

简单排序之希尔排序
插入排序相比于冒泡排序(串行)是有所增进的,但仍然有待改进,当然效率优劣,有时候还是需要取决于需要排序的数据源。所以不能说一种排序算法一定是绝对优于另一种,总所周知,一般优劣都是效率和内存综合比较,有时候还设计并发安全的考虑。
插入排序从一开始设定的对比密度就是一定的,而且是最精密的,这样子可能会导致对比和交换的频率会很高。而希尔排序最主要的一个优点是,即使一个较小的元素在数组的末尾,由于每次元素移动都以h(希尔增量)为间隔进行,因此数组末尾的小元素可以在很少的交换次数下,就被置换到最接近元素最终位置的地方。
定义:
将整个数组根据间隔h分隔为若干个子数组,它们相互穿插在一起,每一次排序时,分别对每一个子数组进行排序。
理解:
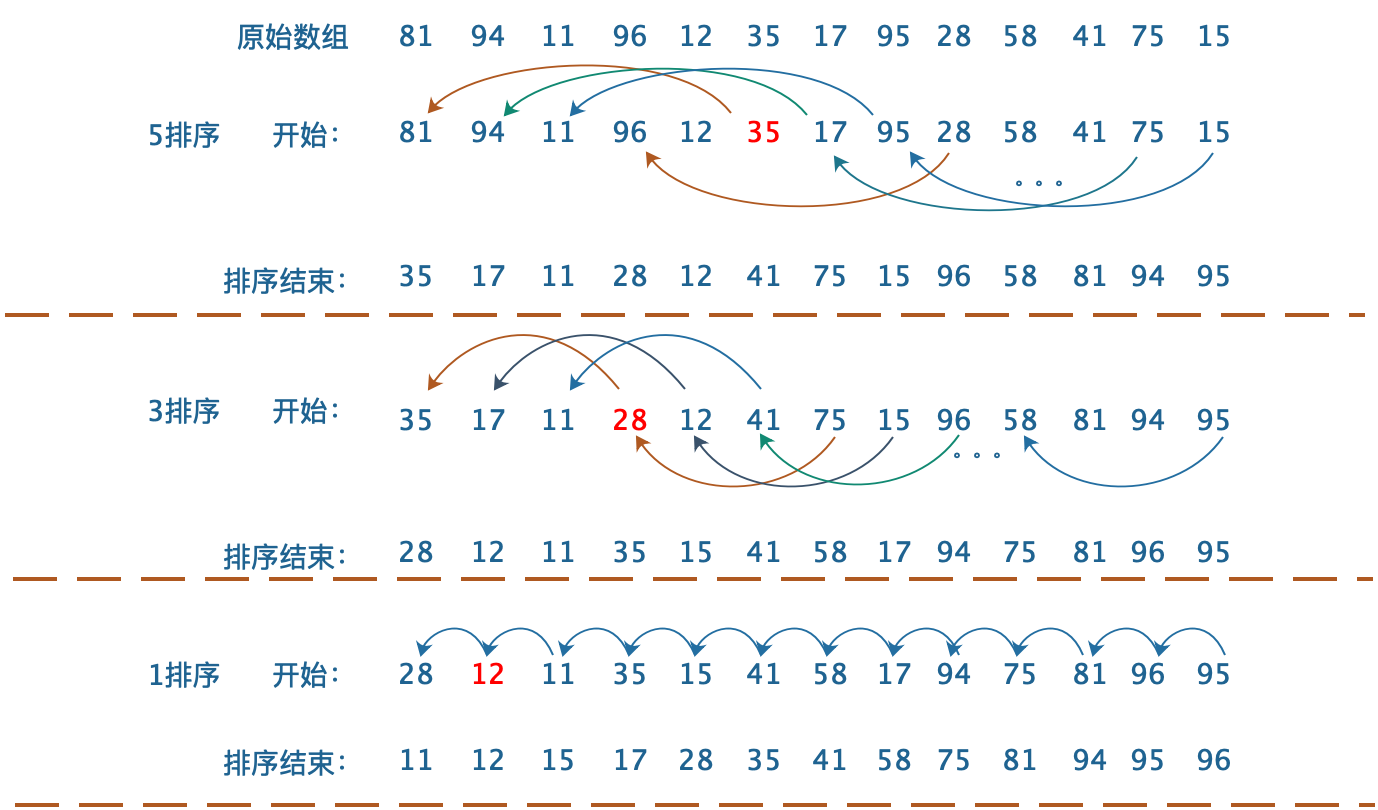
这里最重要的是h,简单的讲是跨度,专业术语可以称为希尔增量。例子:比如h=3,就会将数组的数据分为arr[0],arr[3],arr[6]…… 归类为一个子数组进行比较 同理 arr[1],arr[4],arr[7]……也会组成一个子数组,这样子完整的数组就被拆分成了在原数组上不连续下标组成的子数组。这里说明一下,这个h(希尔增量)没有唯一的值代表它是最优的,这需要取决于需要排序的数据源的规律性。
例图(摘抄自https://www.cnblogs.com/dhcao/p/10704131.html):
代码实现:
1 /** 2 * 串行希尔排序 3 * @param arr 4 */ 5 public static void shellSort(int [] arr){ 6 int h =1; 7 if(h<arr.length/3){ 8 h=h*3+1;//希尔最大增量 就是每隔需要插入的值与前面/后面 间隔h距离的值比较 9 // 比如数组长度为12 则计算h=4 数据长度为120 计算h=40 10 //比较就会拿第i和第i+h第i+2h第i+3h下标的值进行对比 这些下标的值成一组进行比较 11 12 } 13 while(h>0){ 14 for (int i = h; i <arr.length ; i++) { //插入排序开始 15 if(arr[i]<arr[i-h]){ 16 int tmp=arr[i]; 17 int j =i-h; 18 while(j>=0&&arr[j]>tmp){ 19 arr[j+h]=arr[j]; 20 j-=h; 21 } 22 arr[j+h]=tmp; 23 } 24 }//插入排序结束 25 h=(h-1)/3;//计算下一个间隔区间h(希尔增量),会逐渐缩小,必有一个增量为1 相当于一次插入排序 26 } 27 }
代码说明:
上面的代码很显然是串行执行的,但由于数据的确定性,互相比较的和排序的数据是对应的子数组,所以可以利用并发工具类改进为并行的希尔排序,待续……
