
Zookeeper(七)Zookeeper集群角色及选举原理分析
一、集群角色解析
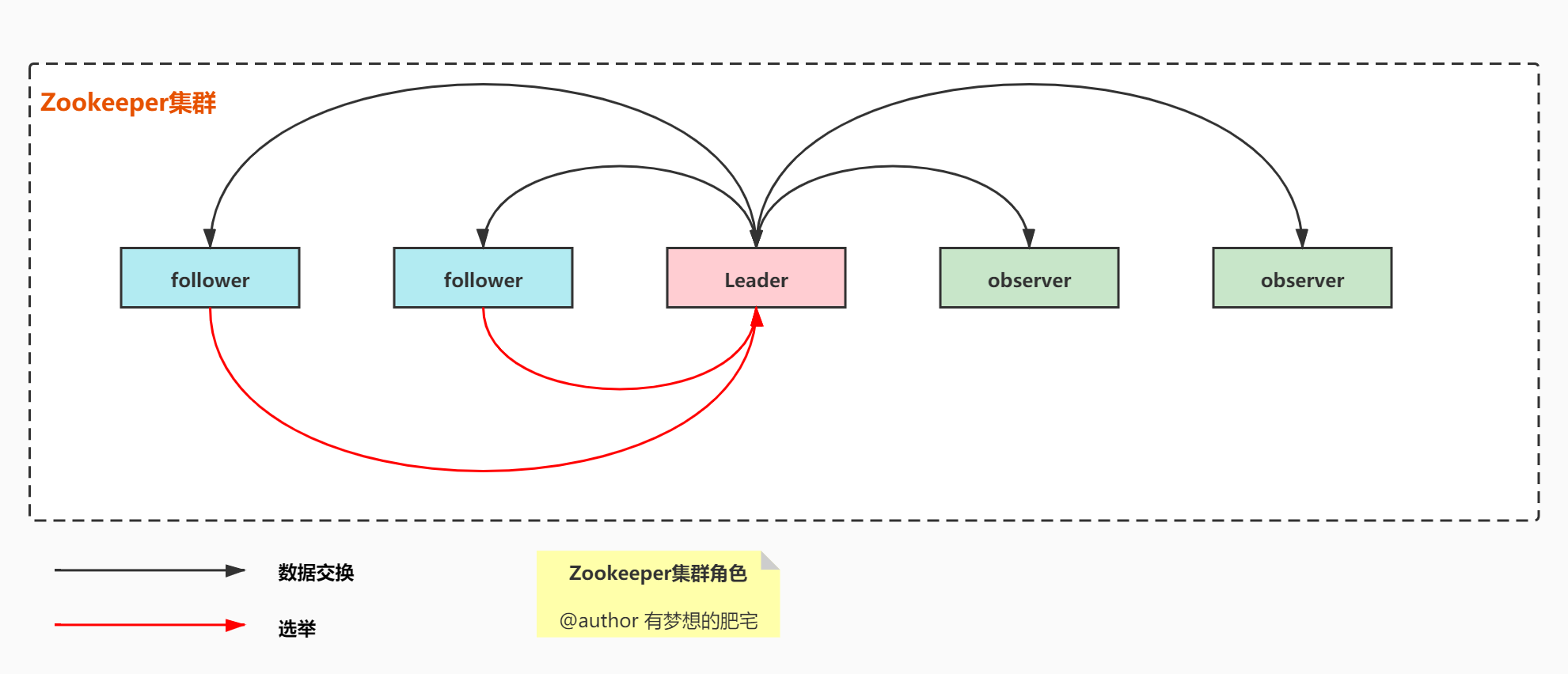
Leader【领导者】
主要工作:
- 处理写请求和读请求
- 发表集群事务【写请求同步ACK】
- 协调集群内部服务
是否参与选举:是
Follower【跟随者】
主要工作:
- 处理非事务请求【读请求】,转发事务请求【写请求】给Leader服务器
- 参与集群事务过半投票【写请求ACK】
- 选举Leader时进行投票
是否参与选举:是
Observer【观察者】
主要工作:
- 提升非事务请求【读请求】的性能,转发事务请求【写请求】给Leader服务器,可以响应读请求
- 不参与投票选举,也不参与集群事务过半投票【写请求ACK】
- 动态扩展zookeeper集群,而又不影响集群的性能【因为观察者节点不参与投票,即使是观察者节点宕机了,对集群的运行状态没有影响】
是否参与选举:否
PS:当ZooKeeper集群中follower的数量很多时,投票过程会成为一个性能瓶颈,Observer主要就是为了解决投票造成的压力。
二、选举流程简析
Leader election(选举阶段)
节点在一开始都处于选举阶段,只要有一个节点得到超过半数节点的票数,它就可以当选准Leader。
Discovery(发现阶段)
在这个阶段,Followers跟准Leader进行通信,同步Followers最近接收的事务提议。
