python之路[3] - 正则表达式和函数基础 - 迁
正则表达式
text = "JGood is a handsome boy, he is cool, clever, and so on..."re.compile(pattern,flags=0) -- 设置匹配规则 re.match(pattern,string, flags=0) -- 字符串的开头是否能匹配正则表达式re.search(pattern,string, flags=0) -- 在字符串中查找,是否能匹配正则表达式re.findall(pattern,string[,flags]) -- 返回匹配的所有子串,并把它们作为一个列表返回。这个匹配是从左到右有序地返回,它是没有group()的
re.splitall() -- 以匹配到的字符当做列表分隔符
re.sub(pattern,) -- 匹配字符并替换
下面我们一起看下他们的用法
re.findall('\w+oo\w+',text)
['JGood', 'cool']
re.match('(a(b))', 'ab').groups()
('ab', 'b')
mo=re.compile(r'(?<=SRC=)"([\W+\.]+)"',re.I)
>> mo.sub(r'"\1*****"', line) # 把匹配到字符串后面加××××× ,\1是匹配到的数据
常用正则表达式
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
# 匹配所有汉字
print(re.findall('[\u4e00-\u9fa5]', data))
# 匹配所有单字符,英文,数字,特殊符号
print(re.findall('[\x00-\xff]', data))
# 匹配所有非单字符,入汉字和省略号
print(re.findall('[^\x00-\xff]', data))
'(?P<name>...)' 分组匹配
re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict()
结果{'province': '3714', 'city': '81', 'birthday': '1993'}
转义
| 反斜杠的困扰 与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。 |
匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图) S(DOTALL): 点任意匹配模式,改变'.'的行为
贪婪匹配
.+(\d+-\d+-\d+)
.+ 是贪婪匹配,会将 dfd:1171590364-6-8 匹配成 4-6-8
这时候利用? 非贪婪操作符 .+?(\d+-\d+-\d+) 就能匹配成1171590364-6-8
场合应用


1 密码的强度必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间 ^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ 2 字符串只能是中文 ^[\\u4e00-\\u9fa5]{0,}$ 3 校验E-Mail 地址 [\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])? 4 校验身份证号码 15位: ^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$ 18位: ^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$ 5 校验日期 “yyyy-mm-dd“ 格式的日期校验,已考虑平闰年 ^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ 6 校验金额 金额校验,精确到2位小数 ^[0-9]+(.[0-9]{2})?$ 7 校验手机号 下面是国内 13、15、18开头的手机号正则表达式 ^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$ 8 判断IE的版本 ^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$ 9 校验IP-v4地址 \\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b 10 匹配01- 12月 re.match('(0[1-9])?(1[1-2])?',s).group()
函数
定义
函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
函数参数与局部变量
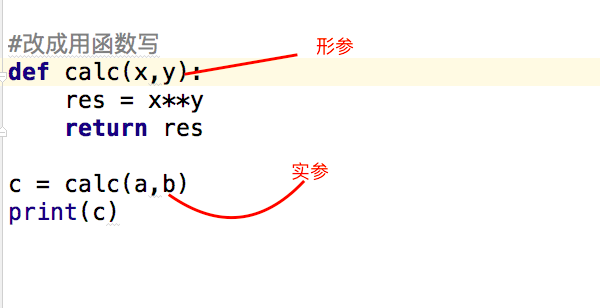
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
def stu_register(name,age,course,country="CN"): def stu_register(age=22,name='alex',course="python",)
非固定参数
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs) stu_register("Alex",22) #输出 #Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空 stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong") #输出 # Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'}
全局与局部变量
name = "gaotao" #全局变量 def change_name(name): global car car = "ford" # 全局变量 print("before change:",name) name = "帅帅" # 局部变量 print("after change", name) change_name(name) print(car)
嵌套函数
name = "gaotao" def change_name(): name = "gaotao2" def change_name2(): name = "gaotao3" print("3",name) change_name2() #调用内层函数 print("2",name) change_name() print("outhear",name)
输出:
('3', 'gaotao3')
('2', 'gaotao2')
('outhear', 'gaotao')
递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def calc(n): print(n) if int(n/2) ==0: return n return calc(int(n/2)) calc(10) 输出: 10 5 2 1
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] def binary_search(dataset,find_num): print(dataset) if len(dataset) >1: mid = int(len(dataset)/2) if dataset[mid] == find_num: #find it print("找到数字",dataset[mid]) elif dataset[mid] > find_num :# 找的数在mid左面 print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid]) return binary_search(dataset[0:mid], find_num) else:# 找的数在mid右面 print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid]) return binary_search(dataset[mid+1:],find_num) else: if dataset[0] == find_num: #find it print("找到数字啦",dataset[0]) else: print("没的分了,要找的数字[%s]不在列表里" % find_num) binary_search(data,66)
利用递归将 字典扁平化
REST=[]
def dict2kv(vdict,str_key="",split_pot=":",startwith=None):
if isinstance(vdict,(dict,)):
for k,v in vdict.items():
tmp_key = str_key+split_pot+k
dict2kv(vdict=vdict[k],str_key=tmp_key,split_pot=split_pot,startwith=startwith)
else:
_key = "%s%s" % (startwith,str_key)
REST.append({_key:vdict})
str_key = ""
return 0
注意REST是全局变量,如果重复调用dict2kv,需要每次循环前置空
调用结果
vdict = {
'nihao':{
'1':'sdf',
'2ss':'w3d'
},
'ch':{
'hhe':{
'zen':'33'
}
}
}
dict2kv(vdict,startwith="DATASOURCE_STATUS")
>> [{'DATASOURCE_STATUS:ch:hhe:zen': '33'},
{'DATASOURCE_STATUS:nihao:1': 'sdf'},
{'DATASOURCE_STATUS:nihao:2ss': 'w3d'}]
os.walk 模块就是很好的递归函数事例
def walk(top, topdown=True, onerror=None, followlinks=False):
islink, join, isdir = path.islink, path.join, path.isdir
try:
# Note that listdir and error are globals in this module due
# to earlier import-*.
names = listdir(top)
except error, err:
if onerror is not None:
onerror(err)
return
dirs, nondirs = [], []
for name in names:
if isdir(join(top, name)):
dirs.append(name)
else:
nondirs.append(name)
if topdown:
yield top, dirs, nondirs
for name in dirs:
new_path = join(top, name)
if followlinks or not islink(new_path):
for x in walk(new_path, topdown, onerror, followlinks):
yield x
if not topdown:
yield top, dirs, nondirs
内置参数

内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii

