python之路[1] - 基础1-迁
python环境
3、终端输出
\033[42m green light is on... \033[0m \033[41m red light is on... \033[0m
\033[显示方式;前景色;背景色m


# -*- set coding:utf-8 -*- ''' Created on 2014年9月22日 set name @author: Administrator test ''' STYLE = { 'fore': { 'black': 30, 'red': 31, 'green': 32, 'yellow': 33, 'blue': 34, 'purple': 35, 'cyan': 36, 'white': 37, }, 'back': { 'black': 40, 'red': 41, 'green': 42, 'yellow': 43, 'blue': 44, 'purple': 45, 'cyan': 46, 'white': 47, }, 'mode': { 'bold': 1, 'underline': 4, 'blink': 5, 'invert': 7, }, 'default': { 'end': 0, } } def use_style(string, mode='', fore='', back=''): mode = '%s' % STYLE['mode'][mode] if STYLE['mode'].has_key(mode) else '' fore = '%s' % STYLE['fore'][fore] if STYLE['fore'].has_key(fore) else '' back = '%s' % STYLE['back'][back] if STYLE['back'].has_key(back) else '' style = ';'.join([s for s in [mode, fore, back] if s]) style = '\033[%sm' % style if style else '' end = '\033[%sm' % STYLE['default']['end'] if style else '' return '%s%s%s' % (style, string, end) def test(): print use_style('Normal') print use_style('Bold', mode='bold') print use_style('Underline & red text', mode='underline', fore='red') print use_style('Invert & green back', mode='reverse', back='green') print use_style('Black text & White back', fore='black', back='white') if __name__ == '__main__': test()
使用format方法
>>> (''' {0} {1} {0} ''').format('123','3456')
'123 3456 123'
>>>"{warn_status}[{time}] {db_ip}({single_name}):{category}-{send_message}".format(**message)
message 是一个字典,注意输入的时候用**指定
用元祖输出
先把list强制转到tuple,list的顺序显示
"cd %s && ./isql.sh -U%s -P%s -h%s -O%s -o%s " % tuple(connlist)
4、Python 2 or 3?
In summary : Python 2.x is legacy, Python 3.x is the present and future of the language
print("There are <", 2**32, "> possibilities!", sep="")
ALL IS UNICODE NOW
从此不再为讨厌的字符编码而烦恼
还可以这样玩: (A,*REST,B)=RANGE(5)
<strong>>>> a,*rest,b = range(5) >>> a,rest,b (0, [1, 2, 3], 4) </strong>
某些库改名了
|
Old Name |
New Name |
|
_winreg |
winreg |
|
ConfigParser |
configparser |
|
copy_reg |
copyreg |
|
Queue |
queue |
|
SocketServer |
socketserver |
|
markupbase |
_markupbase |
|
repr |
reprlib |
|
test.test_support |
test.support |
在python3.6中有一个新的字符串格式化语法
>>> name = "Tom"
>>> age = 3
>>> f"His name is {name}, he's {age} years old."
>>> "His name is Tom, he's 3 years old."
5、.pyc是什么鬼
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
6、用户输入
####tab键补全,环境变量的脚本
.bashrc PYTHONSTARTUP=~/.pythonconf export PYTHONSTARTUP .pythonconf: import readline, rlcompleter import sys,os import atexit readline.parse_and_bind("tab: complete")
#!/usr/bin/env python
#_*_coding:utf-8_*_
#name = raw_input("What is your name?") #only on python 2.x
name = input("What is your name?")
print("Hello " + name )
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import getpass
# 将用户输入的内容赋值给 name 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print(pwd)
7、条件运算和循环

比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

运算符优先级:

条件表达式(即“三元操作符”)
y = 1 if x is not None else 0 如果x是None则y赋值0,如果x不是none则y为1
基本表达式
if elif else
any
>>> not any((1,0,0)) False >>> not any((0,0,0)) True if not any((p1,p2,p3))
循环:
while true:
do something
else:
do else something
8、如何调用python脚本
如何调用python脚本在实际情况中可能是遇到最多的,一些设置问题可能会trouble shooting一个下午而找不到原因,所以列了几个“规范”来杜绝这种低效的表现:
1 先用shell脚本调用python,把错误输出都输出到相关日志里面。这样的好处是如果python脚本没有定义好expect的话是抓不到错误输出的,还有环境变量造成的问题,这样就重定向了所有错误输出!
#!/bin/bash source /etc/profile MOBILE_NUMBER=$1 MESSAGE_UTF8=$2 python /etc/zabbix/alertscripts/sendsms.py $MOBILE_NUMBER $MESSAGE_ENCODE 2>>/tmp/myt 1>>/tmp/myt
2 main函数,把所有的错误输出记录到日志里面
if __name__ == "__main__":
try:
main(msg)
except Exception as e:
logger.error(str(e))
3 log日志,不要只打印到终端,也要打印到日志文件,并且日志文件最好写绝对目录!
LOG_FILE = os.path.abspath(os.path.dirname(__file__)) + '/' +'send_sms.log' 或者 LOG_FILE = '/tmp/send_sms.log'
4 注意脚本执行的权限
比如zabbix用户执行的,先su到zabbix用户下,执行看看
9 模块的导入
常规操作:
import Crypto.Cipher from Crypto.Cipher import AES from Crypto.Cipher import AES as myaes from .models import * #
动态模块导入
module = __import__(input_module_name) func = getattr(module, 'app') # app can be class_obj,variable,function
10 计算
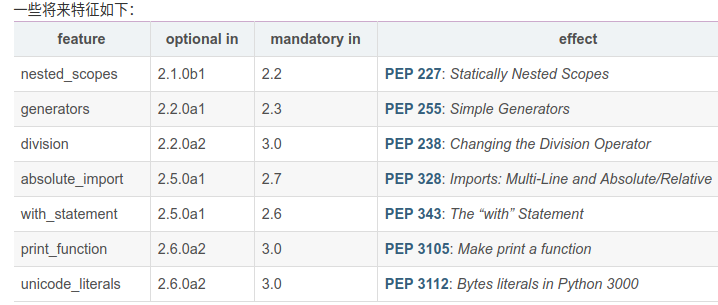
# 导入python未来支持的语言特征division(精确除法),当我们没有在程序中导入该特征时,"/"操作符执行的是截断除法(Truncating Division),当我们导入精确除法之后,"/"执行的是精确除法
from __future__ import division
#高精度使用decimal模块,配合getcontext
>>> from decimal import *
>>> print(getcontext())
Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, capitals=1, clamp=0, flags=[], traps=[InvalidOperation, DivisionByZero, Overflow])
>>> getcontext().prec = 50
>>> b = Decimal(1)/Decimal(3)
>>> b
Decimal('0.33333333333333333333333333333333333333333333333333')
>>> c = Decimal(1)/Decimal(17)
>>> c
Decimal('0.058823529411764705882352941176470588235294117647059')
>>> float(c)
0.058823529411764705
>>> from math import ceil, floor >>> round(2.5) # 这个不说了,前面已经讲过了。一定要注意它不是简单的四舍五入,而是ROUND_HALF_EVEN的策略。 2 >>> ceil(2.5) #注意py2环境下默认保留一位小数 3 >>> floor(2.5) 2 >>> round(2.3) 2 >>> ceil(2.3) # 取大于或者等于x的最小整数。 3 >>> floor(2.3) # 去小于或者等于x的最大整数 2 >>>

