


etcd学习(10)-etcd对比Consul和zooKeeper如何选型
etcd选型对比
前言
对比 Consul, ZooKeeper。选型etcd有那些好处呢?
基本架构和原理
etcd
ETCD是一个分布式、可靠的key-value存储的分布式系统,用于存储分布式系统中的关键数据;当然,它不仅仅用于存储,还提供配置共享及服务发现;基于Go语言实现 。
etcd的特点
-
完全复制:集群中的每个节点都可以使用完整的存档
-
高可用性:Etcd可用于避免硬件的单点故障或网络问题
-
一致性:每次读取都会返回跨多主机的最新写入
-
简单:包括一个定义良好、面向用户的API(gRPC)
-
安全:实现了带有可选的客户端证书身份验证的自动化TLS
-
可靠:使用Raft算法实现了强一致、高可用的服务存储目录
etcd 是基于 raft 算法实现的,具体的实现可参见etcd实现raft源码解读
Consul
先放一张 consul 的架构图
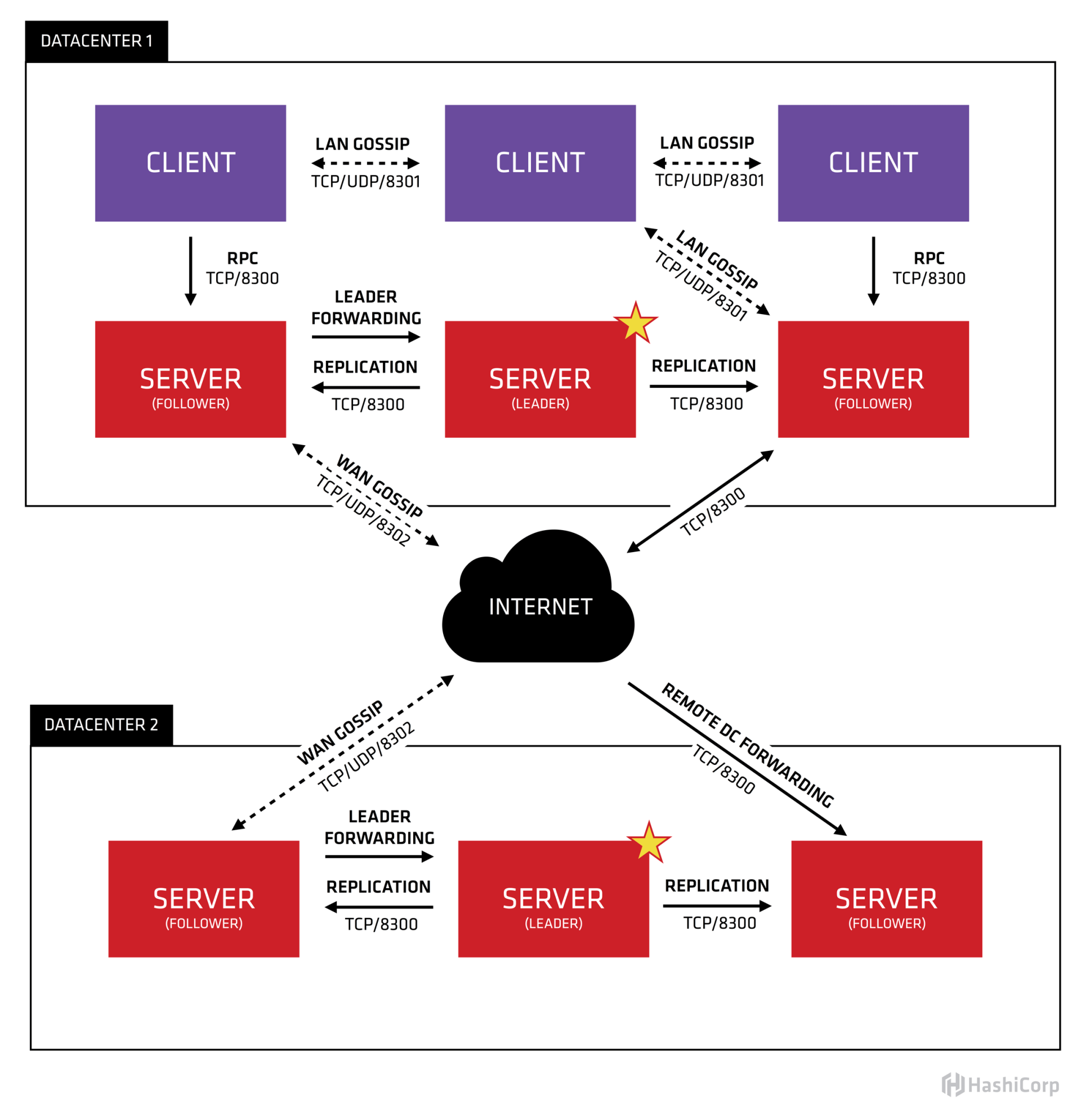
consul 使用的是 Gossip 协议
Gossip 中文名称叫流言协议,它是一种消息传播协议。它的核心思想其实源自我们生活中的八卦、闲聊。我们在日常生活中所看到的劲爆消息其实源于两类,一类是权威机构如国家新闻媒体发布的消息,另一类则是大家通过微信等社交聊天软件相互八卦,一传十,十传百的结果。
Gossip 协议的基本工作原理与我们八卦类似,在 Gossip 协议中,如下图所示,各个节点会周期性地选择一定数量节点,然后将消息同步给这些节点。收到消息后的节点同样做出类似的动作,随机的选择节点,继续扩散给其他节点。
Gossip 协议的基本工作原理与我们八卦类似,在 Gossip 协议中,如下图所示,各个节点会周期性地选择一定数量节点,然后将消息同步给这些节点。收到消息后的节点同样做出类似的动作,随机的选择节点,继续扩散给其他节点。
最终经过一定次数的扩散、传播,整个集群的各个节点都能感知到此消息,各个节点的数据趋于一致。Gossip 协议被广泛应用在多个知名项目中,比如 Redis Cluster 集群版,Apache Cassandra,AWS Dynamo。
Consul 天然支持多数据中心,但是多数据中心内的服务数据并不会跨数据中心同步,各个数据中心的 Server 集群是独立的,Consul 提供了 Prepared Query 功能,它支持根据一定的策略返回多数据中心下的最佳的服务实例地址,使你的服务具备跨数据中心容灾。
这里来看下 Prepared Query 查询的过程:
