
etcd学习(1)-etcd的使用场景
etcd的使用
什么是etcd
ETCD是一个分布式、可靠的key-value存储的分布式系统,用于存储分布式系统中的关键数据;当然,它不仅仅用于存储,还提供配置共享及服务发现;基于Go语言实现 。
etcd的特点
-
完全复制:集群中的每个节点都可以使用完整的存档
-
高可用性:Etcd可用于避免硬件的单点故障或网络问题
-
一致性:每次读取都会返回跨多主机的最新写入
-
简单:包括一个定义良好、面向用户的API(gRPC)
-
安全:实现了带有可选的客户端证书身份验证的自动化TLS
-
可靠:使用Raft算法实现了强一致、高可用的服务存储目录
etcd的应用场景
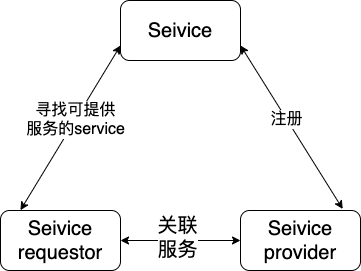
服务注册与发现
服务发现还能注册
服务注册发现解决的是分布式系统中最常见的问题之一,即在同一个分布式系统中,找到我们需要的目标服务,建立连接,然后完成整个链路的调度。
本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
1、一个强一致性、高可用的服务存储目录。基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录。
2、一种注册服务和监控服务健康状态的机制。用户可以在etcd中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。
3、一种查找和连接服务的机制。通过在 etcd 指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可以确保能访问etcd集群的服务都能互相连接。
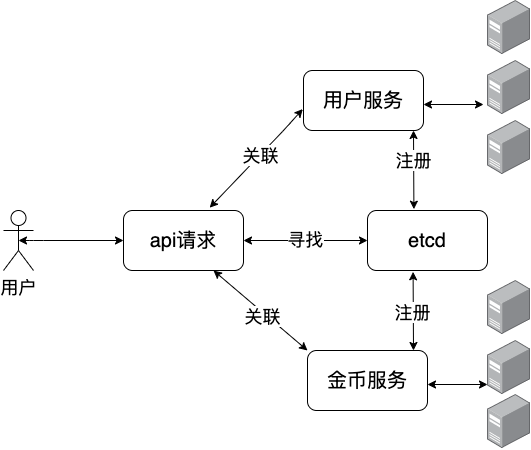
一个用户的api请求,可能调用多个微服务资源,这些服务我们可以使用etcd进行服务注册和服务发现,当每个服务启动的时候就注册到etcd中,当我们需要使用的时候,直接在etcd中寻找,调用即可。
当然,每个服务的实例不止一个,比如我们的用户服务,我们可能启动了多个实例,这些实例在服务启动过程中全部注册到了etcd中,但是某个实例可能出现故障重启,这时候就etcd在进行转发的时候,就会屏蔽到故障的实例节点,只向正常运行的实例,进行请求转发。
来看个服务注册发现的demo
这里放一段比较核心的代码,这里摘录了我们线上正在使用的etcd实现grpc服务注册和发现的实现,具体的实现可参考,etcd实现grpc的服务注册和服务发现
对于etcd中的连接,我们每个都维护一个租约,通过KeepAlive自动续保。如果租约过期则所有附加在租约上的key将过期并被删除,即所对应的服务被拿掉。
package discovery
import (
"context"
"encoding/json"
"errors"
"net/http"
"strconv"
"strings"
"time"
clientv3 "go.etcd.io/etcd/client/v3"
"go.uber.org/zap"
)
// Register for grpc server
type Register struct {
EtcdAddrs []string
DialTimeout int
closeCh chan struct{}
leasesID clientv3.LeaseID
keepAliveCh <-chan *clientv3.LeaseKeepAliveResponse
srvInfo Server
srvTTL int64
cli *clientv3.Client
logger *zap.Logger
}
// NewRegister create a register base on etcd
func NewRegister(etcdAddrs []string, logger *zap.Logger) *Register {
return &Register{
EtcdAddrs: etcdAddrs,
DialTimeout: 3,
logger: logger,
}
}
// Register a service
func (r *Register) Register(srvInfo Server, ttl int64) (chan<- struct{}, error) {
var err error
if strings.Split(srvInfo.Addr, ":")[0] == "" {
return nil, errors.New("invalid ip")
}
if r.cli, err = clientv3.New(clientv3.Config{
Endpoints: r.EtcdAddrs,
