



初步评测世界上最快的脚本引擎的解释器执行效率 —— EUPHORIA, Lua,以及俺写的TurboScript解释器核心原型【也许会开源】。
衡量脚本引擎效率,对于非JITter执行的解释型脚本来说,解释器本身的执行效率就是核心的核心,关键之关键了。
总所周知,解释的速度慢于编译的原因就是,因为多了一道工序,指令必须经过解释才能执行。要想提高解释器的
性能,自然是要尽量缩短解释的过程。这个解释的过程就是空耗了,也就是我们平时说的做的无用功。因此,这里
将以编译执行的速度视为空耗为0,以它作为基准,对解释器的效率进行比较。
用什么指令来测试呢,就挑一个最简单的整数加法运算,两数相加,绝大多数脚本都该支持的。由于机器码执行速度
太快,如果只重复执行几次,就算是用高性能计数器也无法计时,所以这里将重复执行2017次加法指令,以300累加,
结果为300*2017。测试全部采用 QueryPerformanceCounter 高精度计数。
在解释器直接执行VM指令的效率之后,我们还想测试下解释器做过程调用的效率,毕竟在实际应用中大部分都是执行的
过程调用(虚方法这些更是过程的升华,当然由于虚方法要查表所以又要比调用普通过程慢)。就将加法指令放到子过
程中,就可以测试了。
其实如果脚本引擎都能实现一个空指令那么就能精确的看出解释器的空耗了!就不比这样麻烦了。
== 速度效率图 ==
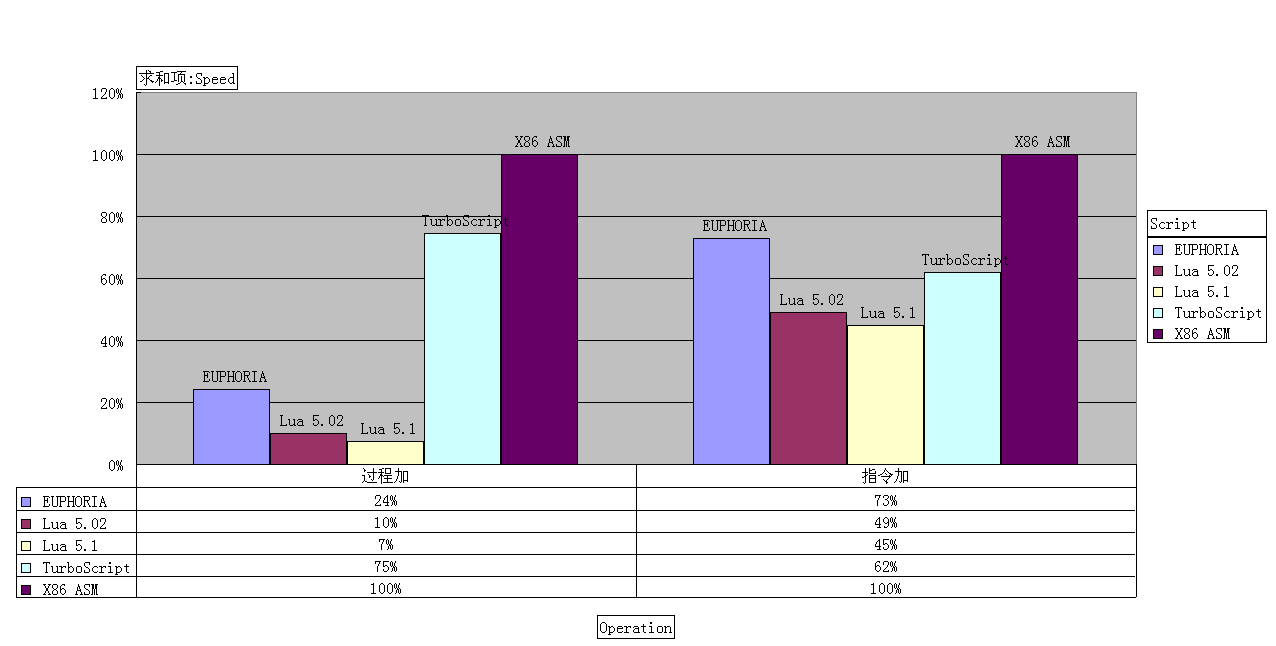
该图以x86汇编为基准计算。从图中我们可以看出,EUPHORIA解释器在直接指令执行这块运行性能最高,达到了x86指令
执行速度的73%,也就是说它的空耗只有27%。
实际上 Lua 是用Float实现的整数的运算,在它的数字类型实现中,其实在内部只有浮点类型,所以在执行上占了劣势。
而EUPHORIA则在内部专门实现了整数类型,不过奇怪的是它就没有专门实现浮点类型了,剩下的就全部是用atom类型进
行扩充的。所以这个加法的执行效率还和虚拟机的架构大有关系。另外Lua子过程调用的效率太低,应该还有很大提升余地。
至于俺的TurboScript架构则是类似于 CLR 的架构——面向堆栈的32位虚拟机,所以占了不用传递参数的便宜,再加上
TurboScript解释器则又是用高度优化的x86嵌入汇编写的,这是TurboScript解释器运行高性能的原因。
后面是测试脚本以及结果。
== 直接指令执行效率测试 ==
=== x86汇编基准效率 ===
<code>
;计时开始
MOV EBX, 300 BB2C010000
ADD EBX, 300 81C32C010000
..... --- 总计 2017 次
ADD EBX, 300 81C32C010000
;计时结束
</code>
结果运行时间:54; 这里以其为基准,视其为速度为 = 100%; 空耗为0%
=== Lua Script 脚本 ===
<code>
(计时开始)
local count = 300
count = count + 300
..... (总计 2017 次)
count = count + 300
(计时结束)
</code>
【Lua5.0.2】运行时间: 110;是x86执行速度的49%;空耗为51%
【Lua5.1 】 运行时间: 120;是x86执行速度的45%;空耗为55%
=== EUPHORIA 加法指令顺序执行效率测试脚本 ===
<code>
--计时开始
count = 300
count +=300
..... --- 总计 2017 次
count +=300
--计时结束
</code>
结果运行时间:74 ;是x86执行速度的73%;空耗为27%
=== TurboScript 脚本 ===
<code>
//计时开始
300 //Push 300 to the data stack.
300 +
..... (总计 2017 次)
300 +
//(计时结束
</code>
