django[二] 模型层models -- 迁
模型和字段
基本用法
下面的模型定义了一个“人”,它具有first_name和last_name字段:
from django.db import models
class Person(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
列名都统一用小写!
模板文件中表名一般都用首字母大写 SaltLog 必要使用 tb_name = u'salt_log_test'
每一个字段都是一个类属性,每个类属性表示数据表中的一个列。
上面的代码,相当于下面的原生SQL语句:
CREATE TABLE myapp_person (
"id" serial NOT NULL PRIMARY KEY,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL
);
注意:
- 表名
myapp_person由Django自动生成,默认格式为“项目名称+下划线+小写类名”,你可以重写这个规则。 - Django默认自动创建自增主键
id,当然,你也可以自己指定主键。 - 上面的SQL语句基于
PostgreSQL语法。
通常,我们会将模型编写在其所属app下的models.py文件中,没有特别需求时,请坚持这个原则,不要自己给自己添加麻烦。
创建了模型之后,在使用它之前,你需要先在settings文件中的INSTALLED_APPS 处,注册models.py文件所在的myapp。看清楚了,是注册app,不是模型,也不是models.py。如果你以前写过模型,可能已经做过这一步工作,可跳过。
INSTALLED_APPS = [ #... 'myapp', #... ]
当你每次对模型进行增、删、修改时,请务必执行命令python manage.py migrate,让操作实际应用到数据库上。这里可以选择在执行migrate之前,先执行python manage.py makemigrations让修改动作保存到记录文件中,方便github等工具的使用。
模型内建属性
instance._meta
# 获取所有的field name [field.name for field in instance._meta.fields] # 设置verbost_name >>> x._meta.verbose_name 'user info' # 获取当前对象的 model_name >>> x._meta.model_name 'userinfo'
将Model对象转化为dict
class UserInfo(models.Model):
username = models.CharField(max_length=32)
pwd = models.CharField(max_length=100)
email = models.EmailField()
user_type = models.ForeignKey(to="UserType", to_field='id', on_delete=models.DO_NOTHING)
x=<UserInfo: UserInfo object (24)>
# 方式1
>>> x.__dict__
{'_state': <django.db.models.base.ModelState object at 0x7f15a79677f0>, 'id': 24, 'username': 'root', 'pwd': '111', 'email': '
gaotao@huored.com', 'user_type_id': 3}
# 方式2
from django.forms.models import model_to_dict
model_to_dict(x)
{'id': 24, 'username': 'root', 'pwd': '111', 'email': 'gaotao@huored.com', 'user_type': 3}
但是注意时间字段可能被忽略!
# 方式3
>>> models.UserInfo.objects.filter(id=24).values()[0]
{'id': 24, 'username': 'root', 'pwd': '111', 'email': 'gaotao@huored.com', 'user_type_id': 3}
通过名称获取model class
from django.apps import apps
>>> apps.get_model('xdiscovery','Event')
<class 'xdiscovery.models.Event'>
>>> apps.get_model('xdiscovery','service')
<class 'xdiscovery.models.Service'>
使用Manager与数据库交互
添加自定义方法
默认情况下,Django为所有的model都添加了一个名叫objects的Manager,用于与数据库交互,比如:
Auth.objects.get(id=1)
不要小看这个objects他可以对QuerySet实例对象进行方法的封装。
from django.db import models class Person(model.Model): id = models.Ingter() # 自定义“接口”名称为people people = models.Manager() #调用方法 Person.people.get(id=5)
需要注意的是: Manager中的方法,可以通过self.model 来获取当前Manager绑定的Model。
修改Manager的初始QuerySet
默认时,在不加刷选过滤的情况下,XX.objects.all()会返回数据库中相关的所有记录。你可以通过重写get_queryset 方法来修改这个默认的行为。
class BookManager7x(models.Manager):
def get_queryset(self):
return super().get_queryset().filter(title='七夕节')
class Book(models.Model):
title = models.CharField(max_length=100)
publication_date = models.CharField(max_length=100)
num_pages = models.IntegerField(blank=True, null=True)
objects_7x = BookManager7x()
def __str__(self):
return self.title
在上例中,Book.objects.all()会返回所有的相关的记录,但是Book.objects_7x.all()只会返回主题是七夕的书籍。
注意:一个model上可以绑定多个Manager,当绑定了一个自定义的Manager之后,原来的objects就没用了
通过自定义的QuerySet来完成Manager的功能
由于大多数的QuerySet的方法都是通过Manager来访问的,当我们实现了一个自定义的QuerySet时,也需要实现自定义的Manager
class BookQuerySet(models.QuerySet):
def small(self):
return self.filter(num_pages__gt=10)
def big(self):
return self.filter(num_pages__lt=10)
class BookManager(models.Manager):
def get_queryset(self):
# return super().get_queryset().filter(title='情人节')
return BookQuerySet(self.model, using=self._db)
def title_count(self, keyword):
return self.filter(title__icontains=keyword).count()
class Book(models.Model):
title = models.CharField(max_length=100)
publication_date = models.CharField(max_length=100)
num_pages = models.IntegerField(blank=True, null=True)
objects = BookManager()
def __str__(self):
return self.title
结果
>>> Book.objects.all().big() <BookQuerySet [<Book: 七夕节>]> >>> Book.objects.all().small() <BookQuerySet [<Book: 情人节>]>
模型字段fields
字段是模型中最重要的内容之一,也是唯一必须的部分。字段在Python中表现为一个类属性,体现了数据表中的一个列。请不要使用clean、save、delete等Django内置的模型API名字,防止命名冲突。下面是一个展示,注意字段的写法,Django不允许下面两种字段名:Django不允许下面两种字段名 , 'foo__bar' 有两个下划线在一起
常用字段类型
字段类型的作用:
- 决定数据库中对应列的数据类型(例如:INTEGER, VARCHAR, TEXT)
- HTML中对应的表单标签的类型,例如
<input type=“text” /> - 在admin后台和自动生成的表单中最小的数据验证需求
|
类型 |
说明 |
| AutoField | 一个自动增加的整数类型字段。通常你不需要自己编写它,Django会自动帮你添加字段:id = models.AutoField(primary_key=True),这是一个自增字段,从1开始计数。如果你非要自己设置主键,那么请务必将字段设置为primary_key=True。Django在一个模型中只允许有一个自增字段,并且该字段必须为主键! |
| BigAutoField | (1.10新增)64位整数类型自增字段,数字范围更大,从1到9223372036854775807 |
| BigIntegerField | 64位整数字段(看清楚,非自增),类似IntegerField ,-9223372036854775808 到9223372036854775807。在Django的模板表单里体现为一个textinput标签 |
| BinaryField | 二进制数据类型。使用受限,少用。 |
| BooleanField | 布尔值类型。默认值是None。在HTML表单中体现为CheckboxInput标签。如果要接收null值,请使用NullBooleanField |
| CharField | 字符串类型。必须接收一个max_length参数,表示字符串长度不能超过该值。默认的表单标签是input text。最常用的filed,没有之一! |
| CommaSeparatedIntegerField | 逗号分隔的整数类型。必须接收一个max_length参数。常用于表示较大的金额数目,例如1,000,000元。 |
| DateField | class DateField(auto_now=False, auto_now_add=False, **options)日期类型。一个Python中的datetime.date的实例。在HTML中表现为TextInput标签。在admin后台中,Django会帮你自动添加一个JS的日历表和一个“Today”快捷方式,以及附加的日期合法性验证。两个重要参数:(参数互斥,不能共存) auto_now:每当对象被保存时将字段设为当前日期,常用于保存最后修改时间。auto_now_add:每当对象被创建时,设为当前日期,常用于保存创建日期(注意,它是不可修改的)。设置上面两个参数就相当于给field添加了editable=False和blank=True属性。如果想具有修改属性,请用default参数。例子:pub_time = models.DateField(auto_now_add=True),自动添加发布时间。 |
| DateTimeField | 日期时间类型。Python的datetime.datetime的实例。与DateField相比就是多了小时、分和秒的显示,其它功能、参数、用法、默认值等等都一样。Log.objects.filter(start_time__range=[from_week, datetime.datetime.now()]) |
| DecimalField | 固定精度的十进制小数。相当于Python的Decimal实例,必须提供两个指定的参数!参数max_digits:最大的位数,必须大于或等于小数点位数 。decimal_places:小数点位数,精度。 当localize=False时,它在HTML表现为NumberInput标签,否则是text类型。例子:储存最大不超过999,带有2位小数位精度的数,定义如下:models.DecimalField(..., max_digits=5, decimal_places=2) |
| DurationField | 持续时间类型。存储一定期间的时间长度。类似Python中的timedelta。在不同的数据库实现中有不同的表示方法。常用于进行时间之间的加减运算。但是小心了,这里有坑,PostgreSQL等数据库之间有兼容性问题! |
| EmailField | 邮箱类型,默认max_length最大长度254位。使用这个字段的好处是,可以使用DJango内置的EmailValidator进行邮箱地址合法性验证。 |
| FileField | class FileField(upload_to=None, max_length=100, **options)上传文件类型,后面单独介绍 |
| FilePathField | 文件路径类型,后面单独介绍 |
| FloatField | 浮点数类型,参考整数类型 |
| ImageField | 图像类型,后面单独介绍 |
| IntegerField | 整数类型,最常用的字段之一。取值范围-2147483648到2147483647。在HTML中表现为NumberInput标签。 |
| GenericIPAddressField | class GenericIPAddressField(protocol='both', unpack_ipv4=False, **options)[source],IPV4或者IPV6地址,字符串形式,例如192.0.2.30或者2a02:42fe::4在HTML中表现为TextInput标签。参数protocol默认值为‘both’,可选‘IPv4’或者‘IPv6’,表示你的IP地址类型。 |
| NullBooleanField | 类似布尔字段,只不过额外允许NULL作为选项之一 |
| PositiveIntegerField | 正整数字段,包含0,最大2147483647 |
| PositiveSmallIntegerField | 较小的正整数字段,从0到32767。 |
| SlugField | slug是一个新闻行业的术语。一个slug就是一个某种东西的简短标签,包含字母、数字、下划线或者连接线,通常用于URLs中。可以设置max_length参数,默认为50 |
| SmallIntegerField | 小整数,包含-32768到32767 |
| TextField | 大量文本内容,在HTML中表现为Textarea标签,最常用的字段类型之一!如果你为它设置一个max_length参数,那么在前端页面中会受到输入字符数量限制,然而在模型和数据库层面却不受影响。只有CharField才能同时作用于两者 |
| TimeField | 时间字段,Python中datetime.time的实例。接收同DateField一样的参数,只作用于小时、分和秒 |
| URLField | 一个用于保存URL地址的字符串类型,默认最大长度200 |
| UUIDField | 用于保存通用唯一识别码(Universally Unique Identifier)的字段。使用Python的UUID类。在PostgreSQL数据库中保存为uuid类型,其它数据库中为char(32)。这个字段是自增主键的最佳替代品,后面有例子展示 |
1.FileField:
class FileField(upload_to=None, max_length=100, **options)[source]
上传文件字段(不能设置为主键)。默认情况下,该字段在HTML中表现为一个ClearableFileInput标签。在数据库内,我们实际保存的是一个字符串类型,默认最大长度100,可以通过max_length参数自定义。真实的文件是保存在服务器的文件系统内的。
重要参数upload_to用于设置上传地址的目录和文件名。如下例所示:
class MyModel(models.Model):
# 文件被传至`MEDIA_ROOT/uploads`目录,MEDIA_ROOT由你在settings文件中设置
upload = models.FileField(upload_to='uploads/')
# 或者
# 被传到`MEDIA_ROOT/uploads/2015/01/30`目录,增加了一个时间划分
upload = models.FileField(upload_to='uploads/%Y/%m/%d/')
Django很人性化地帮我们实现了根据日期生成目录的方式!
upload_to参数也可以接收一个回调函数,该函数返回具体的路径字符串,如下例:
def user_directory_path(instance, filename):
#文件上传到MEDIA_ROOT/user_<id>/<filename>目录中
return 'user_{0}/{1}'.format(instance.user.id, filename)
class MyModel(models.Model):
upload = models.FileField(upload_to=user_directory_path)
例子中,user_directory_path这种回调函数,必须接收两个参数,然后返回一个Unix风格的路径字符串。参数instace代表一个定义了FileField的模型的实例,说白了就是当前数据记录。filename是原本的文件名。
2. ImageField:
class ImageField(upload_to=None, height_field=None, width_field=None, max_length=100, **options)[source]
用于保存图像文件的字段。其基本用法和特性与FileField一样,只不过多了两个属性height和width。默认情况下,该字段在HTML中表现为一个ClearableFileInput标签。在数据库内,我们实际保存的是一个字符串类型,默认最大长度100,可以通过max_length参数自定义。真实的图片是保存在服务器的文件系统内的。
height_field参数:保存有图片高度信息的模型字段名。 width_field参数:保存有图片宽度信息的模型字段名。
使用Django的ImageField需要提前安装pillow模块,pip install pillow即可。
使用FileField或者ImageField字段的步骤:
- 在settings文件中,配置
MEDIA_ROOT,作为你上传文件在服务器中的基本路径(为了性能考虑,这些文件不会被储存在数据库中)。再配置个MEDIA_URL,作为公用URL,指向上传文件的基本路径。请确保Web服务器的用户账号对该目录具有写的权限。 - 添加FileField或者ImageField字段到你的模型中,定义好
upload_to参数,文件最终会放在MEDIA_ROOT目录的“upload_to”子目录中。 - 所有真正被保存在数据库中的,只是指向你上传文件路径的字符串而已。可以通过url属性,在Django的模板中方便的访问这些文件。例如,假设你有一个ImageField字段,名叫
mug_shot,那么在Django模板的HTML文件中,可以使用{{ object.mug_shot.url }}来获取该文件。其中的object用你具体的对象名称代替。 - 可以通过
name和size属性,获取文件的名称和大小信息。
安全建议
无论你如何保存上传的文件,一定要注意他们的内容和格式,避免安全漏洞!务必对所有的上传文件进行安全检查,确保它们不出问题!如果你不加任何检查就盲目的让任何人上传文件到你的服务器文档根目录内,比如上传了一个CGI或者PHP脚本,很可能就会被访问的用户执行,这具有致命的危害。
3. FilePathField
class FilePathField(path=None, match=None, recursive=False, max_length=100, **options)[source]
一种用来保存文件路径信息的字段。在数据表内以字符串的形式存在,默认最大长度100,可以通过max_length参数设置。
它包含有下面的一些参数:
path:必须指定的参数。表示一个系统绝对路径。
match:可选参数,一个正则表达式,用于过滤文件名。只匹配基本文件名,不匹配路径。例如foo.*\.txt$,只匹配文件名foo23.txt,不匹配bar.txt与foo23.png。
recursive:可选参数,只能是True或者False。默认为False。决定是否包含子目录,也就是是否递归的意思。
