
ElasticSearch(一)ElasticSearch基础概念一篇过
一、简单介绍
什么是ElasticSearch?
定义:用Java开发并且是当前最流行的开源的企业级搜索引擎。
优势:实时搜索,稳定,可靠,快速,安装使用方便。
应用场景?
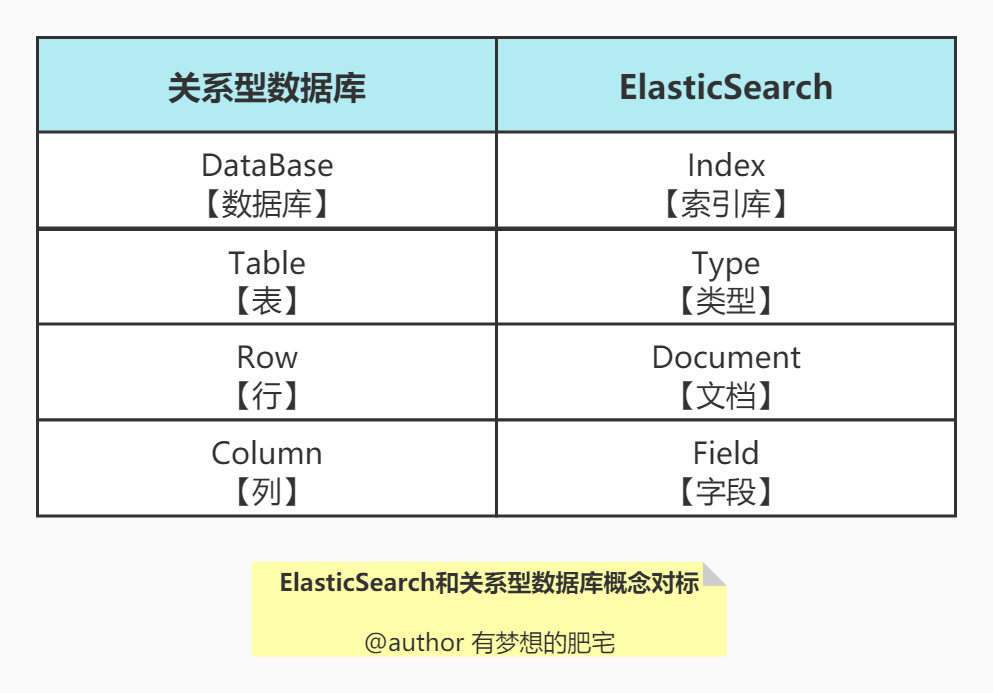
概念对标
什么是全文检索
全文检索是指:
- 通过程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数。
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
倒排索引
直接上图比较~

二、核心名词解释
索引 index
定义:归为一类的文档的集合。
举个🌰:可以有一个客户数据的索引,一个产品目录的索引,还有一个订单数据的索引等等。
映射 mapping
定义:处理数据的方式和规则的一些限制。
举个🌰:比如如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的。

PS:先有一个印象,后面会去使用的~【有梦想的肥宅】
{
"properties": { //表示设置映射关系【有梦想的肥宅】
"name": {
"type": "keyword", //keyword:关键字,不能分词,必须完全匹配
"index": true //表示此字段可以进行索引查询
},
"sex": {
"type": "text",//text:文本,可以分词
"index": true
},
"phone": {
"type": "text",
"index": false //表示此字段不能进行索引查询,如果查询时带上这个字段会报错【没有被索引,不能被查询】
}
}
}
字段 field
定义:相当于是数据表的字段/列。
字段类型 type
定义:标识字段的类型。
举个🌰:Text、Keyword、Byte等。
文档 document
定义:一个可被索引的基础信息单元,类似关系型数据库里的一条记录。
PS:文档以JSON格式来表示。
集群 cluster
定义:一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能,提高系统可用性。
节点 node
定义:一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
PS:节点创建时默认加入一个叫做elasticsearch的集群。
分片 shards
产生背景:单个节点无法存储巨量数据,且响应时间长。
定义:将索引划分成多份,每一份就叫分片,其本身也是一个功能完善并且独立的索引,可以被放置到集群中的任何节点上。
作用:
- (1)允许水平分割、扩展数据的存储容量,分担请求压力。
- (2)允许在分片之上进行分布式的、并行的操作,进而提高性能和吞吐量。
- (3)用户无感知的情况下扩展了系统性能。
副本 replicas
产生背景:单点故障时需要进行灾备。
定义:分片的一份或多份拷贝,这些拷贝叫做副本分片,或者直接叫副本。
PS:副本与原分片是不能位于同一个节点上的!!!
PS:在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量。
作用:
- (1)防止单点故障,灾备提高了系统可用性。
- (2)扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
三、扩展知识
核心端口
- 9200:服务端口,用于远程链接
- 9300:集群间通信端口


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律