
MongoDB 中的索引分析
MongoDB 的索引
前言
MongoDB 在使用的过程中,一些频繁的查询条件我们会考虑添加索引。
MongoDB 中支持多种索引
1、单键索引:在单个字段上面建立索引;
2、复合索引:复合索引支持在多个字段建立索引匹配查询;
3、多键索引:对数组或者嵌套文档的字段进行索引;
4、地理空间索引:对包含地理坐标的字段进行索引;
5、文本索引:对文本字段进行全文索引;
6、哈希索引:将字段值进行哈希处理后进行索引;
7、通配符索引:使用通配符对任意字段进行索引;
下面来看下 MongoDB 中的索引实现的底层逻辑。
MongoDB 使用 B 树还是 B+ 树索引
先来看下 B 树和 B+ 树的区别。
B 树 和 B+ 树最重要的区别是 B+ 树只有叶子节点存储数据,其他节点用于索引,而 B 树 对于每个索引节点都有 Data 字段。
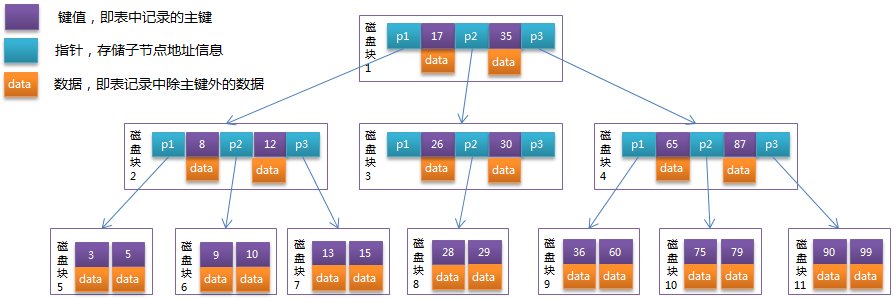
B 树简单的讲就是一种多叉平衡查找树,它类似于普通的平衡二叉树。不同的是 B 树 允许每个节点有更多的子节点,这样就能大大减少树的高度。
B 树 结构图中可以看到每个节点中不仅包含数据的 key 值,还有 data 值。而每一个页的存储空间是有限的,如果 data 数据较大时将会导致每个节点(即一个页)能存储的 key 的数量很小,当存储的数据量很大时同样会导致 B 树的深度较大,增大查询时的磁盘 I/O 次数,进而影响查询效率。
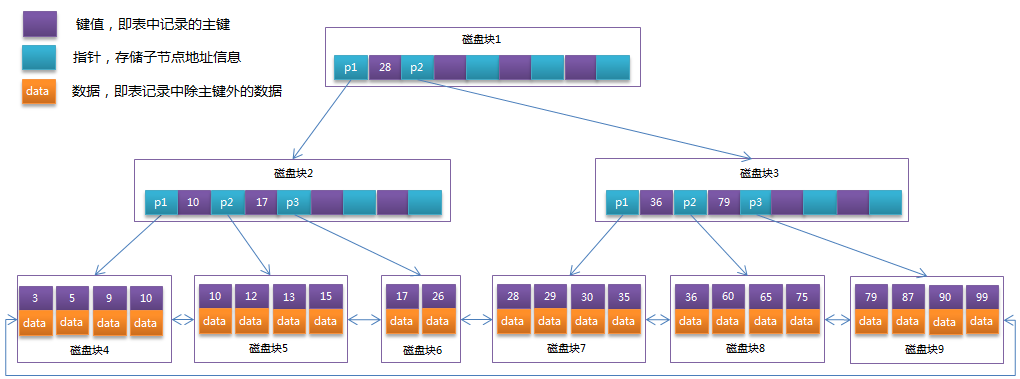
在 B+Tree 中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储 key 值信息,这样可以大大加大每个节点存储的 key 值数量,降低 B+Tree 的高度。
B+ 树相比与 B 树:
1、非叶子节点只存储索引信息;
2、所有叶子节点都有一个链指针,所以B+ 树可以进行范围查询;
3、数据都放在叶子节点中。
那么 MongoDB 使用的是什么索引呢?在网上搜索会发现很多文章 MongoDB 用的是 B 树,这个答案是不准确的。
MongoDB 官网中有一段描述写的是MongoDB索引使用 B-tree 数据结构。
Indexes are special data structures that store a small portion of the collection's data set in an easy-to-traverse form. MongoDB indexes use a B-tree data structure.
The index stores the value of a specific field or set of fields, ordered by the value of the field. The ordering of the index entries supports efficient equality matches and range-based query operations. In addition, MongoDB can return sorted results using the ordering in the index.
大致意思就是 MongoDB 使用的是 B-tree 数据结构,支持等值匹配和范围查询。可以使用索引的排序返回排序的结果。
在很地方我们会看到 B-tree, B-tree 树即 B 树。B 即 Balanced 平衡,因为 B 树的原英文名称为 B-tree,而国内很多人喜欢把 B-tree 译作 B-树,这是个非常不好的直译,很容易让人产生误解,人们可能会以为 B-树 和 B树 是两种树。
上面的 B 树 和 B+ 树的对比我们知道,B 树因为没有 B+ 中叶子节点的链指针,所以 B 树是不支持的范围查询的。
MongoDB 官网中的介绍中明确的表示 MongoDB 支持范围查询,所以我们可以得出结论用的就是 B+ 树。官网中讲的 B 树,指广义上的 B 树,因为 B+ 树也是 B 树的变种也能称为 B 树。
MongoDB 从 3.2 开始就默认使用 WiredTiger 作为存储引擎。
WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
根据 WiredTiger 官方文档的描述 WiredTiger 就是 B+ 树,非叶子节点上只存储 key 值信息,叶子节点会存储 key 和 data 的数据。
文档地址WiredTiger Tuning page size and compression
所以可以得出结论 MongoDB 默认的存储引擎 WiredTiger 目前使用的是 B+ 树索引结构。
单键索引
单键索引:只针对一个键添加索引,是最简单的索引类型。
创建单键索引
db.test_explain.createIndex({ name: 1 },{background: true})
其中 1 指定升序创建索引,-1 表示指定降序创建索引。
这里介绍几个创建索引常用的参数属性
-
background:表示在后台创建索引,这种索引的创建会在后台进行,不会阻塞其他数据库操作。相反,普通的索引创建会在创建过程中锁定读写操作,可能导致其他操作的延迟。没有特殊情况,创建索引都需要添加 background 标识;
-
unique:创建的索引是否唯一,指定为 true 创建唯一索引。默认值为false;
-
expireAfterSeconds:指定一个以秒为单位的数值,完成 TTL 设定,设定集合的生存时间;
-
sparse:对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为 true 的话,在索引字段中不会查询出不包含对应字段的文档。默认值为 false;
-
weights:索引权重值,数值在 1 到 99999 之间,表示该索引相对于其他索引字段的得分权重。
使用 expireAfterSeconds 创建 TTL 索引
这里主要介绍下 expireAfterSeconds
MongoDB 中提供了 TTL 索引自动在后台清理过期的数据,该功能主要用于数据清理和分布式锁等业务场景中。
比如用于数据过期的场景,假定数据的有效期是10分钟,我们可以指定数据表中的一个时间字段用于数据生成的时间,当然这个时间一般就是数据的创建时间,然后针对这个字段设置 TTL 过期索引。
根据创建时间字段 createdAt 创建 ttl 索引,过期时间设置成 10 分钟
db.test_explain.createIndex( { "createdAt": -1 }, { expireAfterSeconds: 600 } )
准备数据
db.test_explain.insert({name:"小明1",age:12,createdAt:ISODate()})
db.test_explain.insert({name:"小明2",age:12,createdAt:ISODate()})
db.test_explain.insert({name:"小明3",age:12,createdAt:ISODate()})
db.test_explain.insert({name:"小明4",age:12,createdAt:ISODate()})
db.test_explain.insert({name:"小明5",age:12,createdAt:ISODate()})
replica:PRIMARY> db.test_explain.find()
{ "_id" : ObjectId("650c329af2f532226d92da41"), "name" : "小明1", "age" : 12, "createdAt" : ISODate("2023-09-21T12:10:02.190Z") }
{ "_id" : ObjectId("650c329af2f532226d92da42"), "name" : "小明2", "age" : 12, "createdAt" : ISODate("2023-09-21T12:10:02.270Z") }
{ "_id" : ObjectId("650c329af2f532226d92da43"), "name" : "小明3", "age" : 12, "createdAt" : ISODate("2023-09-21T12:10:02.388Z") }
{ "_id" : ObjectId("650c329af2f532226d92da44"), "name" : "小明4", "age" : 12, "createdAt" : ISODate("2023-09-21T12:10:02.471Z") }
{ "_id" : ObjectId("650c329af2f532226d92da45"), "name" : "小明5", "age" : 12, "createdAt" : ISODate("2023-09-21T12:10:02.585Z") }
replica:PRIMARY> Date()
Thu Sep 21 2023 20:10:12 GMT+0800 (CST)
10分钟之后发现创建的几条数据已经不存在了
replica:PRIMARY> db.test_explain.find()
replica:PRIMARY> Date()
Thu Sep 21 2023 20:20:27 GMT+0800 (CST)
实现原理和缺陷
每个 MongoDB 进程在启动时候,都会创建一个 TTLMonitor 后台线程,进程会每隔 60s 发起一轮 TTL 清理操作,每轮 TTL 操作会在搜集完实例上的 TTL 索引后,依次对每个 TTL 索引生成执行计划并进行数据清理操作。
TTL 会存在两个明显的缺陷
1、时效性差。每隔 60s 才会发起一轮清理,不能保证数据立马过期就马上被删除,60s 可以动态调整,也无法突破妙级。TTL 是单线程,如果数据库中有多个表都有 TTL 索引,数据清理操作只能一个个串行的操作。如果 MongoDB 执行的高并发数据插入,很可能导致数据的 TTL 的删除跟不上数据的插入,造成空间的膨胀。
2、TTL 的删除可能产生现资源消耗的带来性能毛刺。TTL 的本质还是根据索引执行数据的删除,可能会带来一定程度上的性能压力。比如 索引扫描和数据删除操作会带来一定的 cache 和 IO 压力,删除操作记录 oplog 会增加数据同步延迟等,如果实例规格不高,是很容易出现性能毛刺。
对于 TTL 毛刺的问题可以考虑将时间打散在一天内的各个时刻。比如对于选择创建索引的时间字段,可以考虑时间精确到秒,这样 TTL 删除操作就能避免在同一时刻发生,造成某个时间点的性能毛刺。
复合索引
MongoDB 中支持复合索引,复合索引就是将多个键值对组合到一起创建索引,也叫做复合索引。
最左匹配原则
最左匹配原则
MongoDB 中复合索引的使用和 MySQL 中复合索引的使用类似,也有最左匹配原则。即最左优先,在检索数据时从复合索引的最左边开始匹配。具体的最左匹配原则可参见MySQL 复合索引
复合索引创建的时候有一个一个基本的原则就是将选择性最强的列放到最前面。
选择性最高值得是数据的重复值最少,因为区分度高的列能够很容易过滤掉很多的数据。组合索引中第一次能够过滤掉很多的数据,后面的索引查询的数据范围就小了很多了。
ESR 规则
遵循 ESR 规则
MongoDB 中复合索引的使用,对于索引的创建的顺序有一个原则就是 ESR 规则。

为什么会有 ESR 规则呢?
这要从最左前缀说起,因为 MongoDB 中用的也是 B+ 树,所以和 MySQL 中基本一样,索引匹配有最左前缀的原则。
这里借用 MySQL 中的索引栗子来解释下 ESR 规则。
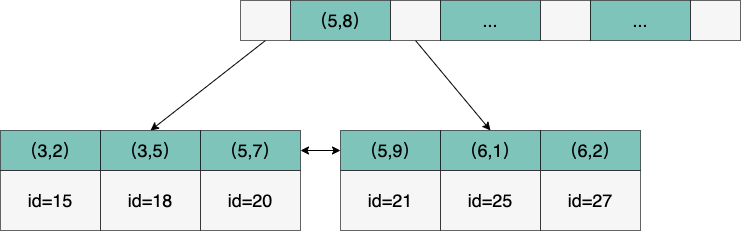
可以看到复合索引中 index_a_b (a,b) a 是有顺序的,所以索引 a 列是可以使用这个复合索引的,索引 b 列只是相对索引 a 列是有序的,本身是无序,所以单索引 b 列是不能使用这个复合索引的。
最左匹配原则中,MySQL 会一直向右匹配,遇到范围查询(>、<、between、like),就会停止匹配,因此,当执行 a = 1 and b = 2 时 a,b 字段能用到索引的。但是执行 a > 1 and b = 2 时,只有 a 字段能用到索引,b 字段用不到索引。因为 a 的值此时是一个范围,不是固定的,在这个范围内 b 值不是有序的,因此 b 字段用不上索引。如果建立 (b,a) 的索引顺序则都能用到索引。
因为碰到范围查询,B+ 树后面的查询就不能使用索引了,排序就会在内存中进行。这就有了 ESR 规则,将范围查询的索引建在复合索引的最后面。
因为MongoDB 和 MySQL 使用的都是 B+ 树索引,这个原则两者同样适用。
这里来自栗子来简单的验证下
准备数据
db.getCollection("test_explain").insert( {
_id: ObjectId("650ce97ec5a69f4d4d181c20"),
name: "小明5",
age: 15,
createdAt: ISODate("2022-08-22T01:10:22.584Z")
} );
db.getCollection("test_explain").insert( {
_id: ObjectId("650ce97ec5a69f4d4d181c1f"),
name: "小明4",
age: 14,
createdAt: ISODate("2023-06-22T01:10:22.442Z")
} );
db.getCollection("test_explain").insert( {
_id: ObjectId("650ce97ec5a69f4d4d181c1e"),
name: "小明3",
age: 13,
createdAt: ISODate("2023-07-22T01:10:22.379Z")
} );
db.getCollection("test_explain").insert( {
_id: ObjectId("650ce97ec5a69f4d4d181c1d"),
name: "小明2",
age: 12,
createdAt: ISODate("2023-09-22T01:10:22.317Z")
} );
db.getCollection("test_explain").insert( {
_id: ObjectId("650ce97ec5a69f4d4d181c1c"),
name: "小明1",
age: 11,
createdAt: ISODate("2023-01-22T01:10:22.255Z")
} );
首先创建不遵循 ESR 原则的索引
db.test_explain.createIndex( {"createdAt": -1,"name": -1,"age": -1 }, {background: true})
分析下组合查询索引的命中情况
db.getCollection("test_explain").find({"name" : "小明5","createdAt" : {$gte : ISODate("2022-08-22T01:10:22.584Z")}}).sort({age: -1}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "gleeman.test_explain",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : [
{
"name" : {
"$eq" : "小明5"
}
},
{
"createdAt" : {
"$gte" : ISODate("2022-08-22T01:10:22.584Z")
}
}
]
},
"winningPlan" : {
"stage" : "SORT", // 表示在内存中发生了排序
"sortPattern" : {
"age" : -1
},
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR", // 表示在内存中发生了排序
"inputStage" : {
"stage" : "FETCH", // 子的 stage,说明查询命中了一部分的索引
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"createdAt" : -1,
"name" : -1,
"age" : -1
},
"indexName" : "createdAt_-1_name_-1_age_-1",
"isMultiKey" : false,
"multiKeyPaths" : {
"createdAt" : [ ],
"name" : [ ],
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"createdAt" : [
"[new Date(9223372036854775807), new Date(1661130622584)]"
],
"name" : [
"[\"小明5\", \"小明5\"]"
],
"age" : [
"[MaxKey, MinKey]"
]
}
}
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "host-192-168-61-214",
"port" : 27017,
"version" : "4.0.3",
"gitVersion" : "0377a277ee6d90364318b2f8d581f59c1a7abcd4"
},
"ok" : 1,
"operationTime" : Timestamp(1695345552, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1695345552, 2),
"signature" : {
"hash" : BinData(0,"jjH0WLFEpYO4E8ZzX0AD2M+0PDQ="),
"keyId" : NumberLong("7233287468395528194")
}
}
}
上面的查询栗子,对于这个组合索引,只是命中其中一部分,然后排序还是在内存中进行的。根据上面的原理分析,我们可以简单的分析出,针对 createdAt 的范围查询使用到了组合索引,后面的查询就没有走到索引。可以明确的看到在内存中发生了排序的操作。
还是上面的查询条件,下面创建一个符合 ESR 原则的索引
db.test_explain.createIndex( {"name": -1,"age": -1,"createdAt": -1}, {background: true})
使用 explain 查询索引的命中情况
db.getCollection("test_explain").find({"name" : "小明5","createdAt" : {$gte : ISODate("2022-08-22T01:10:22.584Z")}}).sort({age: -1}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "gleeman.test_explain",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : [
{
"name" : {
"$eq" : "小明5"
}
},
{
"createdAt" : {
"$gte" : ISODate("2022-08-22T01:10:22.584Z")
}
}
]
},
"winningPlan" : {
"stage" : "FETCH", // 根据索引检索指定的文档
"inputStage" : {
"stage" : "IXSCAN", // 索引扫描
"keyPattern" : { // 查询命中的索引
"name" : -1,
"age" : -1,
"createdAt" : -1
},
"indexName" : "name_-1_age_-1_createdAt_-1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ],
"age" : [ ],
"createdAt" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"小明5\", \"小明5\"]"
],
"age" : [
"[MaxKey, MinKey]"
],
"createdAt" : [
"[new Date(9223372036854775807), new Date(1661130622584)]"
]
}
}
},
"rejectedPlans" : [
{
"stage" : "SORT",
"sortPattern" : {
"age" : -1
},
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR",
"inputStage" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"createdAt" : -1,
"name" : -1
},
"indexName" : "createdAt_-1_name_-1",
"isMultiKey" : false,
"multiKeyPaths" : {
"createdAt" : [ ],
"name" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"createdAt" : [
"[new Date(9223372036854775807), new Date(1661130622584)]"
],
"name" : [
"[\"小明5\", \"小明5\"]"
]
}
}
}
}
}
]
},
"serverInfo" : {
"host" : "host-192-168-61-214",
"port" : 27017,
"version" : "4.0.3",
"gitVersion" : "0377a277ee6d90364318b2f8d581f59c1a7abcd4"
},
"ok" : 1,
"operationTime" : Timestamp(1696643394, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1696643394, 2),
"signature" : {
"hash" : BinData(0,"Bp6y2c2vfCPRgdl4WYwMicL36FM="),
"keyId" : NumberLong("7233287468395528194")
}
}
}
可以看到创建 ESR 原则的索引,上面的查询,就完全走索引了。
如何使用排序条件
再来看下 MongoDB 中的排序
在 MongoDB 中,排序的字段我们可以添加索引来保证排序的高效性,如果排序的字段没有添加索引或者添加的索引没有命中,那么排序就会在内存中进行。
同时,MongoDB 一次查询中只能使用一个索引,$or 特殊,可以在每个分支条件上使用一个索引,所以对于 MongoDB 中的查询,如果带有有排序的查询需求,即使排序的字段加了单列索引,有时候也命中不了,排序可能在内存中进行。
MongoDB 中内存排序效率不高,内存中排序是有内存大小的限制的,版本不同,这个默认的内存也不一样,如果超过这个限制就会报错。在 4.4 版本,引入了 cursor.allowDiskUse() 可以控制,排序内存超的时候,允许或禁止在磁盘上写入临时文件,将排序操作在磁盘中完成。磁盘的 I/O 是没有内存效率高的,所以 MongoDB 在排序没有命中索引的情况下,大数据量的排序效率很低。
从 MongoDB 6.0 开始,需要大于 100 MB 内存的操作默认会自动将数据写入临时文件。
因为排序效率不高,在查询条件带有排序的操作情况,一般考虑将排序字段也添加到组合索引中。至于字段的先后顺序,可以参见上文中的 ESR 规则。
单字段创建索引,无论是升序还是降序,对 sort 查询没有影响,MongoDB 可以从任意一方向遍历索引。但是复合索引,排序字段的升序降序对查询的的结果就有影响了。
来个栗子
假定有一个集合 events ,其中包含两个字段 username 和 date。
创建索引 db.events.createIndex( { "username" : 1, "date" : -1 } )
下面的两种查询能够命中索引
db.events.find().sort( { username: 1, date: -1 } ) db.events.find().sort( { username: -1, date: 1 } )
但是下面的这种查询就不能命中了
db.events.find().sort( { username: 1, date: 1 } )
为什么呢?
因为 MongoDB 用的还是 B+ 树,当创建 db.events.createIndex( { "username" : 1, "date" : -1 } ) 索引。B+ 数上的结构,username 从左到右是相对升序的。date 字段相对 username 字段,从左到右是降序的。
如果执行 db.events.find().sort( { username: 1, date: 1 } ) 查询,username 字段从左边查询命中了创建的索引,但是 date 的查询是升序的,和索引的顺序不匹配,这种索引就命中不到了。
多键索引
MongoDB 中的多键索引,就是一个字段是数组,MongoDB 可以针对这个字段中数组的每一个元素创建索引,这个就是多键索引。
多键索引所支持的操作和 MongoDB 其他索引支持的操作时一样的,同时多键索引也可以根据被索引的数组中的元素值域范围来选取文档。多键索引索引的数组中的元素值类型,可以是值(例如 字符串,数字等),还可以是内嵌文档。
创建多键索引
准备个测试数据
db.multikey_test.insert([
{
name: '小红',
age: 18,
tags: ['ahtml', 'bcss']
},
{
name: '小明',
age: 17,
tags: ['cjs', 'enode']
},
{
name: '小张',
age: 19,
tags: ['dvue', 'freact']
},
{
name: '小刘',
age: 19,
tags: ['go', 'java']
}
])
不创建索引的情况下,我们对 tags 字段进行查看,这时候会发生全表扫描
db.multikey_test.explain().find({'tags':{$in:['go']}})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "gleeman.multikey_test",
"indexFilterSet" : false,
"parsedQuery" : {
"tags" : {
"$eq" : "go"
}
},
"winningPlan" : {
"stage" : "COLLSCAN", // 发生了全表扫描
"filter" : {
"tags" : {
"$eq" : "go"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
...
}
对 tags 字段创建多键索引
db.multikey_test.createIndex({tags:1}, {background: true})
有了索引来分析下查询,可以很明显的发现已经命中了索引。
db.multikey_test.explain().find({'tags':{$in:['go']}})
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "gleeman.multikey_test",
"indexFilterSet" : false,
"parsedQuery" : {
"tags" : {
"$eq" : "go"
}
},
"winningPlan" : {
"stage" : "FETCH", // FETCH 根据索引检索指定的文件
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"tags" : 1
},
"indexName" : "tags_1", // 命中的索引
"isMultiKey" : true,
"multiKeyPaths" : {
"tags" : [
"tags"
]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"tags" : [
"[\"go\", \"go\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
...
}
局限性
对于复合多键索引,每次最多只能有一个数组类型的索引字段。
db.complex_multikey_test.insert([
{
name: '小红',
age: 18,
tags: ['ahtml', 'bcss'],
types: ['ahtml', 'bcss']
},
{
name: '小明',
age: 17,
tags: ['cjs', 'enode'],
types: ['ahtml', 'bcss']
}
])
对 name 字段,tags 字段和 types 字段 创建复合多键索引,因为有连个数组字段,下面的索引创建会报错。
db.complex_multikey_test.createIndex({name:1,tags:1,types:1}, {background: true})
{
"operationTime" : Timestamp(1696942298, 2),
"ok" : 0,
"errmsg" : "cannot index parallel arrays [types] [tags]",
"code" : 171,
"codeName" : "CannotIndexParallelArrays",
"$clusterTime" : {
"clusterTime" : Timestamp(1696942298, 2),
"signature" : {
"hash" : BinData(0,"hIMvBcCCO/QR45HPBaP5/oY8mlY="),
"keyId" : NumberLong("7233287468395528194")
}
}
}
哈希索引
哈希索引是一种特殊的索引类型,是将 field 的值进行 hash 计算后作为索引,主要用于等值查询,不支持范围查询,等值查询的性能非常高,能实现 o(1) 的查询性能。
注意事项
MongoDB 支持任何单个字段的 hashed 索引,但是不支持复合 hashed 索引,同时 hashed 索引也不能指定唯一键。
创建索引
准备数据
db.hashed_test.insert([
{
name: '小红',
age: 18,
tags: ['ahtml', 'bcss'],
types: ['ahtml', 'bcss']
},
{
name: '小明',
age: 17,
tags: ['cjs', 'enode'],
types: ['ahtml', 'bcss']
}
])
创建索引
db.hashed_test.createIndex({"name":"hashed"},{background: true})
总结
1、索引是数据库中用来提高查询效率的一种数据结构,索引的数据结构有很多种,MongoDB 支持的索引类型有:单键索引、复合索引、多键索引、哈希索引、全文索引、地理位置索引。
2、MongoDB 默认的存储引擎 WiredTiger 目前使用的是 B+ 树索引结构;
3、MongoDB 中的复合索引在创建的时候也遵循最左匹配和 ESR 原则;
4、复合索引中的 ESR 原则:
-
精确等值查询,字段放到最前面;
-
排序条件:字段放到中间;
-
范围查询:匹配的字段放到最后面。
参考
【MongoDB简介】https://docs.mongoing.com/mongo-introduction
【MySQL 中的索引】https://www.cnblogs.com/ricklz/p/17262747.html
【performance-best-practices-indexing】https://www.mongodb.com/blog/post/performance-best-practices-indexing
【tune_page_size_and_comp】https://source.wiredtiger.com/3.0.0/tune_page_size_and_comp.html
【equality-sort-range-rule】https://www.mongodb.com/docs/manual/tutorial/equality-sort-range-rule/
【使用索引来排序查询结果】https://mongoing.com/docs/tutorial/sort-results-with-indexes.html
【TTL 索引的原理、常见问题及解决方案】https://cloud.tencent.com/developer/article/2104290
【MongoDB 中的索引分析】https://boilingfrog.github.io/2023/10/11/mongo中的索引分析/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号