allow_files:可选参数,只能是True或者False。默认为True。决定是否应该将文件名包括在内。它和allow_folders其中,必须有一个为True。
allow_folders: 可选参数,只能是True或者False。默认为False。决定是否应该将目录名包括在内。
比如:
FilePathField(path="/home/images", match="foo.*", recursive=True)
它只匹配/home/images/foo.png,但不匹配/home/images/foo/bar.png,因为默认情况,只匹配文件名,而不管路径是怎么样的。
4. UUIDField:
数据库无法自己生成uuid,因此需要如下使用default参数:
import uuid # Python的内置模块
from django.db import models
class MyUUIDModel(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
# 其它字段
5.auto_now 和 auto_now_add 的区别
创建django的model时,有DateTimeField、DateField和TimeField三种类型可以用来创建日期字段,其值分别对应着datetime()、date()、time()三中对象。这三个field有着相同的参数auto_now和auto_now_add,表面上看起来很easy,但实际使用中很容易出错,下面是一些注意点。
class Task(models.Model):
created = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
DateTimeField.auto_now
这个参数的默认值为false,设置为true时,能够在保存该字段时,将其值设置为当前时间,并且每次修改model,都会自动更新。因此这个参数在需要存储“最后修改时间”的场景下,十分方便。需要注意的是,设置该参数为true时,并不简单地意味着字段的默认值为当前时间,而是指字段会被“强制”更新到当前时间,你无法程序中手动为字段赋值;如果使用django再带的admin管理器,那么该字段在admin中是只读的。
DateTimeField.auto_now_add
这个参数的默认值也为False,设置为True时,会在model对象第一次被创建时,将字段的值设置为创建时的时间,以后修改对象时,字段的值不会再更新。该属性通常被用在存储“创建时间”的场景下。与auto_now类似,auto_now_add也具有强制性,一旦被设置为True,就无法在程序中手动为字段赋值,在admin中字段也会成为只读的。
“惰性翻译” 方法
使用 django.utils.translation.gettext_lazy() 函数,使得其中的值只有在访问时才会被翻译,而不是在 gettext_lazy() 被调用时翻译。 这样可以让程序启动时不再去翻译一些不使用的东西,减少内存的消耗。
举个栗子:
from django.utils.translation import ugettext_lazy as _
class MyThing(models.Model):
name = models.CharField(help_text=_('This is the help text'))
在这个例子中, ugettext_lazy() 将字符串作为惰性参照存储,而不是实际翻译。 翻译工作将在字符串在字符串上下文中被用到时进行,比如在Django管理页面提交模板时。
在Django模型中总是无一例外的使用惰性翻译。 为了翻译,字段名和表名应该被标记。(否则的话,在管理界面中它们将不会被翻译) 这意味着在Meta类中显式地编写verbose_nane和verbose_name_plural选项,而不是依赖于Django默认的verbose_name和verbose_name_plural(通过检查model的类名得到)。
from django.utils.translation import ugettext_lazy as _
class MyThing(models.Model):
name = models.CharField(_('name'), help_text=_('This is the help text'))
class Meta:
verbose_name = _('my thing')
verbose_name_plural = _('mythings')
多对一(ForeignKey)
基本用法
class ForeignKey(to, on_delete, **options)[source]
外键需要两个位置参数,一个是关联的模型,另一个是on_delete选项。实际上,在目前版本中,on_delete选项也可以不设置,但Django极力反对如此,因此在Django2.0版本后,该选项会设置为必填。
外键要定义在‘多’的一方!
from django.db import models
class Car(models.Model):
manufacturer = models.ForeignKey(
to='Manufacturer',
to_field='mid'
on_delete=models.CASCADE,
)
# ...
class Manufacturer(models.Model):
# ...
mid = models.IntergerField(primary_key=True, unique=True)
name = models.CharField(max_length=100)
如果要创建一个递归的外键,也就是自己关联自己的的外键,使用下面的方法:
models.ForeignKey('self', on_delete=models.CASCADE)
核心在于‘self’这个引用。什么时候需要自己引用自己的外键呢?典型的例子就是评论系统!一条评论可以被很多人继续评论,如下所示:
class Comment(models.Model):
title = models.CharField(max_length=128)
text = models.TextField()
parent_comment = models.ForeignKey('self', on_delete=models.CASCADE)
# .....
注意上面的外键字段定义的是父评论,而不是子评论。为什么呢?因为外键要放在‘多’的一方!
在实际的数据库后台,Django会为每一个外键添加_id后缀,并以此创建数据表里的一列。在上面的工厂与车的例子中,Car模型对应的数据表中,会有一列叫做manufacturer_id。但实际上,在Django代码中你不需要使用这个列名,除非你书写原生的SQL语句,一般我们都直接使用字段名manufacturer。
关系字段的定义还有个小坑。在后面我们会讲到的verbose_name参数用于设置字段的别名。很多情况下,为了方便,我们都会设置这么个值,并且作为字段的第一位置参数。但是对于关系字段,其第一位置参数永远是关系对象,不能是verbose_name,一定要注意!
on_delete
当一个被外键关联的对象被删除时,Django将模仿on_delete参数定义的SQL约束执行相应操作。比如,你有一个可为空的外键,并且你想让它在关联的对象被删除时,自动设为null,可以如下定义:
user = models.ForeignKey(
User,
models.SET_NULL,
blank=True,
null=True,
)
该参数可选的值都内置在django.db.models中,包括:
- CASCADE:模拟SQL语言中的
ON DELETE CASCADE约束,将定义有外键的模型对象同时删除!(该操作为当前Django版本的默认操作!) - PROTECT:阻止上面的删除操作,但是弹出
ProtectedError异常 - SET_NULL:将外键字段设为null,只有当字段设置了
null=True时,方可使用该值。 - SET_DEFAULT:将外键字段设为默认值。只有当字段设置了default参数时,方可使用。
- DO_NOTHING:什么也不做。
- SET():设置为一个传递给SET()的值或者一个回调函数的返回值。注意大小写。
from django.conf import settings
from django.contrib.auth import get_user_model
from django.db import models
def get_sentinel_user():
return get_user_model().objects.get_or_create(username='deleted')[0]
class MyModel(models.Model):
user = models.ForeignKey(
settings.AUTH_USER_MODEL,
on_delete=models.SET(get_sentinel_user),
)
limit_choices_to
该参数用于限制外键所能关联的对象,只能用于Django的ModelForm(Django的表单模块)和admin后台,对其它场合无限制功能。其值可以是一个字典、Q对象或者一个返回字典或Q对象的函数调用,如下例所示:
staff_member = models.ForeignKey(
User,
on_delete=models.CASCADE,
limit_choices_to={'is_staff': True},
)
这样定义,则ModelForm的staff_member字段列表中,只会出现那些is_staff=True的Users对象,这一功能对于admin后台非常有用。限制查询结果集
可以参考下面的方式,使用函数调用:
def limit_pub_date_choices():
return {'pub_date__lte': datetime.date.utcnow()}
# ...
limit_choices_to = limit_pub_date_choices
# ...
related_name
用于关联对象反向引用模型的名称。以前面车和工厂的例子解释,就是从工厂反向关联到车的关系名称。
通常情况下,这个参数我们可以不设置,Django会默认以模型的小写作为反向关联名,比如对于工厂就是car,如果你觉得car还不够直观,可以如下定义:
class Car(models.Model):
manufacturer = models.ForeignKey(
'production.Manufacturer',
on_delete=models.CASCADE,
related_name='car_producted_by_this_manufacturer', # 看这里!!