DialTimeout: time.Duration(r.DialTimeout) * time.Second,
}); err != nil {
return nil, err
}
r.srvInfo = srvInfo
r.srvTTL = ttl
if err = r.register(); err != nil {
return nil, err
}
r.closeCh = make(chan struct{})
go r.keepAlive()
return r.closeCh, nil
}
// Stop stop register
func (r *Register) Stop() {
r.closeCh <- struct{}{}
}
// register 注册节点
func (r *Register) register() error {
leaseCtx, cancel := context.WithTimeout(context.Background(), time.Duration(r.DialTimeout)*time.Second)
defer cancel()
leaseResp, err := r.cli.Grant(leaseCtx, r.srvTTL)
if err != nil {
return err
}
r.leasesID = leaseResp.ID
if r.keepAliveCh, err = r.cli.KeepAlive(context.Background(), leaseResp.ID); err != nil {
return err
}
data, err := json.Marshal(r.srvInfo)
if err != nil {
return err
}
_, err = r.cli.Put(context.Background(), BuildRegPath(r.srvInfo), string(data), clientv3.WithLease(r.leasesID))
return err
}
// unregister 删除节点
func (r *Register) unregister() error {
_, err := r.cli.Delete(context.Background(), BuildRegPath(r.srvInfo))
return err
}
// keepAlive
func (r *Register) keepAlive() {
ticker := time.NewTicker(time.Duration(r.srvTTL) * time.Second)
for {
select {
case <-r.closeCh:
if err := r.unregister(); err != nil {
r.logger.Error("unregister failed", zap.Error(err))
}
if _, err := r.cli.Revoke(context.Background(), r.leasesID); err != nil {
r.logger.Error("revoke failed", zap.Error(err))
}
return
case res := <-r.keepAliveCh:
if res == nil {
if err := r.register(); err != nil {
r.logger.Error("register failed", zap.Error(err))
}
}
case <-ticker.C:
if r.keepAliveCh == nil {
if err := r.register(); err != nil {
r.logger.Error("register failed", zap.Error(err))
}
}
}
}
}
消息发布和订阅
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新
-
应用中用到的一些配置信息放到 etcd 上进行集中管理。这类场景的使用方式通常是这样:应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
-
分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在etcd中,供各个客户端订阅使用。使用etcd的
key TTL功能可以确保机器状态是实时更新的。 -
