
Java基础一篇过(五)Map这篇就够了
文章更新时间:2020/09/27
一、Map介绍
Map是Java的一个接口,没有继承,以Key--Value的形式来储存元素信息,常用到的有3个子类实现:
- HashMap
- 底层数据结构是散列桶(数组和链表和红黑树)。线程不安全【JDK1.8版本】
- TreeMap
- 底层数据结构是红黑树。线程不安全
- HashTable
- 底层数据结构是散列桶(数组和单链表)。线程安全
- ConcurrentHashMap
- 底层数据结构是数组+链表+红黑树。线程安全,效率比HashTable更高。
下面就这几个常用子类进行分析学习。
二、HashMap
HashMap位于java.util包下
底层实现:散列桶(数组、链表和红黑树)
特点:
- 数据无序(增删改查访问都很快)
- 键和值均允许为null
- 非同步底层由散列表(哈希表)实现
- 需要设置好初始容量和装载因子才可以发挥最大性能
属性

内部类

底层数据结构说明
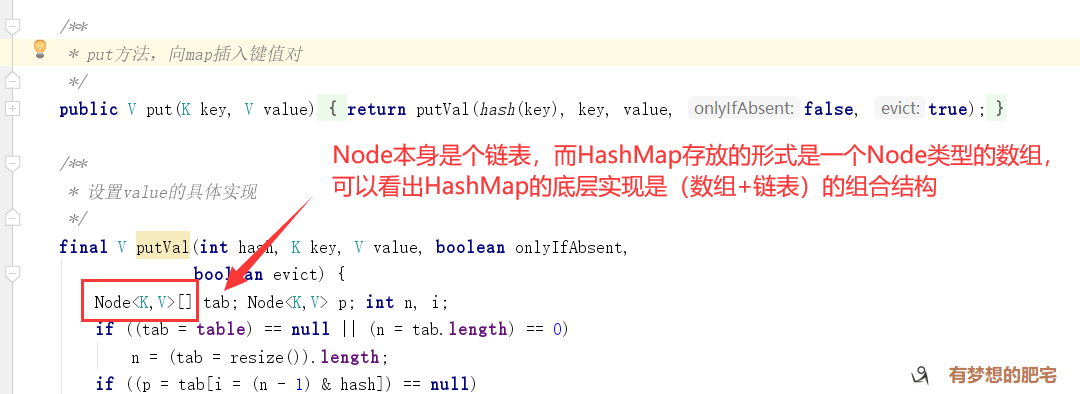
主要方法解析
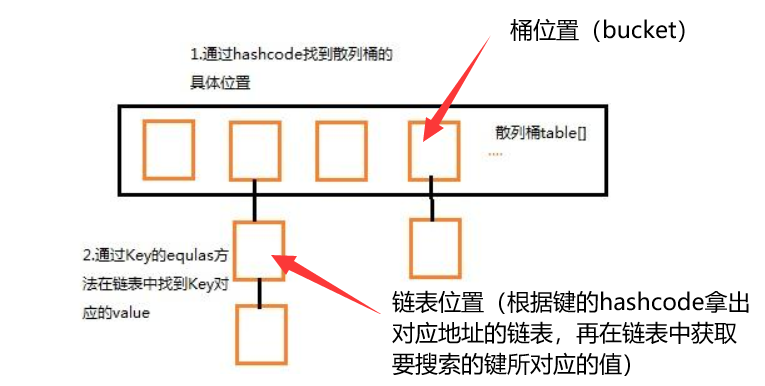
get()
- 找键的hash地址 :使用键对象的hashcode找到bucket(桶)位置
- 比较键 : 调用keys.equals()方法找到链表中正确的节点,获取值
put()
- 对Key求Hash值,然后再计算下标
- 如果没有碰撞,直接放入桶中(碰撞的意思是计算得到的Hash值相同,需要放到同一个bucket中)
- 如果碰撞了,以链表的方式链接到后面
- 如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树,链表长度低于6,就把红黑树转回链表
- 如果节点已经存在就替换旧值
- 如果桶满了(容量16*加载因子0.75),就需要 resize(扩容2倍后重排)
PS : 桶即HashMap初始化时的(Node[] table=new Node[16])数组。
小结
- 结构:数组内装链表或者红黑树
- 当线性链表深度大于8时,查询效率会降低,所以1.8以后加入了红黑树,当链表深度超过转换阈值8时,将链表转换为红黑树以提升查询效率
- 外层数组容量达到0.75时会进行扩容,每次扩容后的容量为原来的2倍
- 在调用resize()方法时会对原数据进行rehash,此时结构重排,也就出现了红黑树向链表转换的阈值6
三、TreeMap
TreeMap位于java.util包下
底层实现:红黑树(平衡的二叉搜索树)
特点:
- 数据有序
- 比HashMap多实现了了NavigableMap接口,使得键有序
- 能根据比较器对键做大小排序
- 非同步,线程不安全
红黑树的特性:
- (1)树的节点只有红与黑两种颜色。
- (2)红色节点的子节点必定是黑色的。
- (3)根节点为黑色的。
- (4)叶子节点(NIL节点,即空节点)为黑色的。
- (5)从任意节点出发,到其后继的叶子节点的路径中,黑色节点的数目相同。
PS:以上5大特性使得红黑树的根节点到叶子节点的最长路径不会大于最短路径的2倍。
红黑树动态图解可戳这里~
NavigableMap接口
TreeMap之所以能够实现有序的数据结构,主要原因就是实现了NavigableMap接口,下面借用大佬的一张图来清晰的展示NavigableMap接口的特点:

