python之路[2] - 基础2 - 迁
基础2
列表
是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作
定义列表
names = ['Alex',"Tenglan",'Eric']
切片:取多个元素
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 ['Tenglan', 'Eric', 'Rain'] >>> names[1:-1] #取下标1至-1的值,不包括-1 ['Tenglan', 'Eric', 'Rain', 'Tom'] >>> names[0:3] ['Alex', 'Tenglan', 'Eric'] >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 ['Alex', 'Tenglan', 'Eric'] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 ['Rain', 'Tom', 'Amy'] >>> names[3:-1] #这样-1就不会被包含了 ['Rain', 'Tom'] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 ['Alex', 'Eric', 'Tom'] >>> names[::2] #和上句效果一样 ['Alex', 'Eric', 'Tom'] >>> names[::-1] #列表取反 [...] >>> names[-3:] #取最后3个 ['Rain', 'Tom', 'Amy']
追加
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy']
>>> names.append("我是新来的")
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
插入
>>> names ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] >>> names.insert(2,"强行从Eric前面插入") >>> names ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] >>> names.insert(5,"从eric后面插入试试新姿势") >>> names ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
修改
>>> names ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的'] >>> names[2] = "该换人了" >>> names ['Alex', 'Tenglan', '该换人了', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
删除
>>> del names[2]
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
>>> del names[4]
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
>>>
>>> names.remove("Eric") #删除指定元素
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新来的']
>>> names.pop() #删除列表最后一个值 pop(0) 删除左边第一个元素即lpop()
'我是新来的'
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
扩展
>>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy'] >>> b = [1,2,3] >>> names.extend(b) >>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
拷贝
>>> names ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3] >>> name_copy = names.copy() >>> name_copy ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3] ===================== 深拷贝 >>> import copy >>> origin = [1, 2, [3, 4]] #origin 里边有三个元素:1, 2,[3, 4] >>> cop1 = copy.copy(origin) >>> cop2 = copy.deepcopy(origin) >>> cop1 == cop2 True >>> cop1 is cop2 False #cop1 和 cop2 看上去相同,但已不再是同一个object >>> origin[2][0] = "hey!" >>> origin [1, 2, ['hey!', 4]] >>> cop1 [1, 2, ['hey!', 4]] >>> cop2 [1, 2, [3, 4]] 可以看到 cop1,也就是 shallow copy 跟着 origin 改变了。而 cop2 ,也就是 deep copy 并没有变。
http://blog.csdn.net/qq_32907349/article/details/52190796
统计
>>> names
['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3]
>>> names.count("Amy")
2
排序&翻转
>>> names
['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3]
>>> names.sort() #排序
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦
>>> names[-3] = '1'
>>> names[-2] = '2'
>>> names[-1] = '3'
>>> names
['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '1', '2', '3']
>>> names.sort()
>>> names
['1', '2', '3', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom']
>>> names.reverse() #反转
>>> names
['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
# 对列表中的元祖的某个列排序
>>> a = [('2011-03-17', '2.26', 6429600, '0.0'), ('2011-03-16', '2.26', 12036900,'-3.0'),
('2011-03-15', '2.33', 15615500,'-19.1')]
>>> print a[0][0]
2011-03-17
>>> b = sorted(a, key=lambda result: result[1],reverse=True)
>>> print b
[('2011-03-15', '2.33', 15615500, '-19.1'), ('2011-03-17', '2.26', 6429600, '0.0'),
('2011-03-16', '2.26', 12036900, '-3.0')]
>>> c = sorted(a, key=lambda result: result[2],reverse=True)
>>> print c
[('2011-03-15', '2.33', 15615500, '-19.1'), ('2011-03-16', '2.26', 12036900, '-3.0'),
('2011-03-17', '2.26', 6429600, '0.0')]
获取下标
>>> names
['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
>>> names.index("Amy")
#只返回找到的第一个下标
# 获取索引
for index,item in enumerate(u)
