Jmeter(三十五)聚合报告
Jmeter的聚合报告是一个非常nice的listener,接口测试以及性能测试方面都会用到这个nice的监听器。
那么优秀在什么地方呢?上图
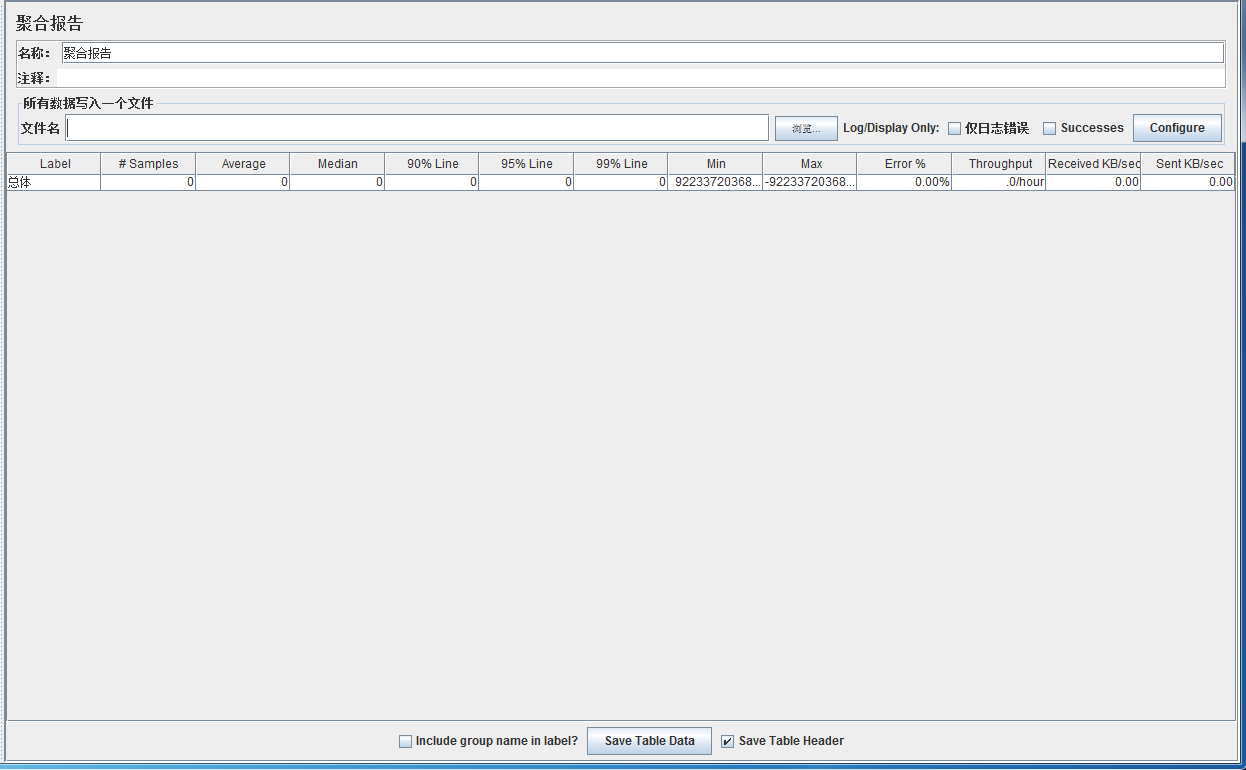
日常工作中可能只关注这部分内容:

可是这里边的指标真的都懂么?看了几篇知名大师的博客,都侧重谈了聚合报告这块的内容;当然,我在面试过程中,也经常有问在简历上写着“精通Jmeter”的面试者一些关于聚合报告方面的问题,遗憾,能回答上来的寥寥无几;或者说能答到重心的不多。可能本身这块的一个指标就存在一定的误区。
虽说在一些博客、公众号文章,一些大师用单独篇幅来讲解,貌似“后浪”并没有那么在意。又或者有关聚合报告方面的指标确实是容易给大家带来一些误导。
因此,我也着重来记一下聚合报告方面的内容。
和往常一样,先贴官方文档(有人经常吐槽看不懂英文,是硬伤总归是硬伤,慢慢补,当下为解燃眉之急,谷歌翻译、有道翻译等便是良策!):
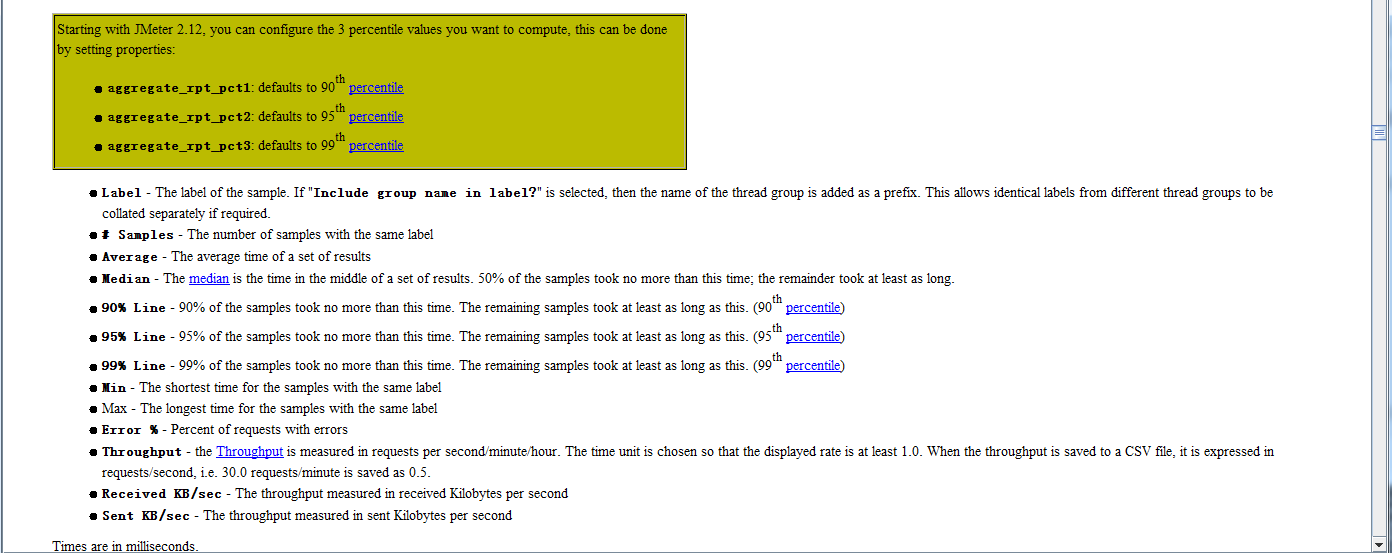
帮助文档中清清楚楚的将每个指标都进行了诠释,可能某些翻译的原因或者自我认知的原因,都导致了一些误解。一一来进行解读吧。
Label:通俗一点的翻译是标签。(该标签通常争议不大)
【样品的标签。如果“在标签中包含组名?”然后,将线程组的名称作为前缀添加。这允许相同的标签从不同的线程组分开整理,如果需要的话。】(百度翻译)
#Samples:【相同标签的样本数】,请求数。
Average:平均响应时间。
1,2,3,4,5,6,7,8---这组数据的平均响应时间为45/8=5.625。