)
也许我定义了一个蹩脚的词,但表达的意思很清楚。以后从工厂对象反向关联到它所生产的汽车,就可以使用maufacturer.car_producted_by_this_manufacturer了。
如果你不想为外键设置一个反向关联名称,可以将这个参数设置为“+”或者以“+”结尾,如下所示:
user = models.ForeignKey(
User,
on_delete=models.CASCADE,
related_name='+',
)
related_query_name
反向关联查询名。用于从目标模型反向过滤模型对象的名称
class Tag(models.Model):
article = models.ForeignKey(
Article,
on_delete=models.CASCADE,
related_name="tags",
related_query_name="tag", # 注意这一行
)
name = models.CharField(max_length=255)
# 现在可以使用‘tag’作为查询名了
Article.objects.filter(tag__name="important")
to_field
默认情况下,外键都是关联到被关联对象的主键上(一般为id)。如果指定这个参数,可以关联到指定的字段上,但是该字段必须具有unique=True属性,也就是具有唯一属性。
db_constraint
默认情况下,这个参数被设为True,表示遵循数据库约束,这也是大多数情况下你的选择。如果设为False,那么将无法保证数据的完整性和合法性。在下面的场景中,你可能需要将它设置为False:
- 有历史遗留的不合法数据,没办法的选择
- 你正在分割数据表
当它为False,并且你试图访问一个不存在的关系对象时,会抛出DoesNotExist 异常。
swappable
控制迁移框架的动作,如果当前外键指向一个可交换的模型。使用场景非常稀少,通常请将该参数保持默认的True。
1、搜索条件使用 __ 连接 2、获取值时使用 . 连接
查询
>>> b = App_version.objects.get(id=1) >>> b.app_id u'1' >>> b.create_user_id.username u'zgt' 查找blog表中外键关系entry表中的headline字段中包含Lennon的blog数据,注意是 两个"_" >>> Blog.objects.filter(entry__headline__contains='Lennon') 当然z也可以是一个zone_id z=get_object(Zone,id=zone_id) Record.objects.filter(zone=z) 利用_set 反查另一端的数据,通过book来反查他的一对多关系中的一,类似上面的__headline p = publisher.objects.filter(name='how to python') p.book_set.all() 利用related_name 反查被外键的表的数据 请看上面 related_name 部分,效果和 _set 一样的
更新
方法一:
kwargs = {}
kwargs['filename'] = file_name
kwargs['loc_filename'] = random_name
kwargs['md5'] = file_md5
kwargs['create_user_id'] = _User
_all_app = get_object(App,id=app_id)
insert_App_version = App_version(**kwargs)
insert_App_version.save()
方法二:
models.UserInfo.objects.filter(email=input_em).update(pwd='nihao')
删除,注意删除后的动作是 on_delete
_App_version = get_object(App_version,id=each['version_id']) _App_version.delete()
插入
查询出 project_contact = get_object(User,id=user_id)
project = Project(
name=project_name,
description=description)
project.save()
ContentType多表外键
当出现一张表的一个字段被多张表做外键关系时,就要用到这个类型,比如 日志表要连接多个功能表的外键数据,优惠券表连接多个产品基表的外键数据等等。
models.py
from django.db import models
from django.contrib.contenttypes.models import ContentType
from django.contrib.contenttypes.fields import GenericForeignKey,GenericRelation
# Create your models here.
class Food(models.Model):
name = models.CharField(max_length=32)
coupon = GenericRelation("Coupon")
class Cloth(models.Model):
name = models.CharField(max_length=32)
coupon = GenericRelation("Coupon")
class Coupon(models.Model):
"""
id food_id cloth_id ……
null null
1 null
"""
name = models.CharField("活动名称",max_length=64)
brief = models.TextField(blank=True,null=True,verbose_name="优惠券介绍")
content_type = models.ForeignKey(ContentType,blank=True,null=True) # 代表哪个app下的哪张表
object_id = models.PositiveIntegerField("绑定商品",blank=True,null=True) # 代表哪张表中的对象id
content_obj = GenericForeignKey("content_type","object_id") #不会生成额外的列
# 普通的外键只能指定一个表做关联
class brand(models.Model):
bid = models.IntegerField(primary_key=True, unique=True)
name = models.CharField(max_length=111)
class shoes(models.Model):
name = models.CharField(max_length=111)
brand = models.ForeignKey(to=brand, to_field='bid') # shoes的外键是brand表的id
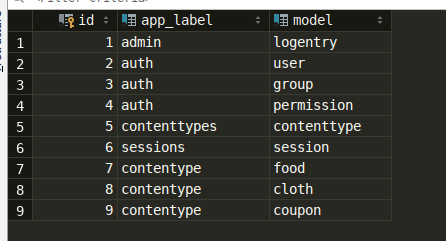
可以看到在content_type表中衍生出来的关系类型
我们看看如何使用:
from contentype import models
# 先创建Food和cloth表,然后在做外键外键关联
f = Food.objects.create(name='kfc')
>>> f
<Food: Food object>
c = Cloth.objects.create(name='nike')
# 创建优惠券
Coupon.objects.create(name='优惠券',brief='food coupon',content_obj=f)
c = Cloth.objects.get(id=1)
Coupon.objects.create(name='优惠券',brief='100减10',content_obj=c)
# 查看优惠券绑定的商品(根据优惠去查绑定的商品)
>>> Coupon.objects.all()[1]
<Coupon: 优惠券>
>>> Coupon.objects.all()[1].content_obj
<Cloth: nike>
# 根据商品查询所有优惠券
>>> c = models.Cloth.objects.get(id=1)
<Cloth: nike>
>>> Cloth.objects.values('name','coupon__brief')
<QuerySet [{'name': 'nike', 'coupon__brief': '100减10'}, {'name': 'nike', 'coupon__brief': '200减30'}]>
# 删除优惠券
>>> Coupon.objects.all()[1].delete()
(1, {'contentype.Coupon': 1})
多对多值(ManyToManyField)
基本用法
class ManyToManyField(to, **options)[source]
多对多关系需要一个位置参数:关联的对象模型。它的用法和外键多对一基本类似。
在数据库后台,Django实际上会额外创建一张用于体现多对多关系的中间表。默认情况下,该表的名称是“多对多字段名+关联对象模型名+一个独一无二的哈希码”,例如‘author_books_9cdf4’,当然你也可以通过db_table选项,自定义表名。
事例表:
class UserProfile(models.Model):
user_info = models.OneToOneField('UserInfo')
username = models.CharField(max_length=64)
password = models.CharField(max_length=64)
def __unicode__(self):
return self.username
class UserInfo(models.Model):
user_type_choice = (
(0, u'普通用户'),
(1, u'高级用户'),
)
user_type = models.IntegerField(choices=user_type_choice)
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
address = models.CharField(max_length=128)
def __unicode__(self):
return self.name
class UserGroup(models.Model):
caption = models.CharField(max_length=64)
user_info = models.ManyToManyField('UserInfo')
def __unicode__(self):
return self.caption
class Host(models.Model):
hostname = models.CharField(max_length=64)
ip = models.GenericIPAddressField()
user_group = models.ForeignKey('UserGroup')
def __unicode__(self):
return self.hostname
表结构实例
多对多操作