元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index,完毕。
字符串操作
特性:不可修改
name.capitalize() 首字母大写 name.casefold() 大写全部变小写 name.center(50,"-") 输出 '---------------------Alex Li----------------------' name.count('lex') 统计 lex出现次数 name.encode() 将字符串编码成bytes格式 name.endswith("Li") 判断字符串是否以 Li结尾 "Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格 name.find('A') 查找A,找到返回其索引, 找不到返回-1 format : >>> msg = "my name is {}, and age is {}" >>> msg.format("alex",22) 'my name is alex, and age is 22' >>> msg = "my name is {1}, and age is {0}" >>> msg.format("alex",22) 'my name is 22, and age is alex' >>> msg = "my name is {name}, and age is {age}" >>> msg.format(age=22,name="ale") 'my name is ale, and age is 22' format_map >>> msg.format_map({'name':'alex','age':22}) 'my name is alex, and age is 22' msg.index('a') 返回a所在字符串的索引 '9aA'.isalnum() True '9'.isdigit() 是否整数 name.isnumeric name.isprintable name.isspace name.istitle name.isupper "|".join(['alex','jack','rain']) 'alex|jack|rain' maketrans >>> intab = "aeiou" #This is the string having actual characters. >>> outtab = "12345" #This is the string having corresponding mapping character >>> trantab = str.maketrans(intab, outtab) >>> >>> str = "this is string example....wow!!!" >>> str.translate(trantab) 'th3s 3s str3ng 2x1mpl2....w4w!!!' msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') >>> "alex li, chinese name is lijie".replace("li","LI",1) 'alex LI, chinese name is lijie' msg.swapcase 大小写互换 >>> msg.zfill(40) '00000my name is {name}, and age is {age}' >>> n4.ljust(40,"-") 'Hello 2orld-----------------------------' >>> n4.rjust(40,"-") '-----------------------------Hello 2orld' >>> b="ddefdsdff_哈哈" >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 True
字典操作
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
语法:
info = { 'stu1101': "TengLan Wu", 'stu1102': "LongZe Luola", 'stu1103': "XiaoZe Maliya", }
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重


>>> info["stu1104"] = "苍井空" >>> info {'stu1102': 'LongZe Luola', 'stu1104': '苍井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
>>> info['stu1101'] = "武藤兰" >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
>>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'} >>> info.pop("stu1101") #标准删除姿势 '武藤兰' >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} >>> del info['stu1103'] #换个姿势删除 >>> info {'stu1102': 'LongZe Luola'} >>> >>> >>> >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} >>> info {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #随机删除 >>> info.popitem() ('stu1102', 'LongZe Luola') >>> info {'stu1103': 'XiaoZe Maliya'}
字典查找
>>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
>>>
>>> "stu1102" in info #标准用法
True
>>> info.get("stu1102") #获取
'LongZe Luola'
>>> info["stu1102"] #同上,但是看下面
'LongZe Luola'
>>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'stu1105'
# Python 内建的 defaultdict
方法可以轻松定义一个树的数据结构(version => 2.5 )
from collections import defaultdict
def tree():
return defaultdict(tree)
users = tree()
users['harold']['username'] = 'hrldcpr'
users['handler']['username'] = 'matthandlersux'
print json.dumps(users)
#values
>>> info.values()
dict_values(['LongZe Luola', 'XiaoZe Maliya'])
#keys
>>> info.keys()
dict_keys(['stu1102', 'stu1103'])
#setdefault
>>> info.setdefault("stu1106","Alex")
'Alex'
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
>>> info.setdefault("stu1102","龙泽萝拉")
'LongZe Luola'
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
#update
>>> info
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
>>> b = {1:2,3:4, "stu1102":"龙泽萝拉"}
>>> info.update(b)
>>> info
{'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
#items
info.items()
dict_items([('stu1102', '龙泽萝拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')])