TreeMap数据结构
TreeMap储存键值对的单位为一个一个的Entey()对象 ,Entry作为TreeMap存储的结点,包括键、值、父结点、左孩子、右孩子、颜色。源码如下所示:
static final class Entry<K, V> implements Map.Entry<K, V> { K key;//节点的键 V value;//节点的值 TreeMap.Entry<K, V> left;//左子节点(左孩子) TreeMap.Entry<K, V> right;//右子节点(右孩子) TreeMap.Entry<K, V> parent;//父节点 boolean color = BLACK;//节点颜色:默认黑色 }
构造方法
TreeMap有四种构造函数,,由不同的入参指定:

//比较器 private final Comparator<? super K> comparator; //1.键自然顺序 public TreeMap() { comparator = null; } //2.根据给定的比较器进行排序 public TreeMap(Comparator<? super K> comparator) { this.comparator = comparator; } //3.构造一个与给定映射具有相同映射关系的新的树映射,该映射根据其键的自然顺序进行排序 public TreeMap(Map<? extends K, ? extends V> m) { comparator = null; // putAll()将m中的所有元素添加到TreeMap中 putAll(m); } //4.构造一个与指定有序映射具有相同映射关系和相同排序顺序的新的树映射 public TreeMap(SortedMap<K, ? extends V> m) { comparator = m.comparator(); try { // buildFromSorted将m中的所有元素按同样的排序方式添加到TreeMap中 buildFromSorted(m.size(), m.entrySet().iterator(), null, null); } catch (Exception e) { } }
主要方法解析
put()
- (1)获取TreeMap的比较器(Comparator)
- (2)根据比较器规则比较插入的节点,相等时则覆盖,不等时准备下一步工作【没定义比较器时按默认的方式排序】
- (3)比较树内已存在的节点,并进行节点插入
- (4)插入节点后检查并修复树【对增节点后的树进行左旋,右旋,变色等操作】,保持平衡
PS:使用TreeMap时,键必须实现Comparable接口或者构造时传入比较器,若键中存在null值得情况,可以在自定义的比较器中设置null值的处理情况【默认情况下TreeMap是不支持传入null键的】
get()
- 判断TreeMap存不存在传入的自定应比较器
- 若存在比较器时,按比较器的规则进行节点查找
- 若没有自定义比较器时,则按普通二叉排序树的查找规则来搜索树节点
remove()
- (1)根据key找到待删除的结点
- (2)删除节点,并修复红黑树
与HashMap的异同
TreeMap和HashMap的相同点
- 两者均是线程不安全的。
- 两者插入节点时,key重复均覆盖旧值。
TreeMap和HashMap的不同点
- HashMap的实现基于数组和链表,而TreeMap的实现基于红黑树。
- HashMap的key是无序的,TreeMap的key是有序的。
- TreeMap要求key必须实现Comparable接口,或者初始化时传入Comparator比较器。
- HashMap增删改查操作的时间复杂度为O(1),TreeMap增删改查操作的时间复杂度为O(log(n))。
- HashMap允许null值,TreeMap中默认的排序算法中put操作不允许null键,但是值(value)允许为null;若传入自定义比较器,可以手动处理null键的情况。
小结
- TreeMap的查询、插入、删除效率均没有HashMap高,一般只有要对key排序时才使用TreeMap
- TreeMap的key不能为null,而HashMap的key可以为null。
- 非线程安全,若须实现同步可:SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
四、HashTable
HashMap位于java.util包下