# user 和 group 是多对多关系,一个用户可以关联多个组,一个组也有多个用户 # 其中m2m字段是group关联到user表的id user_info_obj = models.UserInfo.objects.get(name=u'gaotao') user_info_objs = models.UserInfo.objects.all() group_obj = models.UserGroup.objects.get(caption='CEO') group_objs = models.UserGroup.objects.all() ------ group表的对象 -------- # 添加数据 #group_obj.user_info.add(user_info_obj) #group_obj.user_info.add(*user_info_objs) # QuerySet # 删除数据 #group_obj.user_info.remove(user_info_obj) #group_obj.user_info.remove(*user_info_objs) # 获取数据 #print group_obj.user_info.all() #print group_obj.user_info.all().filter(id=1) --------user表的对象 ---------- # 添加数据 #user_info_obj.usergroup_set.add(group_obj) #user_info_obj.usergroup_set.add(*group_objs) # 删除数据 #user_info_obj.usergroup_set.remove(group_obj) #user_info_obj.usergroup_set.remove(*group_objs) # 获取数据 #print user_info_obj.usergroup_set.all() #print user_info_obj.usergroup_set.all().filter(caption='CEO') #print user_info_obj.usergroup_set.all().filter(caption='DBA') 区别就是加了一个_set
参数说明:
related_name
参考外键的相同参数。
related_query_name
参考外键的相同参数。
limit_choices_to
参考外键的相同参数。但是对于使用through参数自定义中间表的多对多字段无效。
symmetrical
默认情况下,Django中的多对多关系是对称的。看下面的例子:
from django.db import models
class Person(models.Model):
friends = models.ManyToManyField("self"
Django认为,如果我是你的朋友,那么你也是我的朋友,这是一种对称关系,Django不会为Person模型添加person_set属性用于反向关联。如果你不想使用这种对称关系,可以将symmetrical设置为False,这将强制Django为反向关联添加描述符。
自身关联
class Person(models.Model):
friends = models.ManyToManyField("self")
through(定义中间表)
如果你想自定义多对多关系的那张额外的关联表,可以使用这个参数!参数的值为一个中间模型。
最常见的使用场景是你需要为多对多关系添加额外的数据,比如两个人建立QQ好友的时间。
通常情况下,这张表在数据库内的结构是这个样子的:
中间表的id列....模型对象的id列.....被关联对象的id列.....时间对象列 # 各行数据
举例
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=50)
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(
Person,
through='Membership', ## 自定义中间表
through_fields=('group', 'person'),
)
class Membership(models.Model): # 这就是具体的中间表模型
group = models.ForeignKey(Group, on_delete=models.CASCADE)
person = models.ForeignKey(Person, on_delete=models.CASCADE)
inviter = models.ForeignKey(
Person,
on_delete=models.CASCADE,
related_name="membership_invites",
)
invite_reason = models.CharField(max_length=64)
上面的代码中,通过class Membership(models.Model)定义了一个新的模型,用来保存Person和Group模型的多对多关系,并且同时增加了‘邀请人’和‘邀请原因’的字段。
使用中间表操作
>>> ringo = Person.objects.create(name="Ringo Starr") >>> paul = Person.objects.create(name="Paul McCartney") >>> beatles = Group.objects.create(name="The Beatles") >>> m1 = Membership(person=ringo, group=beatles, ... date_joined=date(1962, 8, 16), ... invite_reason="Needed a new drummer.") >>> m1.save() >>> beatles.members.all() <QuerySet [<Person: Ringo Starr>]> >>> ringo.group_set.all() <QuerySet [<Group: The Beatles>]> >>> m2 = Membership.objects.create(person=paul, group=beatles, ... date_joined=date(1960, 8, 1), ... invite_reason="Wanted to form a band.") >>> beatles.members.all() <QuerySet [<Person: Ringo Starr>, <Person: Paul McCartney>]>
与普通的多对多不一样,使用自定义中间表的多对多不能使用add(), create(),remove(),和set()方法来创建、删除关系,看下面
>>> # 无效 >>> beatles.members.add(john) >>> # 无效 >>> beatles.members.create(name="George Harrison") >>> # 无效 >>> beatles.members.set([john, paul, ringo, george])
为什么?因为上面的方法无法提供加入时间、邀请原因等中间模型需要的字段内容。唯一的办法只能是通过创建中间模型的实例来创建这种类型的多对多关联。但是,clear()方法是有效的,它能清空所有的多对多关系
>>> # 甲壳虫乐队解散了 >>> beatles.members.clear() >>> # 删除了中间模型的对象 >>> Membership.objects.all() <QuerySet []>
一旦你通过创建中间模型实例的方法建立了多对多的关联,你立刻就可以像普通的多对多那样进行查询操作
# 查找组内有Paul这个人的所有的组(以Paul开头的名字) >>> Group.objects.filter(members__name__startswith='Paul') <QuerySet [<Group: The Beatles>]> 可以使用中间模型的属性进行查询: # 查找甲壳虫乐队中加入日期在1961年1月1日之后的成员 >>> Person.objects.filter( ... group__name='The Beatles', ... membership__date_joined__gt=date(1961,1,1)) <QuerySet [<Person: Ringo Starr]> 可以像普通模型一样使用中间模型: >>> ringos_membership = Membership.objects.get(group=beatles, person=ringo) >>> ringos_membership.date_joined datetime.date(1962, 8, 16) >>> ringos_membership.invite_reason 'Needed a new drummer.' >>> ringos_membership = ringo.membership_set.get(group=beatles) >>> ringos_membership.date_joined datetime.date(1962, 8, 16) >>> ringos_membership.invite_reason 'Needed a new drummer.'
through_fields
接着上面的例子。Membership模型中包含两个关联Person的外键,Django无法确定到底使用哪个作为和Group关联的对象。所以,在这个例子中,必须显式的指定through_fields参数,用于定义关系。
through_fields参数接收一个二元元组('field1', 'field2'),field1是指向定义有多对多关系的模型的外键字段的名称,这里是Membership中的‘group’字段(注意大小写),另外一个则是指向目标模型的外键字段的名称,这里是Membership中的‘person’,而不是‘inviter’。
再通俗的说,就是through_fields参数指定从中间表模型Membership中选择哪两个字段,作为关系连接字段。
db_table
设置中间表的名称。不指定的话,则使用默认值。
db_constraint
参考外键的相同参数。
swappable
参考外键的相同参数。
ManyToManyField多对多字段不支持Django内置的validators验证功能。
null参数对ManyToManyField多对多字段无效!设置null=True毫无意义
一对一(OneToOneField)
基本用法
class OneToOneField(to, on_delete, parent_link=False, **options)[source]
从概念上讲,一对一关系非常类似具有unique=True属性的外键关系,但是反向关联对象只有一个。这种关系类型多数用于当一个模型需要从别的模型扩展而来的情况。比如,Django自带auth模块的User用户表,如果你想在自己的项目里创建用户模型,又想方便的使用Django的认证功能,那么一个比较好的方案就是在你的用户模型里,使用一对一关系,添加一个与auth模块User模型的关联字段。
该关系的第一位置参数为关联的模型,其用法和前面的多对一外键一样。
如果你没有给一对一关系设置related_name参数,Django将使用当前模型的小写名作为默认值。
看下面的例子:
from django.conf import settings
from django.db import models
# 两个字段都使用一对一关联到了Django内置的auth模块中的User模型
class MySpecialUser(models.Model):
user = models.OneToOneField(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
)
supervisor = models.OneToOneField(
settings.AUTH_USER_MODEL,
on_delete=models.CASCADE,
related_name='supervisor_of',
)
这样下来,你的User模型将拥有下面的属性:
>>> user = User.objects.get(pk=1) >>> hasattr(user, 'myspecialuser') True >>> hasattr(user, 'supervisor_of') True
OneToOneField一对一关系拥有和多对一外键关系一样的额外可选参数,只是多了一个parent_link参数。
跨模块的模型:
有时候,我们关联的模型并不在当前模型的文件内,没关系,就像我们导入第三方库一样的从别的模块内导入进来就好,如下例所示:
from django.db import models
from geography.models import ZipCode
class Restaurant(models.Model):
