
JSDom
DOM
文档对象模型(DOM)可以将web页面和脚本或编程语言连接起来
1. 这里的web页面,也就是我们之前用HTML和CSS绘制的页面,也称作为文档
2. 脚本或编程语言。是因为DOM是一种规范,或者是一种约定,只要遵循这个约定,那么无论是JS,.还是python,或者java都可以被联系起来
DOM映射
实际上像HTML和XML这种形式的文档都是树状结构,也对应数据结构中的树
比如这个页面:
<html>
<head>
<title>youkeda</title>
</head>
<body>
<div>
<h1>优课达</h1>
<p>学的比别人好一点</p>
</div>
</body>
</html>
转换为树就是
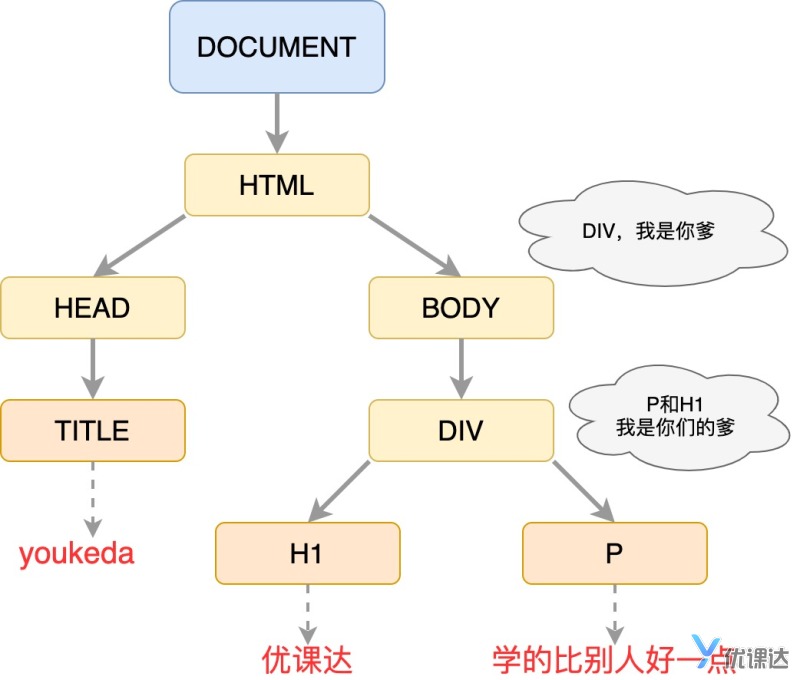
图示是倒着的树,最顶上称为树根,这棵树就是DOM树
DOM树特征:
1. 树根是DOCUMENT,也可以称为整个页面文档
2. 每个HTML标签被称之为DOM节点,英文为Node或者Element
3. 每个HTML标签包裹的子标签,在树上体现为分支,称为儿子节点
4. 类推可以得到孙子节点
5. 谁的长辈就被称为祖先节点
6. 亲兄弟就被称为兄弟节点
访问DOM
获取DOCUMENT
DOM树连接JS和网页,访问DOCUMENT:window.document;
打印出来:
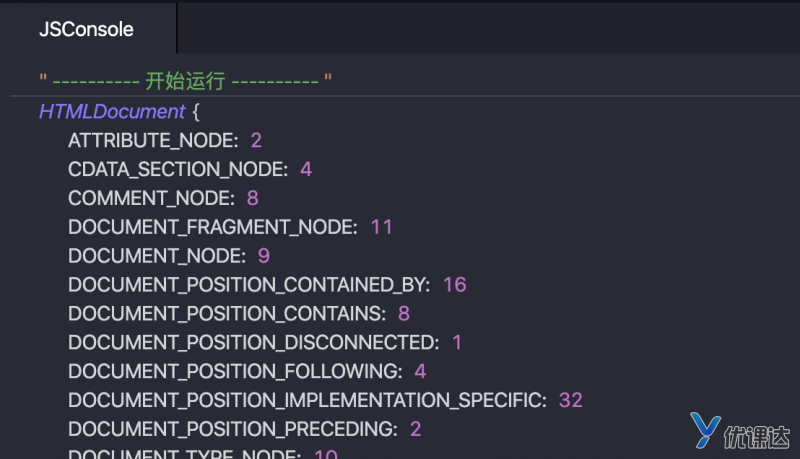
得到一个HTMLDocument对象,document内容key为documentElement
网页开发者工具中的console中出现的#document是经过处理的,也就是整个HTML内容
选择器查询
获取某一个特殊节点
比如这个HTML页面:
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<link rel="stylesheet" type="text/css" href="./index.css" />
<title>QQ注册</title>
</head>
<body>
<nav class="nav">
<a class="qq">
<img src="https://document.youkeda.com/P3-1-HTML-CSS/1.9/3-qq/qq.png?x-oss-process=image/resize,w_800/watermark,image_d2F0ZXJtYXNrLnBuZz94LW9zcy1wcm9jZXNzPWltYWdlL3Jlc2l6ZSx3XzEwMA==,t_60,g_se,x_10,y_10" />
<span>QQ</span>
</a>
<ul class="right">
<li class="bright">
<img
src="https://document.youkeda.com/P3-1-HTML-CSS/1.9/3-qq/bright.png"
alt="QQ靓号"
/>
</li>
<li class="language">
<span>简体中文</span>
<img
class="arrow"
src="https://document.youkeda.com/P3-1-HTML-CSS/1.9/3-qq/arrow-down.png"
/>
</li>
<li class="contact">意见反馈</li>
</ul>
</nav>
<main class="main">
<div class="bg"></div>
<div class="content">
<div class="core">
<h1>欢迎注册QQ</h1>
<div class="subtitle">
<h2>每一天,乐在沟通。</h2>
<a class="free-bright">免费靓号</a>
</div>
<form action="">
<input type="text" placeholder="昵称" />
<input class="password" type="password" placeholder="密码" />
<div class="mobile">
<select>
<option>+86</option>
<option>+852</option>
</select>
<input type="text" placeholder="手机号码" />
</div>
<p class="mobile-tip">可通过该手机号找回密码</p>
<button class="submit">立即注册</button>
<div class="agreement">
<input type="checkbox" />
<label>我已阅读并同意相关服务条款和隐私政策</label>
</div>
</form>
</div>
<footer>Copyright © 1998-2019Tencent All Rights Reserved</footer>
</div>
</main>
</body>
如果要获取subtitle这个节点,就要用到选择器查询方法querySelector()
需要传递一个字符串类型的selectors作为筛选条件,此处可以使用'.subtitle',如果页面中有很多'.subtitle'节点,那么我们需要加强搜索条件
//基础筛选条件
'.subtitle';
//加强版本,加上父亲筛选, 筛选 main标签下面 -> class为core的节点下面 -> class为subtitle的节点
'main .core .subtitle';
得到HTMLDivElement对象
- 迭代查询
当我们查询到subtitle元素后,可以借助这个元素继续筛选器内部的元素,比如我们想筛选器内部的a标签,可以用:
let subtitle = document.querySelector('main .core .subtitle');
console.log(subtitle.querySelector('a'));
得到一个HTMLAnchorElement节点
- 选择器全量查询
上述的方法只能查询一个满足条件的标签,如果想查询所有满足条件的标签,可以用querySelectorAll()
比如查询上面的所有input标签document.querySelectorAll('input');
返回一个类数组(类似数组)
- 其他筛选方法
querySelector和querySelectorAll是最新提出的方法,原生的DOM查询函数:
getElementById():根据ID查询某个节点
getElementsByClassName():根据class查询多个节点
getElementsByTagName():根据标签名查询多个节点
区别:querySelector查询出来的元素是拷贝的原始数据,不会再随着页面DOM节点的改变而变化,get系列方法查询的元素就是原始数据,所以会随着页面的DOM变化而变化
DOM属性
DOM种类
上个小节遇到的DOM种类
<!-- HTMLDocument 根文档 -->
<html>
……
</html>
<!-- HTMLDivElement DIV类型 -->
<div class="subtitle">
……
</div>
<!-- HTMLAnchorElement 超链接类型 -->
<a class="free-bright">免费靓号</a>
<!-- HTMLInputElement Input类型 -->
<input class="password" type="pasworkd" placeholder="请输入密码" />
每一种HTML标签都有一种DOM类型对应
DOM属性
- DOM类别
DOM种类可归纳为几个类别
-
元素节点
-
特性节点
-
文本节点
-
其他类别
三种节点的代表:html:
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<title>优课达</title>
</head>
<body>
<div id="test">优课达</div>
<script src="./index.js"></script>
</body>
js:
let divDom = document.querySelector('div#test');
console.log(divDom.nodeType, divDom.nodeName, divDom.nodeValue);
// 获取DIV节点的第一个儿子节点,代表 '优课达' 这个字符串
let txtDom = divDom.firstChild;
console.log(txtDom.nodeType, txtDom.nodeName, txtDom.nodeValue);
// 获取DIV节点的id属性
let attDom = divDom.attributes.id;
console.log(attDom.nodeType, attDom.nodeName, attDom.nodeValue);
对应的结果:
节点 nodeType nodeName nodeValue 类型
divDom 1 DIV null 元素节点