结果运行时间:87;是x86执行速度的62%;空耗为38%
== 子过程调用的性能 ==
=== x86 汇编 子过程调用效率基准测试脚本 ===
<code>
function add(a,b: integer): integer;
asm
mov EAX, a
add EAX, b
end;
--计时开始
asm
mOV EAX, 300
MOV EDX, 300 CALL ADD
..... (总计 2017 次)
MOV EDX, 300 CALL ADD
--计时结束
</code>
结果运行时间:126
=== Lua Script 脚本 ===
<code>
function iAdd(a, b)
return a+b
end function
(计时开始)
local count = 300
count = iAdd(count, 300)
..... (总计 2017 次)
count = iAdd(count, 300)
(计时结束)
</code>
【Lua5.0.2】 运行时间:1270;是x86执行速度的10%;空耗为90%
【Lua5.1 】 运行时间:1820;是x86执行速度的7%;空耗为93%
=== EUPHORIA 子过程调用效率测试脚本 ===
<code>
function iAdd(integer a, integer b)
return a+b
end function
--计时开始
count = 300
count = iAdd(count, 300)
..... --- 总计 2017 次
count = iAdd(count, 300)
--计时结束
</code>
结果运行时间:522;是x86执行速度的24%;空耗为76%
=== TurboScript 子过程近调用效率测试 ===
<code>
: Add +; //定义子过程。
//--计时开始
300
300 Add
..... (总计 2017 次)
300 Add
//--计时结束
</code>
结果运行时间:169;是x86执行速度的75%;空耗为25%
最后附上: 完整的测试脚本和相关程序下载
衡量脚本引擎效率,对于非JITter执行的解释型脚本来说,解释器本身的执行效率就是核心的核心,关键之关键了。
总所周知,解释的速度慢于编译的原因就是,因为多了一道工序,指令必须经过解释才能执行。要想提高解释器的
性能,自然是要尽量缩短解释的过程。这个解释的过程就是空耗了,也就是我们平时说的做的无用功。因此,这里
将以编译执行的速度视为空耗为0,以它作为基准,对解释器的效率进行比较。
用什么指令来测试呢,就挑一个最简单的整数加法运算,两数相加,绝大多数脚本都该支持的。由于机器码执行速度
太快,如果只重复执行几次,就算是用高性能计数器也无法计时,所以这里将重复执行2017次加法指令,以300累加,
结果为300*2017。测试全部采用 QueryPerformanceCounter 高精度计数。
在解释器直接执行VM指令的效率之后,我们还想测试下解释器做过程调用的效率,毕竟在实际应用中大部分都是执行的
过程调用(虚方法这些更是过程的升华,当然由于虚方法要查表所以又要比调用普通过程慢)。就将加法指令放到子过
程中,就可以测试了。
其实如果脚本引擎都能实现一个空指令那么就能精确的看出解释器的空耗了!就不比这样麻烦了。
== 速度效率图 ==
该图以x86汇编为基准计算。从图中我们可以看出,EUPHORIA解释器在直接指令执行这块运行性能最高,达到了x86指令
执行速度的73%,也就是说它的空耗只有27%。
实际上 Lua 是用Float实现的整数的运算,在它的数字类型实现中,其实在内部只有浮点类型,所以在执行上占了劣势。
而EUPHORIA则在内部专门实现了整数类型,不过奇怪的是它就没有专门实现浮点类型了,剩下的就全部是用atom类型进
行扩充的。所以这个加法的执行效率还和虚拟机的架构大有关系。另外Lua子过程调用的效率太低,应该还有很大提升余地。