#通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个
>>> dict.fromkeys([1,2,3],'testd')
{1: 'testd', 2: 'testd', 3: 'testd'}
from collections import namedtuple
# 变量名和namedtuple中的第一个参数一般保持一致,但也可以不一样
Student = namedtuple('Student', 'id name score')
# 或者 Student = namedtuple('Student', ['id', 'name', 'score'])
students = [(1, 'Wu', 90), (2, 'Xing', 89), (3, 'Yuan', 98)]
循环和多级嵌套
#方法1
for key in info:
print(key,info[key])
#方法2
for k,v in info.items(): #会先把dict转成list,数据里大时莫用
print(k,v)
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
print(av_catalog["大陆"]["1024"])
#ouput
['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
字典排序
>>> from operator import itemgetter
>>> aa = {"a":"1","sss":"2","ffdf":'5',"ffff2":'3'}
>>> sort_aa = sorted(aa.items(),key=itemgetter(1))
>>> sort_aa
[('a', '1'), ('sss', '2'), ('ffff2', '3'), ('ffdf', '5')]
python 3 中的字典
在python3中,字典操作的变化比较大
d = {"a":"111", "b":"222", "c":"kkk"}
>>> d.keys()
dict_keys(['a', 'b', 'c']) # 返回的是一个dict_keys类型,没有index
>>> list(d.keys()) # 转成list
['a', 'b', 'c']
# 将字典根据key排序
d = {"a":"111", "b":"222","d":"32s" ,"c":"kkk"}
order_d = dict(sorted(d.items(), key=lambda x: x[0]))
>>> order_d
{'a': '111', 'b': '222', 'c': 'kkk', 'd': '32s'}
集合操作
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
常用操作
s = set([3,5,9,10]) #创建一个数值集合
t = set("Hello") #创建一个唯一字符的集合
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
基本操作:
t.add('x') # 添加一项
s.update([10,37,42]) # 在s中添加多项
使用remove()可以删除一项:
t.remove('H')
len(s)
set 的长度
x in s
测试 x 是否是 s 的成员
x not in s
测试 x 是否不是 s 的成员
s.issubset(t)
s <= t
测试是否 s 中的每一个元素都在 t 中
s.issuperset(t)
s >= t
测试是否 t 中的每一个元素都在 s 中
s.union(t)
s | t
返回一个新的 set 包含 s 和 t 中的每一个元素
s.intersection(t)
s & t
返回一个新的 set 包含 s 和 t 中的公共元素
s.difference(t)
s - t
返回一个新的 set 包含 s 中有但是 t 中没有的元素
s.symmetric_difference(t)
s ^ t
返回一个新的 set 包含 s 和 t 中不重复的元素
s.copy()
返回 set “s”的一个浅复制
s.pop()
删除最左并返回元素
s.clear()
清空元素
set()
字符串/元组/列表/字典转换
#1、字典
dict = {'name': 'Zara', 'age': 7, 'class': 'First'}
#字典转为字符串,返回:<type 'str'> {'age': 7, 'name': 'Zara', 'class': 'First'}
print type(str(dict)), str(dict)
#字典可以转为元组,返回:('age', 'name', 'class')
print tuple(dict)
#字典可以转为元组,返回:(7, 'Zara', 'First')
print tuple(dict.values())
#字典转为列表,返回:['age', 'name', 'class']
print list(dict)
#字典转为列表
print dict.values
#2、元组
tup=(1, 2, 3, 4, 5)
#元组转为字符串,返回:(1, 2, 3, 4, 5)
print tup.__str__()
#元组转为列表,返回:[1, 2, 3, 4, 5]
print list(tup)
#元组转为字典
tup=((1,2),(3,4))
>>> [ {i:j} for i,j in tup ]
[{1: 2}, {3: 4}]
#3、列表
nums=[1, 3, 5, 7, 8, 13, 20];
#列表转为字符串,返回:[1, 3, 5, 7, 8, 13, 20]
print str(nums)
#列表转为元组,返回:(1, 3, 5, 7, 8, 13, 20)
print tuple(nums)
#列表不能直接转为字典
#4、字符串
#字符串转为元组,返回:(1, 2, 3)
print tuple(eval("(1,2,3)"))
#字符串转为列表,返回:[1, 2, 3]
print list(eval("(1,2,3)"))
#字符串转为字典,返回:<type 'dict'>
print type(eval("{'name':'ljq', 'age':24}"))
文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
open 基本操作
f = open('lyrics') #打开文件 first_line = f.readline() print('first line:',first_line) #读一行 print('我是分隔线'.center(50,'-')) data = f.read()# 读取剩下的所有内容,文件大时不要用 print(data) #打印文件 f.close() #关闭文件
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
其他方式
seek(offset, [whence]) 可以在文件中移动文件指针到不同的位置 offset: 文件的读/写指针位置. [whence]就以whence设定的起始位为准,0代表从头开始,1代表当前位置,2代表文件最末尾位置。 seek(0) 移动到头文件 seek(-1,2) 移动到文件末尾,第-1个字符 tell() 游标在文件当前位置
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f:
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2: pass
强烈建议使用 linecache
行-缓存,这对于读取内容非常多的文件,效果甚好,而且它还可以读取指定的行内容
linecache.getlines(filename)
从名为filename的文件中得到全部内容,输出为列表格式,以文件每行为列表中的一个元素,并以linenum-1为元素在列表中的位置存储
# 取文件的最后5行
linecache.getlines(filename)[-5:]
linecache.getline(filename,lineno)
从名为filename的文件中得到第lineno行。这个函数从不会抛出一个异常–产生错误时它将返回”(换行符将包含在找到的行里)。
如果文件没有找到,这个函数将会在sys.path搜索。
# 取文件的第222行,当然可以先len(f.readlines())获取所有行数 linecache.getline(filename,222)
linecache.clearcache()