txtDom 2 #text 优课达 文本节点
attDom 3 id test 特性节点
.firstchild是获取节点的第一个儿子节点
通过.attributes可以获得标签的所有标签属性
- 总结特性:
-
整个HTML中,无论是标签,标签属性,还是纯文字字符串都是Element,不同的地方在于nodeType分别为1,2,3
-
HTML标签都是元素节点,可以用nodeName获得标签名称
-
纯文本都是文本标签,可以用nodeValue获得文本内容
-
标签的每个属性都是特性节点,可以用nodeName获得属性key,用nodeValue获得属性value
-
attributes可以获取标签的所有属性,得到的结果是一个字典,通过属性key可以获取对应的特性节点
DOM内容
html:
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<title>优课达</title>
</head>
<body>
<div id="test">
优课达
<p>youkeda</p>
<p>学的比别人好一点</p>
</div>
<script src="./index.js"></script>
</body>
js:
let divDom = document.querySelector('div#test');
console.log(divDom.outerHTML, divDom.innerHTML, divDom.innerText);
输出内容
outerHTML:
<div id="test">
优课达
<p>youkeda</p>
<p>学的比别人好一点</p>
</div>
innerHTML:
优课达
<p>youkeda</p>
<p>学的比别人好一点</p>
innerText:
优课达
总结:
outerHTML就是获取整个DOM的HTML代码;innerHTML就是获取DOM内部的HTML代码;innerText就是获取DOM内部的纯文本内容
DOM亲属
firstchild是获取指定节点的第一个子节点;
lastchild是获取指定节点的最后一个子节点;
childNodes是获取指定节点的子节点集合;
parentNode是获取指定节点的DOM树中的父节点
DOM样式
通过DOM,同样可以访问到其css特性
html:
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<title>优课达</title>
</head>
<body>
<h1 class="test youkeda" style="color: #FF3300; font-size: 24px;">优课达</h1>
<script src="./index.js"></script>
</body>
js:
const h1Dom = document.querySelector('h1');
console.log(h1Dom.classList);
console.log(h1Dom.style);
console.log(h1Dom.style.color);
总结:
classList就是数组方式存储所有的class名称,类型的DOMTokenList;style就是对象或字典的方式储存cssStyle,类型为CSSStyleDeclaration,且可用点运算符进一步访问各类型
DOM数据属性
网页设计的初衷就是使数据和特定的HTML标签相关联。而我们肉眼可见的只是内部纯文本
HTML提供一种数据属性的标准,利用data-*允许我们在标准内于HTML元素中存储额外的信息
比如:
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<title>优课达</title>
</head>
<body>
<article data-parts="3" data-words="1314" data-category="python">
...
</article>
<script src="./index.js"></script>
</body>
通过JS获取
const article = document.querySelector('article');
console.log(article.dataset);
dataset是Map对象,它是data-的的key-value集合
posted on 2022-04-27 21:13 RicardoSimple 阅读(191) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号