分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用(或主题)来分配收集任务单元,因此可以在 etcd 上创建一个以应用(主题)命名的目录 P,并将这个应用(主题相关)的所有机器 ip,以子目录的形式存储到目录 P 上,然后设置一个etcd递归的Watcher,递归式的监控应用(主题)目录下所有信息的变动。这样就实现了机器 IP(消息)变动的时候,能够实时通知到收集器调整任务分配。
-
系统中信息需要动态自动获取与人工干预修改信息请求内容的情况。通常是暴露出接口,例如 JMX 接口,来获取一些运行时的信息。引入 etcd 之后,就不用自己实现一套方案了,只要将这些信息存放到指定的 etcd 目录中即可,etcd 的这些目录就可以通过 HTTP 的接口在外部访问。
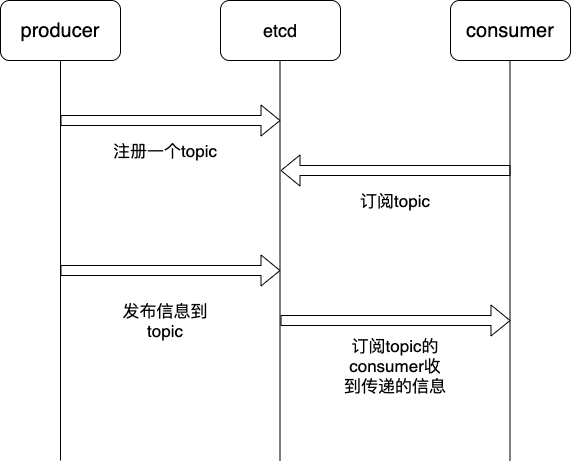
消息发布被订阅的实际应用
我们一个性能要求比较高的项目,所需要的配置信息,存放到本地的localCache中,通过etcd的消息发布和订阅实现,实现配置信息在不同节点同步更新。
来看下如何实现
func init() {
handleMap = make(map[string]func([]byte) error)
}
var handleMap map[string]func([]byte) error
func RegisterUpdateHandle(key string, f func([]byte) error) {
handleMap[key] = f
}
type PubClient interface {
Pub(ctx context.Context, key string, val string) error
}
var Pub PubClient
type PubClientImpl struct {
client *clientv3.Client
logger *zap.Logger
prefix string
}
// 监听变化,实时更新到本地的map中
func (c *PubClientImpl) Watcher() {
ctx, cancel := context.WithCancel(context.Background())
rch := c.client.Watch(ctx, c.prefix, clientv3.WithPrefix())
defer cancel()
for wresp := range rch {
for _, ev := range wresp.Events {
switch ev.Type {
case mvccpb.PUT:
c.logger.Warn("Cache Update", zap.Any("value", ev.Kv))
err := handleCacheUpdate(ev.Kv)
if err != nil {
c.logger.Error("Cache Update", zap.Error(err))
}
case mvccpb.DELETE:
c.logger.Error("Cache Delete NOT SUPPORT")
}
}
}
}
func handleCacheUpdate(val *mvccpb.KeyValue) error {
if val == nil {
return nil
}
f := handleMap[string(val.Key)]
if f != nil {
return f(val.Value)
}
return nil
}
func (c *PubClientImpl) Pub(ctx context.Context, key string, val string) error {
ctx, _ = context.WithTimeout(ctx, time.Second*10)
_, err := c.client.Put(ctx, key, val)
if err != nil {
return err
}
return nil
}
负载均衡
关于负载均衡,通常意义上有两种
-
软负载,顾名思义就是靠软件手段来实现的负载均衡。软负载也通常被称为 4层或 7 层负载!
-
硬负载,就是靠硬件实现的负载均衡,数据包转发功能。常见的就是 F5。
通过etcd实现的负载均衡就是软负载,在分布式系统中,高并发的场景下,我们通常会构建服务的集群,当某一个机器宕机了,别的机器可以马上顶替上来。
etcd中实现负载均衡,例如我们上文的例子服务注册和发现,对于一个用户服务来讲,后面的用户服务的实例可能是多个,每个都有自己的ip和port,这些服务会在项目启动的时候全部注册到etcd中,所以当使用的时候,每次etcd会轮询出一个健康的服务实例,来处理用户的请求。
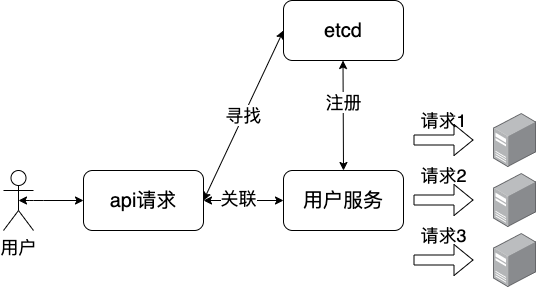
分布式通知与协调