比如当你的 API 网关收到用户请求查询 A 服务,API 网关服务优先从缓存中查找 A 服务对应的最佳实例。若无缓存则向 Consul 发起一个 Prepared Query 请求查询 A 服务实例,Consul 收到请求后,优先返回本数据中心下的服务实例。如果本数据中心没有或异常则根据数据中心间 RTT 由近到远查询其它数据中心数据,最终网关可将用户请求转发给最佳的数据中心下的实例地址。
Consul 支持以下三种模式的读请求:
-
默认(default)。默认是此模式,绝大部分场景下它能保证数据的强一致性。但在老的 Leader 出现网络分区被隔离、新的 Leader 被选举出来的一个极小时间窗口内,可能会导致 stale read。这是因为 Consul 为了提高读性能,使用的是基于 Lease 机制来维持 Leader 身份,避免了与其他节点进行交互确认的开销。
-
强一致性(consistent)。强一致性读与 etcd 默认线性读模式一样,每次请求需要集群多数节点确认 Leader 身份,因此相比 default 模式读,性能会有所下降。
-
弱一致性(stale)。任何节点都可以读,无论它是否 Leader。可能读取到陈旧的数据,类似 etcd 的串行读。这种读模式不要求集群有 Leader,因此当集群不可用时,只要有节点存活,它依然可以响应读请求。
ZooKeeper
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
ZooKeeper 的有点:
-
顺序一致性: 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
-
原子性: 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
-
单一系统映像 : 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
-
可靠性: 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
再来看下 ZooKeeper 的架构图,图片摘自etcd实战课
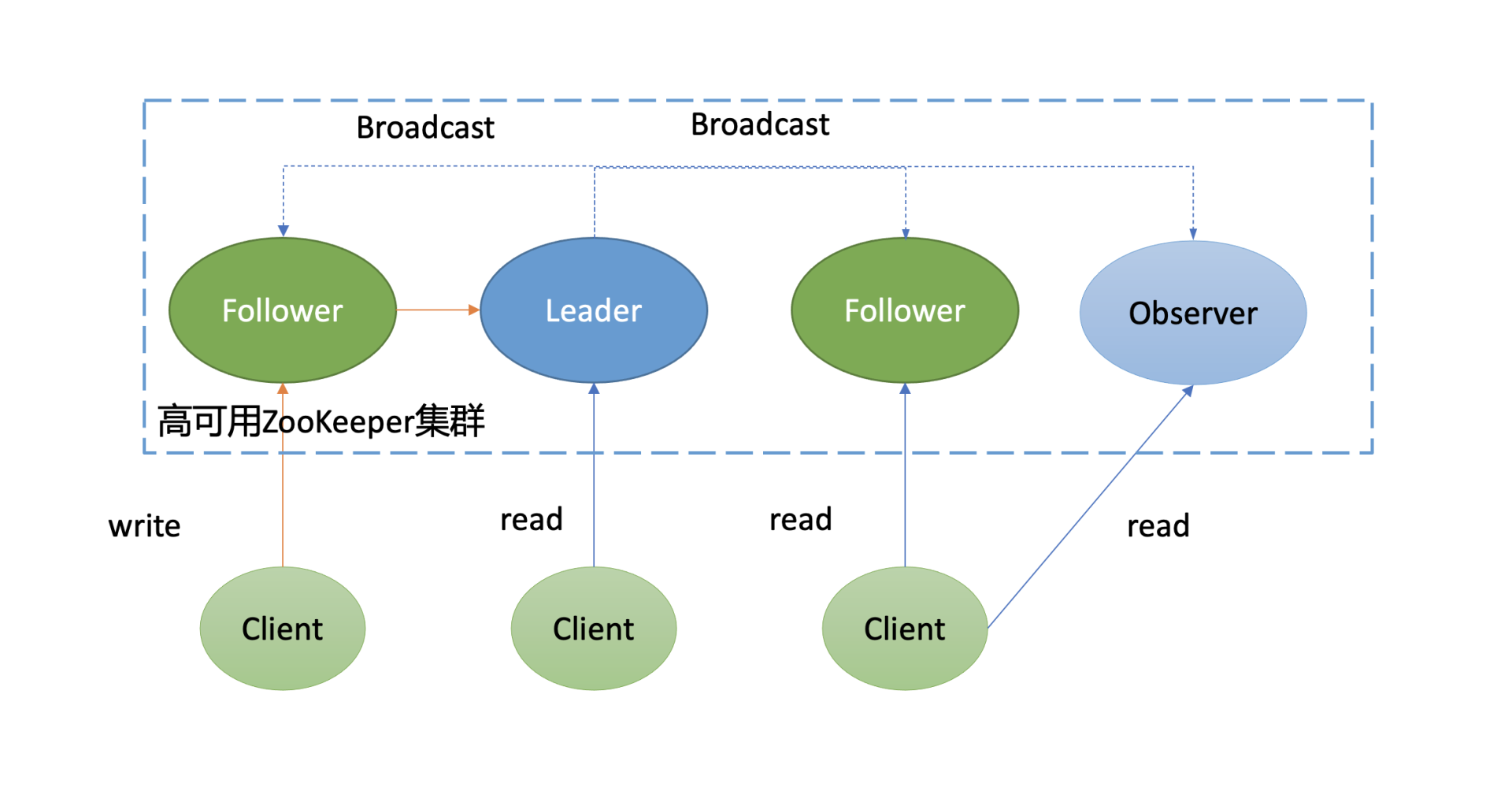
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。
除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
ZooKeeper 使用的是 Zab 协议
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
Zab 协议可以分为以下阶段:
-
Phase 0,Leader 选举(Leader Election)。一个节点只要求获得半数以上投票,就可以当选为准 Leader;
-