底层实现:散列桶(数组和单链表)
特点:
- 数据无序
- 键和值均不允许为null
- 线程安全
具体结构与HashMap相类似,简单归纳如下:
属性
//HashTable的数组【实质是一个Enrty数组,数组的默认长度:11】 private transient Entry<?,?>[] table; //HashTable条目数总量 private transient int count; //下次扩容量【每次扩容大小:2倍旧长度+1】 private int threshold; //负载因子【默认:0.75】 private float loadFactor; //修改次数 private transient int modCount = 0;
主要方法解析
put()
- (1)判断value不可为空
- (2)若key已经在table中存在,通过for循环,查找符合条件的key,用新值覆盖旧值,并返回旧值
- (3)若key不存在则进行新增操作:
- (modCount)修改次数+1,判断HashTable是否需要扩容
- 根据hash算法得到索引位置
- 在指定位置插入新的Entry对象
- HashTable的(count)条目数 +1
get()
- 用与put方法内同样的hash算法计算出key对应的索引下标,去外层的Entry数组内获取对应的value
remove()
- (1)用与put方法内同样的hash算法计算出key对应的索引下标
- (2)删除节点,并修复链表
五、ConcurrentHashMap
ConcurrentHashMap位于java.util.concurrent包下
底层实现:数组+链表+红黑树
特点:
- Segment数组结构
- HashEntry数组结构
- 分段锁
- 线程安全
PS:size() 和 containsValue()之类的方法需要锁定全表,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
PS:Segment里面包含了一个HashEntry数组。Segment实现一种可重入锁ReentrantLock的功能,在ConcurrentHashMap里扮演锁的角色。
PS:HashEntry则用于存储键值对数据。
结构
JDK1.7

JDK1.8

数据结构:数组+链表+红黑树
HashMap和ConcurrentHashMap的区别
- 1、HashMap 不是线程安全的,而 ConcurrentHashMap 是线程安全的。
- 2、ConcurrentHashMap 采用锁分段技术,将整个 Hash 桶进行了分段 segment,也就是将这个大的数组分成了几个小的片段 segment,而且每个小的片段 segment 上面都有锁存在,那么在插入元素的时候就需要先找到应该插入到哪一个片段 segment,然后再在这个片段上面进行插入,而且这里还需要获取 segment 锁。
- 3、ConcurrentHashMap 让锁的粒度更精细一些,并发性能更好。
HashTable 和 ConcurrentHashMap 的区别
- 它们都可以用于多线程的环境,但是当 Hashtable 的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。
- ConcurrentHashMap 引入了分段(segmentation),不论它变得多么大,仅仅需要锁定 map 的某个部分,而其它的线程不需要等到迭代完成才能访问map。
简而言之,在迭代的过程中,ConcurrentHashMap仅仅锁定map的某个部分,而Hashtable则会锁定整个map。
六、总结
HashMap
- 数据无序
- 底层实现是散列桶(数组和链表和红黑树)
- 默认初始化容量是16,每次容量达到外层Entry数组的0.75倍以后就会扩容2倍
- 键和值均允许为null
- 非同步,线程不安全
TreeMap
- 数据有序
- 比HashMap多实现了了NavigableMap接口,使得键有序
- 非同步,线程不安全
HashTable
- 数据无序
- 键和值均不允许为null
- 同步,线程安全
一句话小结:增删改查多用HashMap,需要排序的Map场景用TreeMap,同步场景用ConcurrentHashMap。
参考资料:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律