至于俺的TurboScript架构则是类似于 CLR 的架构——面向堆栈的32位虚拟机,所以占了不用传递参数的便宜,再加上
TurboScript解释器则又是用高度优化的x86嵌入汇编写的,这是TurboScript解释器运行高性能的原因。
后面是测试脚本以及结果。
== 直接指令执行效率测试 ==
=== x86汇编基准效率 ===
<code>
;计时开始
MOV EBX, 300 BB2C010000
ADD EBX, 300 81C32C010000
..... --- 总计 2017 次
ADD EBX, 300 81C32C010000
;计时结束
</code>
结果运行时间:54; 这里以其为基准,视其为速度为 = 100%; 空耗为0%
=== Lua Script 脚本 ===
<code>
(计时开始)
local count = 300
count = count + 300
..... (总计 2017 次)
count = count + 300
(计时结束)
</code>
【Lua5.0.2】运行时间: 110;是x86执行速度的49%;空耗为51%
【Lua5.1 】 运行时间: 120;是x86执行速度的45%;空耗为55%
=== EUPHORIA 加法指令顺序执行效率测试脚本 ===
<code>
--计时开始
count = 300
count +=300
..... --- 总计 2017 次
count +=300
--计时结束
</code>
结果运行时间:74 ;是x86执行速度的73%;空耗为27%
=== TurboScript 脚本 ===
<code>
//计时开始
300 //Push 300 to the data stack.
300 +
..... (总计 2017 次)
300 +
//(计时结束
</code>
结果运行时间:87;是x86执行速度的62%;空耗为38%
== 子过程调用的性能 ==
=== x86 汇编 子过程调用效率基准测试脚本 ===
<code>
function add(a,b: integer): integer;
asm
mov EAX, a
add EAX, b
end;
--计时开始
asm
mOV EAX, 300
MOV EDX, 300 CALL ADD
..... (总计 2017 次)
MOV EDX, 300 CALL ADD
--计时结束
</code>
结果运行时间:126
=== Lua Script 脚本 ===
<code>
function iAdd(a, b)
return a+b
end function
(计时开始)
local count = 300
count = iAdd(count, 300)
..... (总计 2017 次)
count = iAdd(count, 300)
(计时结束)
</code>
【Lua5.0.2】 运行时间:1270;是x86执行速度的10%;空耗为90%
【Lua5.1 】 运行时间:1820;是x86执行速度的7%;空耗为93%
=== EUPHORIA 子过程调用效率测试脚本 ===
<code>
function iAdd(integer a, integer b)
return a+b
end function
--计时开始
count = 300
count = iAdd(count, 300)
..... --- 总计 2017 次
count = iAdd(count, 300)
--计时结束
</code>
结果运行时间:522;是x86执行速度的24%;空耗为76%
=== TurboScript 子过程近调用效率测试 ===
<code>
: Add +; //定义子过程。
//--计时开始
300
300 Add
..... (总计 2017 次)
300 Add
//--计时结束
</code>
结果运行时间:169;是x86执行速度的75%;空耗为25%
最后附上: 完整的测试脚本和相关程序下载