清除缓存。如果你不再需要先前从getline()中得到的行
linecache.checkcache(filename)
检查缓存的有效性。如果在缓存中的文件在硬盘上发生了变化,并且你需要更新版本,使用这个函数。如果省略filename,将检查缓存里的所有条目。
linecache.updatecache(filename)
更新文件名为filename的缓存。如果filename文件更新了,使用这个函数可以更新linecache.getlines(filename)返回的列表。
如何tail -f一个文件
有两种方法,推荐用迭代器的方式
import time
def follow(thefile):
thefile.seek(0,2) # Go to the end of the file
while True:
line = thefile.readline()
if not line:
time.sleep(0.1) # Sleep briefly
continue
yield line
logfile = open(filename)
loglines = follow(logfile)
for line in loglines:
print line
import time
import subprocess
import select
filename='/tmp/123'
f = subprocess.Popen(['tail','-F',filename],\
stdout=subprocess.PIPE,stderr=subprocess.PIPE)
p = select.poll()
p.register(f.stdout)
while True:
if p.poll(1):
print f.stdout.readline()
time.sleep(0.1)
字符编码
py2和py3的不同点
|
需知: 1.在python2默认编码是ASCII, python3里默认是unicode 2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间 3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string |
asic 255 1bytes --> gb2312 -- [1980 7200多个汉字] --> gbk [ 1995 21886 ] --> gb18030 [2000 27484] --> unicode [统一码 万国码 ] --> utf-8 en:1byte zh:3byte ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。py2默认字符编码 unicode能表示所有的数字、字符、中文等等,用2个字节表示一个字母 gbk可以转成unicode,utf-8也能转成unicode utf-8是unicode的扩展,用1个字节表示英文字母,用3个字节表示中文,py3默认字符密码 gbk只有中国有,表示中文汉字,向下兼容gb2312 gb18030 关于中文 为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。 GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。 GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。 从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。 有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
先说python2
- py2里默认编码是ascii
- 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
- 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
- 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
- utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk
再说python3
- py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了
- 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
- 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是encode的数据变成了bytes里,我擦,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)
- 在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名(python2里的str就是bytes, py3里的str是unicode),没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'\xe4\xbd\xa0\xe5\xa5\xbd' bytes类型-->按照指定编码转成你能看懂的文字
编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
编码转换
utf-8 与 unicode 的转换
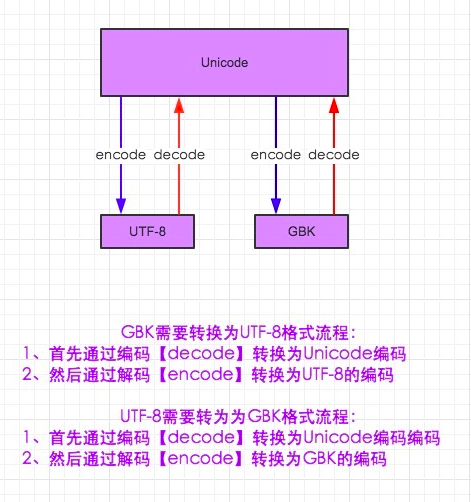
上图仅适用于py2
#print('alvin'+u'yuan')#字节串和unicode连接 py2:alvinyuan print(b'alvin'+'yuan')#字节串和unicode连接 py3:报错 can't concat bytes to str
py2默认ASCII码,py3默认的utf8,可以通过如下方式查询
import sys print(sys.getdefaultencoding()) #######修改默认编码######### reload(sys)
sys.setdefaultencoding('utf8')
#-*-coding:utf-8-*- __author__ = 'Alex Li' import sys print(sys.getdefaultencoding()) msg = "我爱北京天安门" msg_gb2312 = msg.decode("utf-8").encode("gb2312") gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") print(msg) print(msg_gb2312) print(gb2312_to_gbk) in python2
#-*-coding:gb2312 -*- #这个也可以去掉 __author__ = 'Alex Li' import sys print(sys.getdefaultencoding()) msg = "我爱北京天安门" #msg_gb2312 = msg.decode("utf-8").encode("gb2312") msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔 gb2312_to_unicode = msg_gb2312.decode("gb2312") gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") print(msg) print(msg_gb2312) print(gb2312_to_unicode) print(gb2312_to_utf8) in python3
利用json中的dumps,将unicode转为utf-8,直观的感受就是把json中的中文字符从unicode转为utf-8
print json.dumps({'data':url_json},encoding='utf-8',ensure_ascii=False,sort_keys=True,indent=4,separators=(',',':'))
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
bytes 和 str的转换