Synchronization(同步阶段)
同步阶段主要是利用Leader前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准Leader才会成为真正的Leader。
Broadcast(广播阶段)
到了这个阶段,Zookeeper集群才能正式对外提供事务服务,并且Leader可以进行消息广播,响应客户端的读写请求并同步数据。同时如果有新的节点加入,还需要对新节点进行同步。
三、集群如何处理写请求?【消息广播流程】
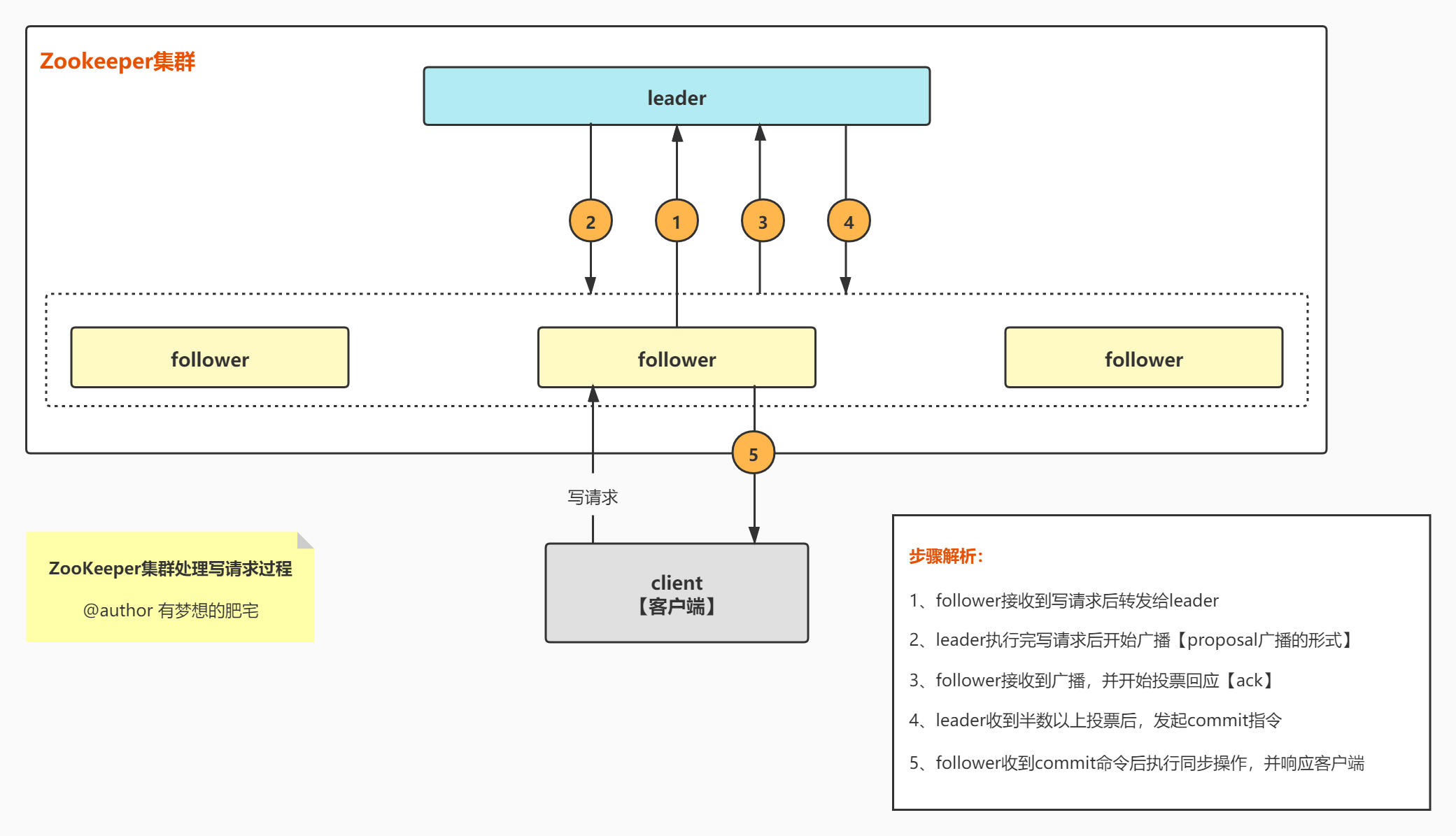
处理过程如下:
- 1、收到写请求的follower,将写请求发送给leader。
- 2、leader收到来自follower(或observer)的写请求后,首先计算这次写操作之后的状态,然后将这个写请求转换成带有各种状态的事务(如版本号、zxid等等)。
- 3、leader将这个事务以提议的方式广播出去(即发送proposal)。
- 4、所有follower收到proposal后,对这个提议进行投票,投票完成后返回ack给leader。follower的投票只有两种方式:(1)确认这次提议表示同意(2)丢弃这次提议表示不同意。
- 5、leader收集投票结果,只要投票数量超过半数,这次提议就通过。
- 6、提议通过后,leader向所有server发送一个提交通知。
- 7、所有节点将这次事务写入事务日志,并进行提交。