# ...
zip_code = models.ForeignKey(
ZipCode,
on_delete=models.SET_NULL,
blank=True,
null=True,
)
字段的参数
所有的模型字段都可以接收一定数量的参数,比如CharField至少需要一个max_length参数。下面的这些参数是所有字段都可以使用的,并且是可选的。
null
该值为True时,Django在数据库用NULL保存空值。默认值为False。对于保存字符串类型数据的字段,请尽量避免将此参数设为True,那样会导致两种‘没有数据’的情况,一种是NULL,另一种是‘空字符串’。
blank
True时,字段可以为空。默认False。和null参数不同的是,null是纯数据库层面的,而blank是验证相关的,它与表单验证是否允许输入框内为空有关,与数据库无关。所以要小心一个null为False,blank为True的字段接收到一个空值可能会出bug或异常。
choices
用于页面上的选择框标签,需要先提供一个二维的二元元组,第一个元素表示存在数据库内真实的值,第二个表示页面上显示的具体内容。在浏览器页面上将显示第二个元素的值。例如:
YEAR_IN_SCHOOL_CHOICES = (
('FR', 'Freshman'),
('SO', 'Sophomore'),
('JR', 'Junior'),
('SR', 'Senior'),
('GR', 'Graduate'),
)
一般来说,最好将选项定义在类里,并取一个直观的名字,如下所示:
from django.db import models
class Student(models.Model):
FRESHMAN = 'FR'
SOPHOMORE = 'SO'
JUNIOR = 'JR'
SENIOR = 'SR'
YEAR_IN_SCHOOL_CHOICES = (
(FRESHMAN, 'Freshman'),
(SOPHOMORE, 'Sophomore'),
(JUNIOR, 'Junior'),
(SENIOR, 'Senior'),
)
year_in_school = models.CharField(
max_length=2,
choices=YEAR_IN_SCHOOL_CHOICES,
default=FRESHMAN,
)
def is_upperclass(self):
return self.year_in_school in (self.JUNIOR, self.SENIOR)
要获取一个choices的第二元素的值,可以使用get_FOO_display()方法,其中的FOO用字段名代替.如果一个字段设置了这个属性,在模版中如果我要显示这个字段,
那么django模版系统就会将它默认解析为一个下来菜单,这样对于一个静态的下拉菜单式很方便的
from django.db import models
class Person(models.Model):
GENDER_CHOICES = (
(u'M', u'Male'),
(u'F', u'Female'),
)
name = models.CharField(max_length=60)
gender = models.CharField(max_length=2, choices=Person)
>>> p = Person(name="Fred Flinstone", gender="M") >>> p.save() >>> p.gender u'M' >>> p.get_gender_display() 显示choice的值 u'Male'
在get_queryset()方法中,可以增加一个display显示的属性
def get_queryset(self):
queryset = super(ServerListView, self).get_queryset()
self.keyword = self.request.GET.get('keyword', '').strip()
for each in queryset:
setattr(each, 'server_property_display', each.get_server_property_display()) # 增加一个值的属性
if self.keyword:
queryset = queryset.filter(Q(server_name__icontains=self.keyword))
return queryset
db_column
该参数用于定义当前字段在数据表内的列名。如果未指定,Django将使用字段名作为列名。
db_index
该参数接收布尔值。如果为True,数据库将为该字段创建索引。
db_tablespace
用于字段索引的数据库表空间的名字,前提是当前字段设置了索引。默认值为工程的DEFAULT_INDEX_TABLESPACE设置。如果使用的数据库不支持表空间,该参数会被忽略。
default
字段的默认值,可以是值或者一个可调用对象。如果是可调用对象,那么每次创建新对象时都会调用。设置的默认值不能是一个可变对象,比如列表、集合等等。lambda匿名函数也不可用于default的调用对象,因为匿名函数不能被migrations序列化。
注意:在某种原因不明的情况下将default设置为None,可能会引发intergyerror:not null constraint failed,即非空约束失败异常,导致python manage.py migrate失败,此时可将None改为False或其它的值,只要不是None就行。
editable
如果设为False,那么当前字段将不会在admin后台或者其它的ModelForm表单中显示,同时还会被模型验证功能跳过。参数默认值为True。
error_messages
用于自定义错误信息。参数接收字典类型的值。字典的键可以是null、 blank、 invalid、 invalid_choice、 unique和unique_for_date其中的一个。
help_text
额外显示在表单部件上的帮助文本。使用时请注意转义为纯文本,防止脚本攻击。
primary_key
如果你没有给模型的任何字段设置这个参数为True,Django将自动创建一个AutoField自增字段,名为‘id’,并设置为主键。也就是id = models.AutoField(primary_key=True)。
如果你为某个字段设置了primary_key=True,则当前字段变为主键,并关闭Django自动生成id主键的功能。
primary_key=True隐含null=False和unique=True的意思。一个模型中只能有一个主键字段!
另外,主键字段不可修改,如果你给某个对象的主键赋个新值实际上是创建一个新对象,并不会修改原来的对象。
from django.db import models
class Fruit(models.Model):
name = models.CharField(max_length=100, primary_key=True)
###############
>>> fruit = Fruit.objects.create(name='Apple')
>>> fruit.name = 'Pear'
>>> fruit.save()
>>> Fruit.objects.values_list('name', flat=True)
['Apple', 'Pear']
unique
设为True时,在整个数据表内该字段的数据不可重复。
注意:对于ManyToManyField和OneToOneField关系类型,该参数无效。
注意: 当unique=True时,db_index参数无须设置,因为unqiue隐含了索引。
注意:自1.11版本后,unique参数可以用于FileField字段。
serial_number = models.CharField(max_length=20,unique=True,verbose_name=u'序列号')
联合唯一键
class MyModel(models.Model):
field1 = models.CharField(max_length=50)
field2 = models.CharField(max_length=50)
class Meta:
unique_together = ('field1', 'field2',)
unique_for_date
日期唯一。可能不太好理解。举个栗子,如果你有一个名叫title的字段,并设置了参数unique_for_date="pub_date",那么Django将不允许有两个模型对象具备同样的title和pub_date。有点类似联合约束。
unique_for_month
同上,只是月份唯一。
unique_for_year
同上,只是年份唯一。
verbose_name
为字段设置一个人类可读,更加直观的别名。
对于每一个字段类型,除了ForeignKey、ManyToManyField和OneToOneField这三个特殊的关系类型,其第一可选位置参数都是verbose_name。如果没指定这个参数,Django会利用字段的属性名自动创建它,并将下划线转换为空格。
下面这个例子的verbose name是"person’s first name":
first_name = models.CharField("person's first name", max_length=30)
下面这个例子的verbose name是"first name":
first_name = models.CharField(max_length=30)
对于外键、多对多和一对一字字段,由于第一个参数需要用来指定关联的模型,因此必须用关键字参数verbose_name来明确指定,另外,你无须大写verbose_name的首字母,Django自动为你完成这一工作。
validators
运行在该字段上的验证器的列表。
模型的元数据Meta
想在模型中增加元数据,方法很简单,在模型类中添加一个子类,名字是固定的Meta,然后在这个Meta类下面增加各种元数据选项或者说设置项。参考下面的例子
from django.db import models
class Ox(models.Model):
horn_length = models.IntegerField()
class Meta: # 注意,是模型的子类,要缩进!