这里说到的分布式通知与协调,与消息发布和订阅有些相似。都用到了etcd中的Watcher机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。实现方式通常是这样:不同系统都在etcd上对同一个目录进行注册,同时设置Watcher观测该目录的变化(如果对子目录的变化也有需要,可以设置递归模式),当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知,并作出相应处理。
-
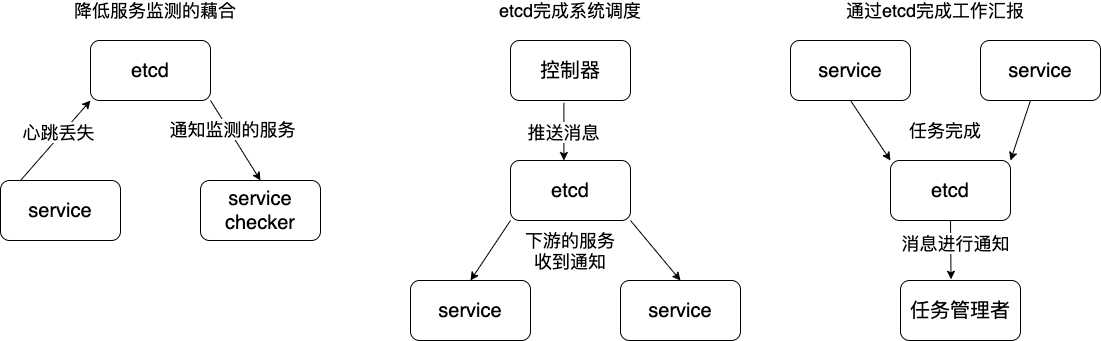
通过etcd进行低耦合的心跳检测。检测系统和被检测系统通过 etcd 上某个目录关联而非直接关联起来,这样可以大大减少系统的耦合性。
-
通过etcd完成系统调度。某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了etcd上某些目录节点的状态,而etcd就把这些变化通知给注册了Watcher的推送系统客户端,推送系统再作出相应的推送任务。
-
通过etcd完成工作汇报。大部分类似的任务分发系统,子任务启动后,到etcd来注册一个临时工作目录,并且定时将自己的进度进行汇报(将进度写入到这个临时目录),这样任务管理者就能够实时知道任务进度。
分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
首先,来看一下分布式锁应该具备哪些条件。
-
互斥性:在任意时刻,对于同一个锁,只有一个客户端能持有,从而保证一个共享资源同一时间只能被一个客户端操作;
-
安全性:即不会形成死锁,当一个客户端在持有锁的期间崩溃而没有主动解锁的情况下,其持有的锁也能够被正确释放,并保证后续其它客户端能加锁;
-
可用性:当提供锁服务的节点发生宕机等不可恢复性故障时,“热备” 节点能够接替故障的节点继续提供服务,并保证自身持有的数据与故障节点一致。
-
对称性:对于任意一个锁,其加锁和解锁必须是同一个客户端,即客户端 A 不能把客户端 B 加的锁给解了。
etcd的 Watch 机制、Lease 机制、Revision 机制和 Prefix 机制,这些机制赋予了 Etcd 实现分布式锁的能力。
- Lease 机制
即租约机制(TTL,Time To Live),Etcd 可以为存储的 Key-Value 对设置租约,当租约到期,Key-Value 将失效删除;同时也支持续约,通过客户端可以在租约到期之前续约,以避免 Key-Value 对过期失效。Lease 机制可以保证分布式锁的安全性,为锁对应的 Key 配置租约,即使锁的持有者因故障而不能主动释放锁,锁也会因租约到期而自动释放。
- Revision 机制
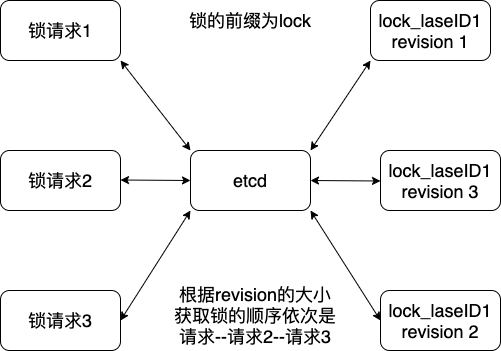
每个 Key 带有一个 Revision 号,每进行一次事务便加一,因此它是全局唯一的,如初始值为 0,进行一次 put(key, value),Key 的 Revision 变为 1,同样的操作,再进行一次,Revision 变为 2;换成 key1 进行put(key1, value)操作,Revision将变为 3;这种机制有一个作用:通过 Revision 的大小就可以知道写操作的顺序。在实现分布式锁时,多个客户端同时抢锁,根据 Revision 号大小依次获得锁,可以避免 “羊群效应” (也称“惊群效应”),实现公平锁。
- Prefix 机制
即前缀机制,也称目录机制,例如,一个名为 /mylock 的锁,两个争抢它的客户端进行写操作,实际写入的Key分别为:key1="/mylock/UUID1",key2="/mylock/UUID2",其中,UUID表示全局唯一的ID,确保两个Key的唯一性。很显然,写操作都会成功,但返回的Revision不一样,那么,如何判断谁获得了锁呢?通过前缀“/mylock”查询,返回包含两个Key-Value对的Key-Value列表,同时也包含它们的Revision,通过Revision大小,客户端可以判断自己是否获得锁,如果抢锁失败,则等待锁释放(对应的 Key 被删除或者租约过期),然后再判断自己是否可以获得锁。
- Watch 机制
即监听机制,Watch机制支持监听某个固定的Key,也支持监听一个范围(前缀机制),当被监听的Key或范围发生变化,客户端将收到通知;在实现分布式锁时,如果抢锁失败,可通过Prefix机制返回的Key-Value列表获得Revision比自己小且相差最小的 Key(称为 Pre-Key),对Pre-Key进行监听,因为只有它释放锁,自己才能获得锁,如果监听到Pre-Key的DELETE事件,则说明Pre-Key已经释放,自己已经持有锁。
来看下etcd中锁是如何实现的
