Jmeter(三十一)Jmeter Question 之 乱码解读
众所周知,编码的问题影响着众多开发者,当然见多不怪。
先扒了一个编码的原因,也就是为什么要编码:
- 计算机中存储信息的最小单元是一个字节即 8 个 bit,所以能表示的字符范围是 0~255 个
- 人类要表示的符号太多,无法用一个字节来完全表示
- 要解决这个矛盾必须需要一个新的数据结构 char,从 char 到 byte 必须编码
Jmeter中也是存在编码(也就是常见的‘乱码’)问题。
常见的编码格式有ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16等,而GB2312、GBK、UTF-8、UTF-16格式便是常用的汉字编码格式。
回到正主,Jmeter中的编码又是什么呢?

该段内容截取至${jmeter_home}\bin\jmeter.propeties文件
从截图中的这段注释中便可以看到。jmeter默认是以ISO-8859-1编码格式进行编码的。
那么在GUI界面进行操作的过程中,与某些响应报文的编码格式不一致时,便会出现乱码情况。如下:
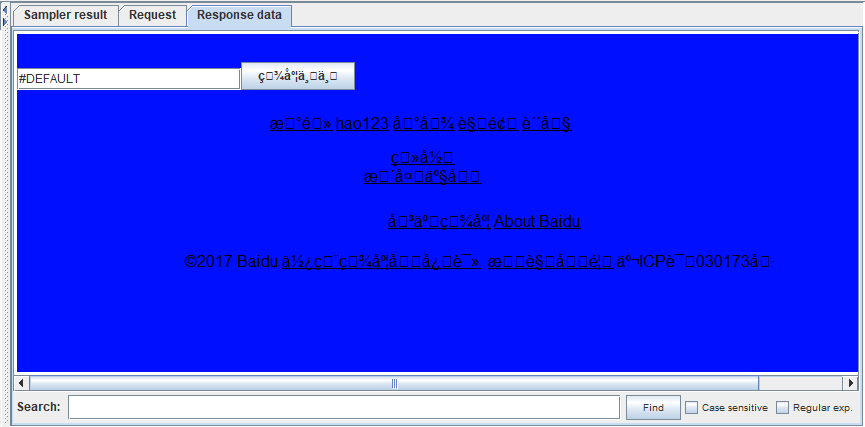
响应乱码便是如此。
解决方案:1)修改配置文件中的编码格式(上方截图所示)
2)直接在请求处的编码格式中输入编码格式(下图示)
还有一种乱码便是请求报文乱码,常出现场景:外部文件参数化。
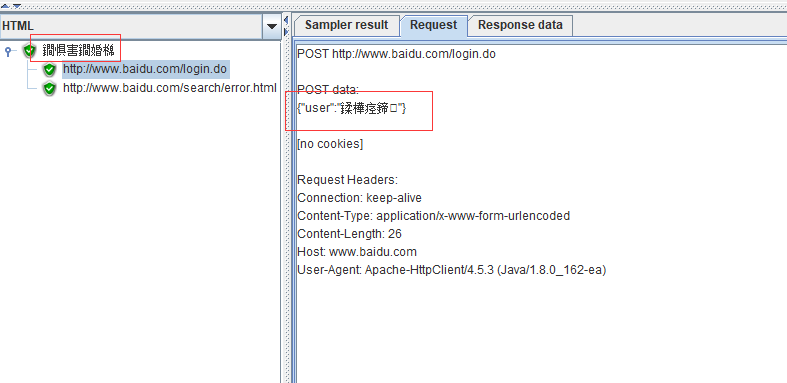
CSV文件中未定义编码格式。
加入编码格式,请求重试

还有一种乱码情况,通常在录制的情况会出现。
具体的场景是,录制完成之后,接口的请求body data中有乱码信息,例如某些json字符串等。
通过翻阅官方文档,是有该情况。
body data中文乱码,是因为jmeter自3.0起,优化了body data后默认的字体(consolas)不支持中文显示;
解决方案:在jmeter.properties中查找jsyntaxtextarea.font.family,取消注释,使用hack字体即可(当然也可以换成支持的其他字符集)
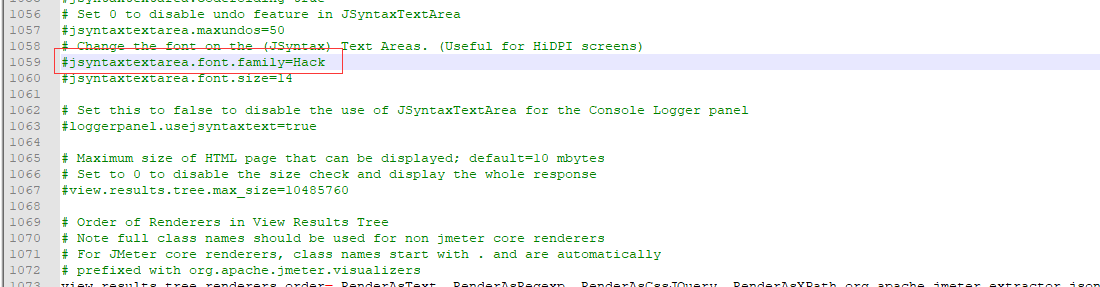
本人也使用3.2进行了录制,部分body data中的json字符串是有这种不支持中文显示的乱码情况,不过,本人也进行调试,是不影响使用的,可以进行请求使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号