ordering = ["horn_length"]
verbose_name_plural = "oxen" // admin中显示的名称
db_table = u'App_version' // 直接定义表名
# 对模型起一个可读的名字(在admin站点有用)
verbose_name='salt_service'
# 不自动映射表(不自动创建),需要自动创建就去掉managed
managed = True
上面的例子中,我们为模型Ox增加了两个元数据‘ordering’和‘verbose_name_plural’,分别表示排序和复数名,下面我们会详细介绍有哪些可用的元数据选项。
强调:每个模型都可以有自己的元数据类,每个元数据类也只对自己所在模型起作用。
abstract
如果abstract=True,那么模型会被认为是一个抽象模型。抽象模型本身不实际生成数据库表,而是作为其它模型的父类,被继承使用。具体内容可以参考Django模型的继承。
app_label
如果定义了模型的app没有在INSTALLED_APPS中注册,则必须通过此元选项声明它属于哪个app,例如:
app_label = 'myapp'
base_manager_name
自定义模型的_base_manager管理器的名字。模型管理器是Django为模型提供的API所在。Django1.10新增。
db_table
指定在数据库中,当前模型生成的数据表的表名。比如:
db_table = 'my_freinds'
使用MySQL数据库时,db_table用小写英文。
db_tablespace
自定义数据库表空间的名字。默认值是工程的DEFAULT_TABLESPACE设置。
default_manager_name
自定义模型的_default_manager管理器的名字。Django1.10新增
default_related_name
默认情况下,从一个模型反向关联设置有关系字段的源模型,我们使用<model_name>_set,也就是源模型的名字+下划线+set。
这个元数据选项可以让你自定义反向关系名,同时也影响反向查询关系名!看下面的例子:
from django.db import models
class Foo(models.Model):
pass
class Bar(models.Model):
foo = models.ForeignKey(Foo)
class Meta:
default_related_name = 'bars' # 关键在这里
具体的使用差别如下:
>>> bar = Bar.objects.get(pk=1) >>> # 不能再使用"bar"作为反向查询的关键字了。 >>> Foo.objects.get(bar=bar) >>> # 而要使用你自己定义的"bars"了。 >>> Foo.objects.get(bars=bar)
get_latest_by
Django管理器给我们提供有latest()和earliest()方法,分别表示获取最近一个和最前一个数据对象。但是,如何来判断最近一个和最前面一个呢?也就是根据什么来排序呢?
get_latest_by元数据选项帮你解决这个问题,它可以指定一个类似 DateField、DateTimeField或者IntegerField这种可以排序的字段,作为latest()和earliest()方法的排序依据,从而得出最近一个或最前面一个对象。例如:
get_latest_by = "order_date"
managed
该元数据默认值为True,表示Django将按照既定的规则,管理数据库表的生命周期。
如果设置为False,将不会针对当前模型创建和删除数据库表。在某些场景下,这可能有用,但更多时候,你可以忘记该选项。
order_with_respect_to
这个选项不好理解。其用途是根据指定的字段进行排序,通常用于关系字段。看下面的例子:
from django.db import models
class Question(models.Model):
text = models.TextField()
# ...
class Answer(models.Model):
question = models.ForeignKey(Question, on_delete=models.CASCADE)
# ...
class Meta:
order_with_respect_to = 'question'
ordering
最常用的元数据之一了!
用于指定该模型生成的所有对象的排序方式,接收一个字段名组成的元组或列表。默认按升序排列,如果在字段名前加上字符“-”则表示按降序排列,如果使用字符问号“?”表示随机排列。请看下面的例子:
ordering = ['pub_date'] # 表示按'pub_date'字段进行升序排列 ordering = ['-pub_date'] # 表示按'pub_date'字段进行降序排列 ordering = ['-pub_date', 'author'] # 表示先按'pub_date'字段进行降序排列,再按`author`字段进行升序排列。
permissions
该元数据用于当创建对象时增加额外的权限。它接收一个所有元素都是二元元组的列表或元组,每个元素都是(权限代码, 直观的权限名称)的格式。比如下面的例子:
permissions = (("can_deliver_pizzas", "可以送披萨"),)
default_permissions
Django默认给所有的模型设置('add', 'change', 'delete')的权限,也就是增删改。你可以自定义这个选项,比如设置为一个空列表,表示你不需要默认的权限,但是这一操作必须在执行migrate命令之前。
proxy
如果设置了proxy = True,表示使用代理模式的模型继承方式。具体内容与abstract选项一样,参考模型继承章节。
required_db_features
声明模型依赖的数据库功能。比如['gis_enabled'],表示模型的建立依赖GIS功能。
required_db_vendor
声明模型支持的数据库。Django默认支持sqlite, postgresql, mysql, oracle。
select_on_save
决定是否使用1.6版本之前的django.db.models.Model.save()算法保存对象。默认值为False。这个选项我们通常不用关心。
indexes
Django1.11新增的选项。
接收一个应用在当前模型上的索引列表,如下例所示:
from django.db import models
class Customer(models.Model):
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
class Meta:
indexes = [
models.Index(fields=['last_name', 'first_name']),
models.Index(fields=['first_name'], name='first_name_idx'),
]
unique_together
这个元数据是非常重要的一个!它等同于数据库的联合约束!
举个例子,假设有一张用户表,保存有用户的姓名、出生日期、性别和籍贯等等信息。要求是所有的用户唯一不重复,可现在有好几个叫“张伟”的,如何区别它们呢?(不要和我说主键唯一,这里讨论的不是这个问题)
我们可以设置不能有两个用户在同一个地方同一时刻出生并且都叫“张伟”,使用这种联合约束,保证数据库能不能重复添加用户(也不要和我谈小概率问题)。在Django的模型中,如何实现这种约束呢?
使用unique_together,也就是联合唯一!
