大数据平台Lambda架构浅析(全量计算+增量计算)
笔者刚接触大数据方面时,只知道Hadoop和时下很火的Spark,对Hadoop、Spark的认知只停留在跑跑demo,写点离线小app,后来随着学业项目的需要,开始逐步了解时下工业界的大数据平台是如何搭建起来的。在搜刮大量资料后,从一篇paper里看到Lambda这一陌生的字眼,再一搜,发现这正是我需要的大数据平台基础架构。Oryx2正是基于Lambda架构和Spark搭建的大数据处理开源框架。
废话不多说,谨以此篇博文记录自己对lambda架构的理解 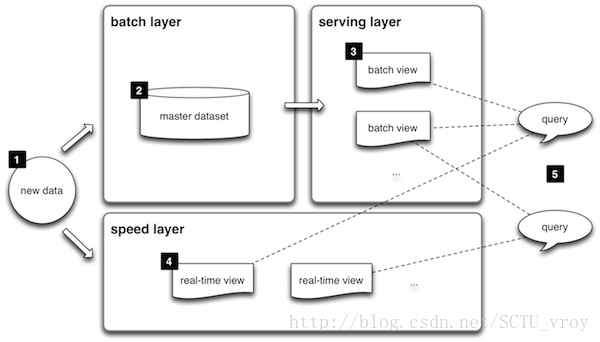
上图便是从lambda官网盗取的架构图
1:所有数据都来自于同一入口,然后被分发到batch layer(批处理层)和speed layer(实时计算层)
对于数据来源,可参考Oryx2的做法,统一采用Kafka接入Spark Streaming,然后再根据订阅的topic分发数据到batch layer和speed layer。关于Kafka接入Spark Streaming,确实挺多坑,当然对Kafka熟悉的大神就很easy,对我这种菜鸡来说着实吃力。
我试了两种方式(Kafka 0.10.1 + Spark 2.0.0):
1)Spark官网提供的方法,详尽参考Spark Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher),按照教程一步一步来,肯定可以成功
2)使用开源框架kafka-spark-consumer,由于此框架对应的spark版本是spark1.6.0,kafka支持的版本有0.8、0.9、0.10,所以可以放心接入,只是使用spark2.0+的童鞋需要手动更改下框架中提供的demo(SampleConsumer.java),此框架亲测可用!
2:batch layer官网给出简略解释是:两个作用{1)管理全量数据(不可变的,且只用append方式增加数据;2)处理全量数据得出模型–>结果)
对于batch layer,主要用于全量计算,处理所有历史数据,这里有三点注意:
1)数据是有限的
2)数据需要被持久化
3)数据量大–>导致处理过程high latency
那么,批处理层怎么实现好呢?
从Kafka接入数据到Spark Streaming后,处理每个rdd,将rdd中数据解析结构化并持久化到HDFS中。笔者是基于HBase+Parquet+Spark SQL的机制来做处理,首先将所有原数据保存到HBase的一张表中,然后根据row key(可加入时间戳)读取HBase数据,根据读取到的数据从remote server文件数据源服务器fetch文件到平台的HDFS,用Parquet记录文件中需要作为训练集的信息,训练模型时再用Spark SQL去读parquet file(仅供参考,过程可根据业务不同调整)
3:serving layer主要用于merge 批处理层和speed层结果,供外部web接口查询结果用的
4:speed layer的出现主要是弥补batch layer高延时的缺点,是一种增量计算的处理层
怎么理解和实现“增量计算”呢?说实话,这着实让我费解了好久……
其实,说白了,就是对从时间起始点开始进入系统的数据,采用分块处理的方式,将数据分成各自独立的进行处理,即micro-batch processing。Spark Streaming就是基于这种思想衍生而来的。
对于流入speed layer的数据集,有三点需要注意:
1)数据是“无限”的
2)当前处理中的数据集(工作集)可能是相关的,且同时只限制于当前数据集(即与其他数据集无关)
3)处理是基于事件的,只有被明确停止才会结束;得到的结果会立即生效并且随着新数据进入会实时更新
当前很火的流计算框架有:Storm、Spark Streaming等
Spark Streaming官网这张图就很直观的解释了什么是micro-batch processing: 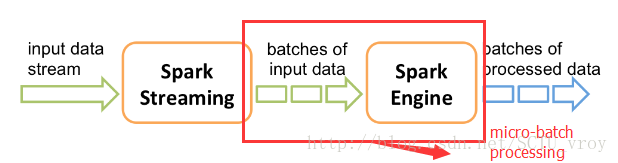
Spark Streaming还提供另一个操作:window operations(滑动窗) 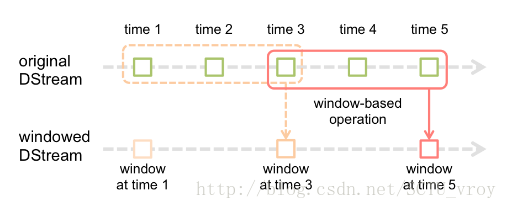
通过指定window length(窗的长度)+ sliding interval(滑动间隔),即可将数据流分成相对独立的小块,随着窗口的滑动即可分批处理流入的数据,这正是speed layer处理数据流的精髓所在
像Oryx2,batch layer和speed layer是开启两个不同的StreamingContext,从kafka消化数据做处理(Spark中,一个JVM进程只能同时存在一个streamingContext)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号