- 8、提交后,收到写请求的那个server向客户端返回成功信息。
四、选举流程详细分析【leader选举和崩溃恢复流程】
第一次启动
- (1)服务器1启动并发起一次选举。服务器1投自己一票,此时服务器1票数一票,不够半数以上(3票),则选举无法完成,服务器1状态保持为LOOKING。
- (2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息
- 服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。
- 此时服务器1票数0票,服务器2票数2票,没有超过半数,选举无法完成,服务器1,2状态保持LOOKING。
- (3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。
- 服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。
- 服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING。
- (4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。
- 服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING。
- (5)服务器5启动,同4一样更新状态为FOLLOWING。
非第一次启动
- (1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
- 服务器初始化启动。
- 服务器运行期间无法和Leader保持连接。
- (2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
- 集群中本来就已经存在一个Leader【由于网络波动导致的暂时失联,重选leader的场景】。
- 对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。
- (3)集群中确实不存在Leader,则遵循以下原则进行选举:
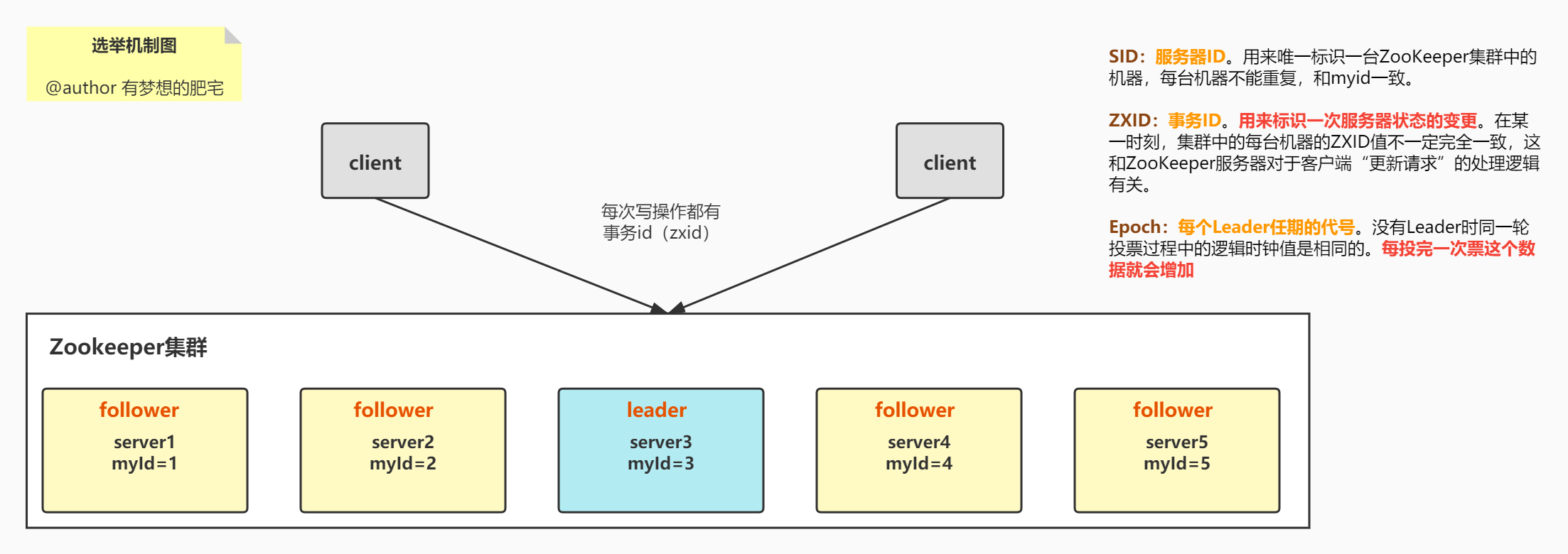
- 1️⃣EPOCH大的直接胜出
- 2️⃣EPOCH相同,事务id大的胜出
- 3️⃣事务id相同,服务器id大的胜出
举个🌰
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
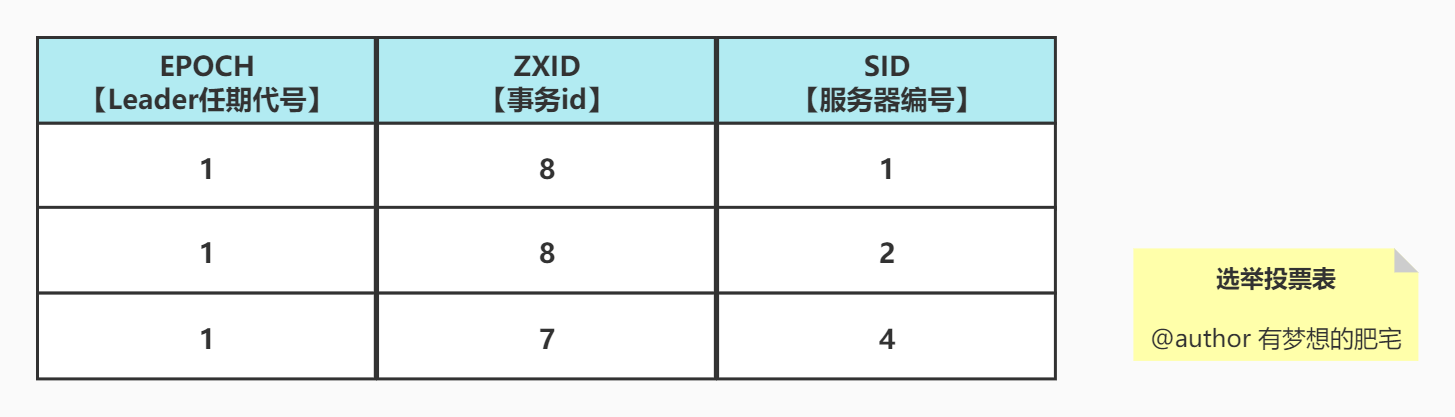
根据投票表结合上面的结论,我们可以知道此时2号服务器上位成为leader~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2019-08-23 Java Web学习(五)session、cookie、token