比如:
unique_together = (('name', 'birth_day', 'address'),)
联合唯一无法作用于普通的多对多字段。
index_together
即将废弃,使用index元数据代替。
verbose_name
最常用的元数据之一!用于设置模型对象的直观、人类可读的名称。可以用中文。例如:
verbose_name = "story" verbose_name = "披萨"
如果你不指定它,那么Django会使用小写的模型名作为默认值。
verbose_name_plural
英语有单数和复数形式。这个就是模型对象的复数名,比如“apples”。因为我们中文通常不区分单复数,所以保持和verbose_name一致也可以。
label
前面介绍的元数据都是可修改和设置的,但还有两个只读的元数据,label就是其中之一。
label等同于app_label.object_name。例如polls.Question,polls是应用名,Question是模型名。
label_lower
同上,不过是小写的模型名。
模型的继承
Django中所有的模型都必须继承django.db.models.Model模型,不管是直接继承也好,还是间接继承也罢。
你唯一需要决定的是,父模型是否是一个独立自主的,同样在数据库中创建数据表的模型,还是一个只用来保存子模型共有内容,并不实际创建数据表的抽象模型。
Django有三种继承的方式:
- 抽象基类:被用来继承的模型被称为
Abstract base classes,将子类共同的数据抽离出来,供子类继承重用,它不会创建实际的数据表; - 多表继承:
Multi-table inheritance,每一个模型都有自己的数据库表; - 代理模型:如果你只想修改模型的Python层面的行为,并不想改动模型的字段,可以使用代理模型。
抽象基类:
只需要在模型的Meta类里添加abstract=True元数据项,就可以将一个模型转换为抽象基类。Django不会为这种类创建实际的数据库表,它们也没有管理器,不能被实例化也无法直接保存,它们就是用来被继承的。抽象基类完全就是用来保存子模型们共有的内容部分,达到重用的目的。当它们被继承时,它们的字段会全部复制到子模型中。
from django.db import models
class CommonInfo(models.Model):
name = models.CharField(max_length=100)
age = models.PositiveIntegerField()
class Meta:
abstract = True
class Student(CommonInfo):
home_group = models.CharField(max_length=5)
Student模型将拥有name,age,home_group三个字段,并且CommonInfo模型不能当做一个正常的模型使用。
抽象基类的Meta数据:
如果子类没有声明自己的Meta类,那么它将继承抽象基类的Meta类。下面的例子则扩展了基类的Meta:
class CommonInfo(models.Model):
name = models.CharField(max_length=111)
class Meta:
abstract = True
class Student(CommonInfo):
group = models.CharField(max_length=55)
class Meta(CommonInfo.Meta):
db_table = 'student_info' # 不继承abstract
- 抽象基类中有的元数据,子模型没有的话,直接继承;
- 抽象基类中有的元数据,子模型也有的话,直接覆盖;
- 子模型可以额外添加元数据;
- 抽象基类中的
abstract=True这个元数据不会被继承。也就是说如果想让一个抽象基类的子模型,同样成为一个抽象基类,那你必须显式的在该子模型的Meta中同样声明一个abstract = True; - 有一些元数据对抽象基类无效,比如
db_table,首先是抽象基类本身不会创建数据表,其次它的所有子类也不会按照这个元数据来设置表名。
警惕related_name和related_query_name参数
如果在你的抽象基类中存在ForeignKey或者ManyToManyField字段,并且使用了related_name或者related_query_name参数,那么一定要小心了。因为按照默认规则,每一个子类都将拥有同样的字段,这显然会导致错误。为了解决这个问题,当你在抽象基类中使用related_name或者related_query_name参数时,它们两者的值中应该包含%(app_label)s和%(class)s部分:
%(class)s用字段所属子类的小写名替换%(app_label)s用子类所属app的小写名替换
例如,对于common/models.py模块:
class Base(models.Model):
m2m = models.ManyToManyField(
to=brand,
related_name="%(app_label)s_%(class)s_related",
related_query_name="%(app_label)s_%(class)ss",
)
class Meta:
abstract = True
class ChildA(Base):
ca = models.CharField(max_length=10)
class ChildB(Base):
pass
查看属性
>>> ChildA.m2m.field.attname 'm2m'
使用django_filter过滤数据
场景描述
有一个优惠券的表,跟衣服、食物、铭牌做关联
class Food(models.Model):
name = models.CharField(max_length=32)
coupon = GenericRelation("Coupon")
def __str__(self):
return self.name
class Cloth(models.Model):
name = models.CharField(max_length=32)
coupon = GenericRelation("Coupon", verbose_name="cloth_coupon")
def __str__(self):
return self.name
# 普通的外键只能指定一个表做关联
class brand(models.Model):
bid = models.IntegerField(primary_key=True, unique=True)
name = models.CharField(max_length=111)
class Coupon(models.Model):
"""
id food_id cloth_id ……
null null
1 null
"""
name = models.CharField("活动名称",max_length=64)
brief = models.TextField(blank=True,null=True,verbose_name="优惠券介绍")
brand = models.ForeignKey("brand",blank=True,null=True,on_delete=models.CASCADE)
content_type = models.ForeignKey(ContentType,blank=True,null=True, on_delete=models.CASCADE) # 代表哪个app下的哪张表(默认存储关系数据的表)
object_id = models.PositiveIntegerField("绑定商品",blank=True,null=True) # 代表哪张表中的对象id
content_obj = GenericForeignKey("content_type","object_id") #不会生成额外的列
def __str__(self):
return self.name
filters.py
from modelsPractice.models import Coupon
from django.db.models import Q
import django_filters
class CouponFilter(django_filters.FilterSet):
name = django_filters.CharFilter(lookup_expr='icontains')
brief = django_filters.CharFilter(lookup_expr='icontains')
search_all = django_filters.CharFilter(method='search') # 自定义查询
# content_obj__name = django_filters.CharFilter(lookup_expr='icontains') contentype类型的外键没做出来
brand__name = django_filters.CharFilter(lookup_expr='icontains') # 外键的定义方法
def search(self, queryset, status, value):
return queryset.filter(Q(name__icontains=value) | Q(brief__icontains=value))
class Meta:
model = Coupon
fields = ["name", "brief", "search_all", "brand__name"]
当使用模型查询时或者模糊查询时,前端通过GET 或者 POST方法把表单提交给后端,一般我们在view中直接通过ORM方式操作过滤:
views.py
from modelsPractice.filters import CouponFilter
def filter_test(request):
# 原来的方式
filter_name = request.GET.get('name')
filter_brief = request.GET.get('brief')
if (filter_name):
res = models.Coupon.objects.filter(name=name)
if (filter_brief):
res = res.filter(brief_icontains=filter_brief)
# 使用django_filter
objects = CouponFilter(request.GET,queryset=models.Coupon.objects.all())
recordFiltered = objects.qs.all()
# recordFiltered = objects.qs.count() # 数量
print(recordFiltered)
return HttpResponse(recordFiltered)
注意,不管是GET还是 POST,里面的参数名一定要跟filterSet里面定义的一样
数据库事务操作
Django框架提供了好几种方式来控制和管理数据库事务。
常用的事务处理方式是将每个请求都包裹在一个事务中。这个功能使用起来非常简单,你只需要将它的配置项ATOMIC_REQUESTS设置为True。
它是这样工作的:当有请求过来时,Django会在调用视图方法前开启一个事务。如果请求却正确处理并正确返回了结果,Django就会提交该事务。否则,Django会回滚该事务。
同样,你可以在视图代码中使用保存点来担任子事务的角色,典型的例子是atomic()上下文管理器。那么,最后所有更改要么被提交,要么被回滚。
警告!!!
虽然这种事务模式的优势在于它的简单性,但在访问量增长到一定的时候会造成很大的性能损耗。这是因为为每一个视图开启一个事物会有一些额外的开销。
另外,这种性能影响还取决于你的应用程序的查询模式以及你的数据库对锁的处理是否高效。
def atomic_test(request):
stop = request.GET.get("stop", "")
try:
with transaction.atomic():
object = models.brand.objects.get(bid=2)
object.name = u'祝高涛'
object.save()
models.shoes.objects.create(name='666', brand_id=2)
models.Food.objects.get(id=1).delete()
if stop == 'true':
raise MyException("transaction stop")
except Exception as e:
return HttpResponse(str(e))
else:
return HttpResponse("True")
当出现stop=true时,上面的操作都会被回滚