# bytes object b = b"example" # str object s = "example" # str to bytes sb = bytes(s, encoding = "utf8") # bytes to str bs = str(b, encoding = "utf8") # an alternative method # str to bytes sb2 = str.encode(s) # bytes to str (常用) bs2 = bytes.decode(b)
加密解密
基础的base64加密解密
byte类型
>>> import base64 >>> x = base64.b64encode(b'test') >>> x b'dGVzdA==' >>> base64.b64decode(x) b'test'
string类型
base64.encodestring(text).strip() # 返回的是一个string类型 base64.decodestring(text)
使用ASE的 cbc模式加解密
class PyCrypt(object):
def __init__(self, key):
self.key = self.iv = key
# self.iv = b"8155ca7d906ad5e1" # 偏移量可选参数
self.mode = AES.MODE_CBC
#加密函数,如果text不是16的倍数【加密文本text必须为16的倍数!】,那就补足为16的倍数
def encrypt(self, text):
cryptor = AES.new(self.key, self.mode, self.iv)
#这里密钥key 长度必须为16(AES-128)、24(AES-192)、或32(AES-256)Bytes 长度.目前AES-128足够用
length = 16
count = len(text)
if(count % length != 0):
add = length - (count % length)
else:
add = 0
text = text + ('\0' * add)
self.ciphertext = cryptor.encrypt(text)
#因为AES加密时候得到的字符串不一定是ascii字符集的,输出到终端或者保存时候可能存在问题
##所以这里统一把加密后的字符串转化为16进制字符串 ,当然也可以转换为base64加密的内容,可以使用b2a_base64(self.ciphertext)
return b2a_hex(self.ciphertext)
#解密后,去掉补足的空格用strip() 去掉
def decrypt(self, text):
"""
decrypt pass base the same key
对称加密之解密,同一个加密随机数
"""
cryptor = AES.new(self.key, self.mode, self.iv)
try:
plain_text = cryptor.decrypt(a2b_hex(text))
except TypeError:
raise ServerError('Decrypt password error, TYpe error.')
return plain_text.rstrip('\0')
def encodeb64(self,text):
return base64.encodestring(text).strip()
def decodeb64(self,text):
return base64.decodestring(text)
if __name__ == '__main__':
# pc = PyCrypt('tmppasswordver1.') #初始化密钥
pc = PyCrypt('tmppasswordver1.') #初始化密钥
e = pc.encrypt("MLhuored@2018") # 要加密的字符串
d = pc.decrypt(e)
print e, d
e = pc.encrypt("00000000000000000000000000")
d = pc.decrypt(e)
print pc.encodeb64("MLhuored@2018")
print e, d
使用 AES 的 ECB模式+base64
class AESCrypt(object):
"""docstring for ClassName"""
def __init__(self, key):
# self.iv 偏移量
self.key = key
self.mode = AES.MODE_ECB
def encrypt(self, text):
# PKS7
bs = AES.block_size
pad = lambda s: s + (bs - len(s) % bs) * chr(bs - len(s) % bs)#PKS7
try:
cryptor = AES.new(self.key, self.mode) # ECB模式无需向量iv
self.ciphertext = cryptor.encrypt(pad(text))
return base64.b64encode(self.ciphertext) # 对结果再做一个base64
except Exception as e:
return u"加密失败,失败原因[%s]" % str(e)
def decrypt_opt(self, text):
cryptor = AES.new(self.key, self.mode) # ECB模式无需向量iv
text += (len(text) % 4) * '='
try:
# print text,"text"
decrypt_bytes = base64.b64decode(text)
# print decrypt_bytes,"decrypt_bytes"
meg = cryptor.decrypt(decrypt_bytes)
# 去掉解码后的非法字符
result = re.compile('[\\x00-\\x08\\x0b-\\x0c\\x0e-\\x1f\n\r\t]').sub('', meg.decode())
return result
except Exception as e:
return u"解密失败,失败原因[%s]" % str(e)
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...")
print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass
def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass
'''
import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest())
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
使用md5对比文件和文件夹
import hashlib
import os, fnmatch
class CompareFile(object):
"""
比较两个文件或者目录的不同
"""
def calMD5(self, entry):
md5 = hashlib.md5()
if os.path.isfile(entry):
md5.update(open(entry, 'rb').read())
elif os.path.isdir(entry):
for path, dirList, fileList in os.walk(entry):
for file in fileList:
if fnmatch.fnmatch(file, '*.py'):
md5.update(open(os.path.join(path, file), 'rb').read())
return md5.hexdigest()
def compare(self, intry, entry):
return self.calMD5(intry) == self.calMD5(entry)
c = CompareFile()
print c.compare('/home/richard/Work/PythonLearn/practice/BaseHttp/PostJson.py','/home/richard/Work/PythonLearn/practice/BaseHttp/PostJson.py_1')
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hmac h = hmac.new(b'天王盖地虎', b'宝塔镇河妖') print h.hexdigest()