client/v3/concurrency/mutex.go
// Mutex implements the sync Locker interface with etcd
type Mutex struct {
s *Session
pfx string // 前缀
myKey string // key
myRev int64 // 自增的Revision
hdr *pb.ResponseHeader
}
// Lock 使用可取消的context锁定互斥锁。如果context被取消
// 在尝试获取锁时,互斥锁会尝试清除其过时的锁条目。
func (m *Mutex) Lock(ctx context.Context) error {
resp, err := m.tryAcquire(ctx)
if err != nil {
return err
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
client := m.s.Client()
// waitDeletes 有效地等待,直到所有键匹配前缀且不大于
// 创建的version。
_, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
// release lock key if wait failed
if werr != nil {
m.Unlock(client.Ctx())
return werr
}
// make sure the session is not expired, and the owner key still exists.
gresp, werr := client.Get(ctx, m.myKey)
if werr != nil {
m.Unlock(client.Ctx())
return werr
}
if len(gresp.Kvs) == 0 { // is the session key lost?
return ErrSessionExpired
}
m.hdr = gresp.Header
return nil
}
func (m *Mutex) tryAcquire(ctx context.Context) (*v3.TxnResponse, error) {
s := m.s
client := m.s.Client()
// s.Lease()租约
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
// 比较Revision, 这里构建了一个比较表达式
// 具体的比较逻辑在下面的client.Txn用到
// 如果等于0,写入当前的key,并设置租约,
// 否则获取这个key,重用租约中的锁(这里主要目的是在于重入)
// 通过第二次获取锁,判断锁是否存在来支持重入
// 所以只要租约一致,那么是可以重入的.
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// 通过 myKey 将自己锁在waiters;最早的waiters将获得锁
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// 获取已经拿到锁的key的信息
get := v3.OpGet(m.myKey)
// 仅使用一个 RPC 获取当前持有者以完成无竞争路径
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
// 这里是比较的逻辑,如果等于0,写入当前的key,否则则读取这个key
// 大佬的代码写的就是奇妙
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return nil, err
}
// 根据比较操作的结果写入Revision到m.myRev中
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
return resp, nil
}
// 抽象出了一个session对象来持续保持租约不过期
func NewSession(client *v3.Client, opts ...SessionOption) (*Session, error) {
...
ctx, cancel := context.WithCancel(ops.ctx)
// 保证锁,在线程的活动期间,实现锁的的续租
keepAlive, err := client.KeepAlive(ctx, id)
if err != nil || keepAlive == nil {
cancel()
return nil, err
}
...