Median:中位数。
1,2,3,4,5,6,7,8,9---该组数据的中位数为5.
90%Line:【90%的样品不超过这个时间。剩下的样本至少和这个一样长。(第九十百分位数)】翻译何解?
通常有人将“90%Line”这个指标理解为90%用户的响应时间。
这个时候可以引申出来一个比较易理解的概念:众所周知,中国是一个人口大国,为衡量经济发展的情况,相关统计部门每年都会进行统计,xxx人已经实现脱贫(当然、具体标准就不扯了),那么这块的人数是怎么统计出来的呢?
当然、一个一个去统计是不现实的(当下),那么这个时候,90%Line指标就显得有效,同理,我们先带入进去,概念为“90%Line的平均响应时间”,按这个概念来讲,是完全不科学的;不能排除富到极点的人,也不能排除穷到极点的人,难道不是么?
0,1,2,3,4,5,6,7,8,9;90%的数为0,1,2,3,4,5,6,7,8,90%Line为(0+1+2+3+4+5+6+7+8)/9,这样的理解显然是不正确的。
那么,再代入翻译中的概念【90%的样品不超过这个时间】,假设0,1,2,3,4,5,6,7,8,9,90%Line的值为8,其言下之意为没有超过8的数都为“贫穷”,相比平均响应时间,可信度比较高。
95%Line:同上。
99%Line:同上。
Min:最小值。
Max:最大值
Error%:错误占比。
Throughput:吞吐量。
Received KB/sec:接收KB/SEC -以每秒接收千字节测量的吞吐量。
Sent KB/sec:发送KB/SEC -以每秒千字节发送的吞吐量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号