * blockIdx.x; int tidy = threadIdx.y + blockDim.y * blockIdx.y; if (tidx<imgW && tidy<imgH) { int idx=tidy*imgW+tidx; uchar lenaValue=pSrcImg[0][idx]; uchar moonValue=pSrcImg[1][idx]; pDstImg[idx]= uchar(0.5*lenaValue+0.5*moonValue); } } int main() { //OpenCV读取两幅图像 Mat img[2]; img[0]=imread("data/lena.jpg", 0); img[1]=imread("data/moon.jpg", 0); int imgH=img[0].rows; int imgW=img[0].cols; //输出图像 Mat dstImg=Mat::zeros(imgH, imgW, CV_8UC1); //主机指针 uchar **pImg=(uchar**)malloc(sizeof(uchar*)*2); //输入 二级指针 //设备指针 uchar **pDevice;//输入 二级指针 uchar *pDeviceData;//输入 一级指针 uchar *pDstImgData;//输出图像对应设备指针 //分配GPU内存 cudaError err; //目标输出图像分配GPU内存 err=cudaMalloc(&pDstImgData, imgW*imgH*sizeof(uchar)); //设备二级指针分配GPU内存 err=cudaMalloc(&pDevice, sizeof(uchar*)*2); //设备一级指针分配GPU内存 err=cudaMalloc(&pDeviceData, sizeof(uchar)*imgH*imgW*2); //关键:主机二级指针指向设备一级指针位置,这样才能使设备的二级指针指向设备的一级指针位置 for (int i=0; i<2; i++) { pImg[i]=pDeviceData+i*imgW*imgH; } //拷贝数据到GPU //拷贝主机二级指针中的元素到设备二级指针指向的GPU位置 (这个二级指针中的元素是设备中一级指针的地址) err=cudaMemcpy(pDevice, pImg, sizeof(uchar*)*2, cudaMemcpyHostToDevice); //拷贝图像数据(主机一级指针指向主机内存) 到 设备一级指针指向的GPU内存中 err=cudaMemcpy(pDeviceData, img[0].data, sizeof(uchar)*imgH*imgW, cudaMemcpyHostToDevice); err=cudaMemcpy(pDeviceData+imgH*imgW, img[1].data, sizeof(uchar)*imgH*imgW, cudaMemcpyHostToDevice); //核函数实现lena图和moon图的简单加权和 dim3 block(8, 8); dim3 grid( (imgW+block.x-1)/block.x, (imgH+block.y-1)/block.y); addKernel<<<grid, block>>>(pDevice, pDstImgData, imgW, imgH); cudaThreadSynchronize(); //拷贝输出图像数据至主机,并写入到本地 err=cudaMemcpy(dstImg.data, pDstImgData, imgW*imgH*sizeof(uchar), cudaMemcpyDeviceToHost); imwrite("data/synThsis.jpg", dstImg); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号