return s, nil
}
设计思路:
1、多个请求来前抢占锁,通过Revision来判断锁的先后顺序;
2、如果有比当前key的Revision小的Revision存在,说明有key已经获得了锁;
3、等待直到前面的key被删除,然后自己就获得了锁。
通过etcd实现的锁,直接包含了锁的续租,如果使用Redis还要自己去实现,相比较使用更简单。
来实现一个etcd的锁
package main
import (
"context"
"fmt"
"log"
"time"
clientv3 "go.etcd.io/etcd/client/v3"
"go.etcd.io/etcd/client/v3/concurrency"
)
func main() {
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
ctx := context.Background()
// m1来抢锁
go func() {
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
m1 := concurrency.NewMutex(s1, "/my-lock/")
// acquire lock for s1
if err := m1.Lock(ctx); err != nil {
log.Fatal(err)
}
fmt.Println("m1---获得了锁")
time.Sleep(time.Second * 3)
// 释放锁
if err := m1.Unlock(ctx); err != nil {
log.Fatal(err)
}
fmt.Println("m1++释放了锁")
}()
// m2来抢锁
go func() {
s2, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s2.Close()
m2 := concurrency.NewMutex(s2, "/my-lock/")
if err := m2.Lock(ctx); err != nil {
log.Fatal(err)
}
fmt.Println("m2---获得了锁")
// mock业务执行的时间
time.Sleep(time.Second * 3)
// 释放锁
if err := m2.Unlock(ctx); err != nil {
log.Fatal(err)
}
fmt.Println("m2++释放了锁")
}()
time.Sleep(time.Second * 10)
}
打印下输出
m2---获得了锁
m2++释放了锁
m1---获得了锁
m1++释放了锁
分布式队列
即创建一个先进先出的队列保持顺序。另一种比较有意思的实现是在保证队列达到某个条件时再统一按顺序执行。这种方法的实现可以在/queue这个目录中另外建立一个/queue/condition节点。
-
condition 可以表示队列大小。比如一个大的任务需要很多小任务就绪的情况下才能执行,每次有一个小任务就绪,就给这个 condition 数字加 1,直到达到大任务规定的数字,再开始执行队列里的一系列小任务,最终执行大任务。
-
condition 可以表示某个任务在不在队列。这个任务可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常,必须执行这些任务后才能执行队列中的其他任务。
-
condition 还可以表示其它的一类开始执行任务的通知。可以由控制程序指定,当 condition 出现变化时,开始执行队列任务。
来看下实现
入队
func newUniqueKV(kv v3.KV, prefix string, val string) (*RemoteKV, error) {
for {
newKey := fmt.Sprintf("%s/%v", prefix, time.Now().UnixNano())
// 创建对应的key
rev, err := putNewKV(kv, newKey, val, v3.NoLease)
if err == nil {
return &RemoteKV{kv, newKey, rev, val}, nil
}
// 如果之前已经创建了,就返回
if err != ErrKeyExists {
return nil, err
}
}
}
// 只有在没有创建的时候才能创建成功
func putNewKV(kv v3.KV, key, val string, leaseID v3.LeaseID) (int64, error) {
cmp := v3.Compare(v3.Version(key), "=", 0)
req := v3.OpPut(key, val, v3.WithLease(leaseID))
// 这里还用到了这种比较的逻辑
txnresp, err := kv.Txn(context.TODO()).If(cmp).Then(req).Commit()
if err != nil {
return 0, err
}
// 已经存在则返回错误
if !txnresp.Succeeded {
return 0, ErrKeyExists
}
return txnresp.Header.Revision, nil
}
出队
// Dequeue处理的是一个先进新出的队列
// 如果队列为空,Dequeue将会阻塞直到里面有值塞入
func (q *Queue) Dequeue() (string, error) {
resp, err := q.client.Get(q.ctx, q.keyPrefix, v3.WithFirstRev()...)