Phase 1,发现(Discovery)。准 Leader 收集其他节点的数据信息,并将最新的数据复制到自身;
-
Phase 2,同步(Synchronization)。准 Leader 将自身最新数据复制给其他落后的节点,并告知其他节点自己正式当选为 Leader;
-
Phase 3,广播(Broadcast)。Leader 正式对外服务,处理客户端写请求,对消息进行广播。当收到一个写请求后,它会生成 Proposal 广播给各个 Follower 节点,一半以上 Follower 节点应答之后,Leader 再发送 Commit 命令给各个 Follower,告知它们提交相关提案;
关于 ZAB 中的两种模式:崩溃恢复和消息广播
崩溃恢复
当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。
当选出 leader ,并且完成了上面 Phase 2 的同步过程,就退出崩溃恢复模式
消息广播
当准 Leader 将自身最新数据复制给其他落后的节点,并告知其他节点自己正式当选为 Leader。这时候就可以进入广播模式,当有客户端进行数据写入操作的时候,就可以通过广播模式通知所有的 follower 了。
当集群中已经有过半的Follower服务器完成了和Leader服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。
选型对比
-
1、并发原语:etcd 和 ZooKeeper 并未提供原生的分布式锁、Leader 选举支持,只提供了核心的基本数据读写、并发控制 API,由应用上层去封装,consul 就简单多了,提供了原生的支持,通过简单点命令就能使用;
-
2、服务发现:etcd 和 ZooKeeper 并未提供原生的服务发现支持,Consul 在服务发现方面做了很多解放用户双手的工作,提供了服务发现的框架,帮助你的业务快速接入,并提供了 HTTP 和 DNS 两种获取服务方式;
-
3、健康检查:consul 的健康检查机制,是一种基于 client、Gossip 协议、分布式的健康检查机制,具备低延时、可扩展的特点。业务可通过 Consul 的健康检查机制,实现 HTTP 接口返回码、内存乃至磁盘空间的检测,相比 etcd、ZooKeeper 它们提供的健康检查机制和能力就非常有限了;
etcd 提供了 Lease 机制来实现活性检测。它是一种中心化的健康检查,依赖用户不断地发送心跳续租、更新 TTL
ZooKeeper 使用的是一种名为临时节点的状态来实现健康检查。当 client 与 ZooKeeper 节点连接断掉时,ZooKeeper 就会删除此临时节点的 key-value 数据。它比基于心跳机制更复杂,也给 client 带去了更多的复杂性,所有 client 必须维持与 ZooKeeper server 的活跃连接并保持存活。
-
4、watch 特性:相比于 etcd , Consul 存储引擎是基于Radix Tree实现的,因此它不支持范围查询和监听,只支持前缀查询和监听,而 etcd 都支持, ZooKeeper 的 Watch 特性有更多的局限性,它是个一次性触发器;
-
5、线性读。etcd 和 Consul 都支持线性读,而 ZooKeeper 并不具备。
-
6、权限机制比较。etcd 实现了 RBAC 的权限校验,而 ZooKeeper 和 Consul 实现的 ACL。
-
7、事务比较。etcd 和 Consul 都提供了简易的事务能力,支持对字段进行比较,而 ZooKeeper 只提供了版本号检查能力,功能较弱。
-
8、多数据中心。在多数据中心支持上,只有 Consul 是天然支持的,虽然它本身不支持数据自动跨数据中心同步,但是它提供的服务发现机制、Prepared Query功能,赋予了业务在一个可用区后端实例故障时,可将请求转发到最近的数据中心实例。而 etcd 和 ZooKeeper 并不支持。
总结
总的看下来,consul 提供了原生的分布式锁、健康检查、服务发现机制支持,让业务可以更省心,同时也对多数据中心进行了支持;
当然 etcd 和 ZooKeeper 也都有相应的库,也能很好的进行支持,但是这两者不支持多数据中心;
ZooKeeper 在 Java 业务中选型使用的较多,etcd 因为是 go 语言开发的,所以如果本身就是 go 的技术栈,使用这个也是个不错的选择,Consul 在国外应用比较多,中文文档及实践案例相比 etcd 较少;
参考
【服务发现框架选型: Consul、Zookeeper还是etcd ?】https://www.cnblogs.com/sunsky303/p/11127324.html
【23 | 选型:etcd/ZooKeeper/Consul等我们该如何选择?】https://time.geekbang.org/column/article/351898
【服务发现比较】https://developer.aliyun.com/article/759139
【ZooKeeper讲解】https://juejin.cn/post/6844903677367418893
【ETCD对比Consul和zooKeeper如何选型】https://boilingfrog.github.io/2021/09/16/etcd对比consul和zooKeeper/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
2018-09-16 MySQL学习----unsigned 无符号的总结
2018-09-16 MySQL学习----各种字符的长度总结