if err != nil {
return "", err
}
kv, err := claimFirstKey(q.client, resp.Kvs)
if err != nil {
return "", err
} else if kv != nil {
return string(kv.Value), nil
// more 表示在请求的范围内是否还有更多的键要返回。
// 则进行Dequeue重试
} else if resp.More {
// missed some items, retry to read in more
return q.Dequeue()
}
// nothing yet; wait on elements
ev, err := WaitPrefixEvents(
q.client,
q.keyPrefix,
resp.Header.Revision,
[]mvccpb.Event_EventType{mvccpb.PUT})
if err != nil {
return "", err
}
ok, err := deleteRevKey(q.client, string(ev.Kv.Key), ev.Kv.ModRevision)
if err != nil {
return "", err
} else if !ok {
// 如果删除失败,重试
return q.Dequeue()
}
return string(ev.Kv.Value), err
}
总结
1、这里的入队是一个先进新出的队列;
2、出队的实现也很简单,如果队列为空,Dequeue将会阻塞直到里面有值塞入;
来个demo
package main
import (
"fmt"
"log"
"time"
clientv3 "go.etcd.io/etcd/client/v3"
recipe "go.etcd.io/etcd/client/v3/experimental/recipes"
)
func main() {
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
})
if err != nil {
log.Fatalf("error New (%v)", err)
}
go func() {
q := recipe.NewQueue(cli, "testq")
for i := 0; i < 5; i++ {
if err := q.Enqueue(fmt.Sprintf("%d", i)); err != nil {
log.Fatalf("error enqueuing (%v)", err)
}
}
}()
go func() {
q := recipe.NewQueue(cli, "testq")
for i := 10; i < 100; i++ {
if err := q.Enqueue(fmt.Sprintf("%d", i)); err != nil {
log.Fatalf("error enqueuing (%v)", err)
}
}
}()
q := recipe.NewQueue(cli, "testq")
for i := 0; i < 100; i++ {
s, err := q.Dequeue()
if err != nil {
log.Fatalf("error dequeueing (%v)", err)
}
fmt.Println(s)
}
time.Sleep(time.Second * 3)
}
集群监控与Leader竞选
通过etcd来进行监控实现起来非常简单并且实时性强
1、前面几个场景已经提到Watcher机制,当某个节点消失或有变动时,Watcher会第一时间发现并告知用户。
2、节点可以设置TTL key,比如每隔 30s 发送一次心跳使代表该机器存活的节点继续存在,否则节点消失。
这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求
另外,使用分布式锁,可以完成Leader竞选。这种场景通常是一些长时间CPU计算或者使用IO操作的机器,只需要竞选出的Leader计算或处理一次,就可以把结果复制给其他的Follower。从而避免重复劳动,节省计算资源。
这个的经典场景是搜索系统中建立全量索引。如果每个机器都进行一遍索引的建立,不但耗时而且建立索引的一致性不能保证。通过在etcd的CAS机制同时创建一个节点,创建成功的机器作为Leader,进行索引计算,然后把计算结果分发到其它节点。

参考
【一文入门ETCD】https://juejin.cn/post/6844904031186321416
【etcd:从应用场景到实现原理的全方位解读】https://www.infoq.cn/article/etcd-interpretation-application-scenario-implement-principle
【Etcd 架构与实现解析】http://jolestar.com/etcd-architecture/
【linux单节点和集群的etcd】https://www.jianshu.com/p/07ca88b6ff67
【软负载均衡与硬负载均衡、4层与7层负载均衡】https://cloud.tencent.com/developer/article/1446391
【Etcd Lock详解】https://tangxusc.github.io/blog/2019/05/etcd-lock详解/
【etcd基础与使用】https://zhuyasen.com/post/etcd.html
【ETCD核心机制解析】https://www.cnblogs.com/FG123/p/13632095.html
【etcd watch机制】http://liangjf.top/2019/12/31/110.etcd-watch机制分析/
【ETCD 源码学习--Watch(server)】https://www.codeleading.com/article/15455457381/
【etcdV3—watcher服务端源码解析】https://blog.csdn.net/stayfoolish_yj/article/details/104497233

 浙公网安备 33010602011771号
浙公网安备 33010602011771号